 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow useful is photo-realistic rendering for visual learning?
Paper and Code
Sep 08, 2016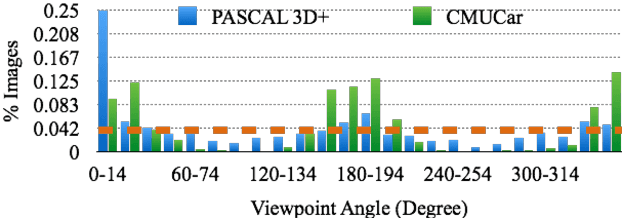
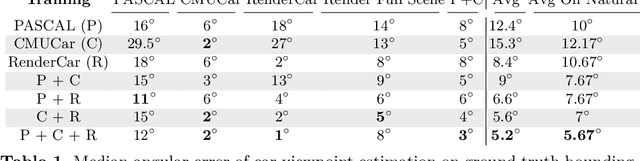


Data seems cheap to get, and in many ways it is, but the process of creating a high quality labeled dataset from a mass of data is time-consuming and expensive. With the advent of rich 3D repositories, photo-realistic rendering systems offer the opportunity to provide nearly limitless data. Yet, their primary value for visual learning may be the quality of the data they can provide rather than the quantity. Rendering engines offer the promise of perfect labels in addition to the data: what the precise camera pose is; what the precise lighting location, temperature, and distribution is; what the geometry of the object is. In this work we focus on semi-automating dataset creation through use of synthetic data and apply this method to an important task -- object viewpoint estimation. Using state-of-the-art rendering software we generate a large labeled dataset of cars rendered densely in viewpoint space. We investigate the effect of rendering parameters on estimation performance and show realism is important. We show that generalizing from synthetic data is not harder than the domain adaptation required between two real-image datasets and that combining synthetic images with a small amount of real data improves estimation accuracy.