 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiple Networks are More Efficient than One: Fast and Accurate Models via Ensembles and Cascades
Dec 03, 2020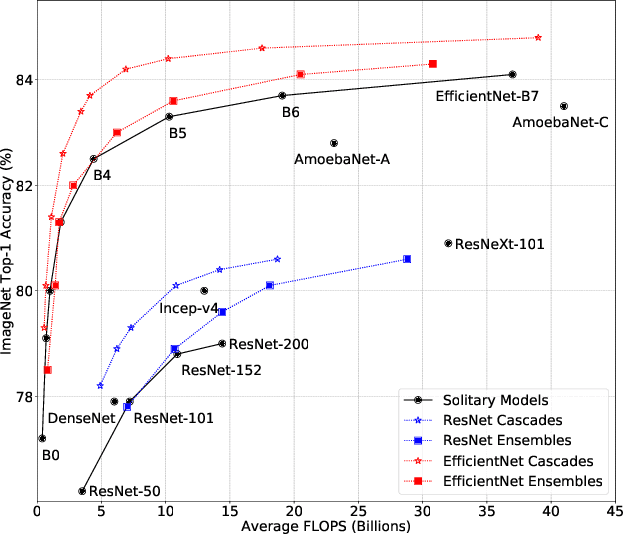
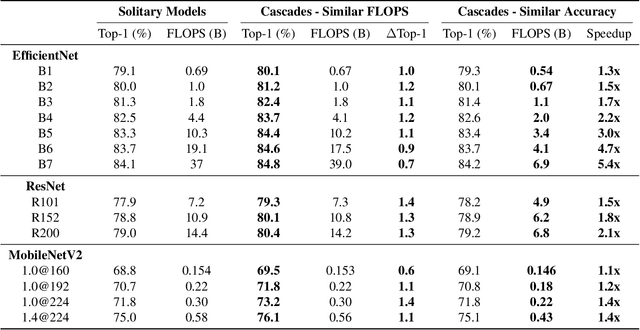
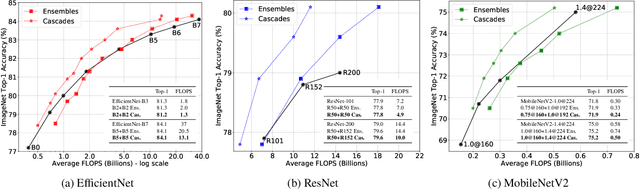
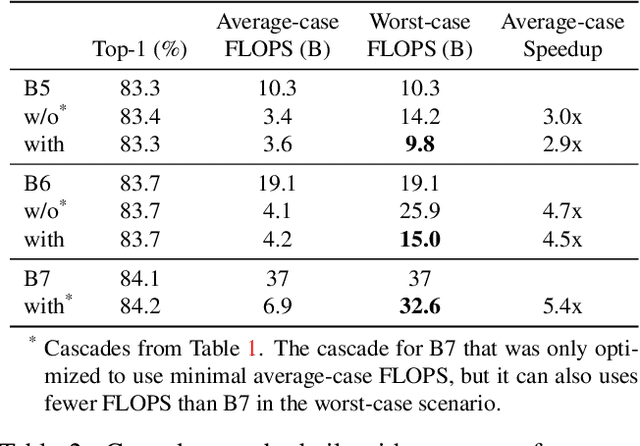
Recent work on efficient neural network architectures focuses on discovering a solitary network that can achieve superior computational efficiency and accuracy. While this paradigm has yielded impressive results, the search for novel architectures usually requires significant computational resources. In this work, we demonstrate a simple complementary paradigm to obtain efficient and accurate models that requires no architectural tuning. We show that committee-based models, i.e., ensembles or cascades of models, can easily obtain higher accuracy with less computation when compared to a single model. We extensively investigate the benefits of committee-based models on various vision tasks and architecture families. Our results suggest that in the large computation regime, model ensembles are a more cost-effective way to improve accuracy than using a large solitary model. We also find that the computational cost of an ensemble can be significantly reduced by converting them to cascades, while often retaining the original accuracy of the full ensemble.
Neighbourhood Distillation: On the benefits of non end-to-end distillation
Oct 08, 2020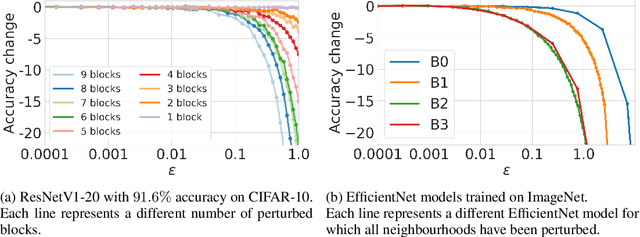
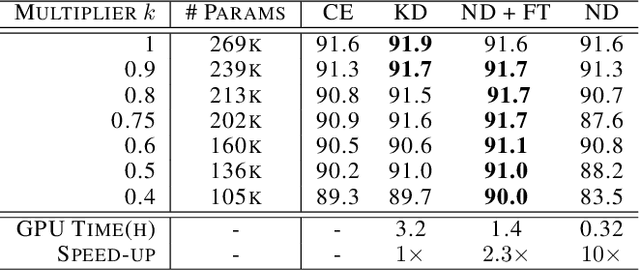
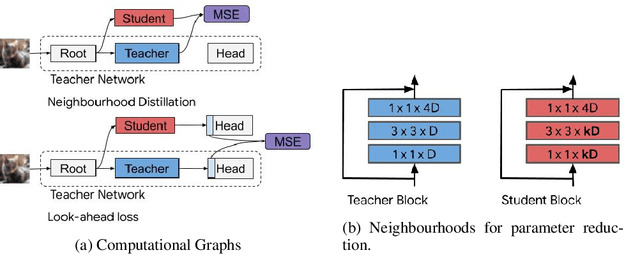
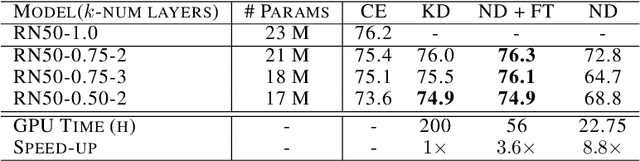
End-to-end training with back propagation is the standard method for training deep neural networks. However, as networks become deeper and bigger, end-to-end training becomes more challenging: highly non-convex models gets stuck easily in local optima, gradients signals are prone to vanish or explode during back-propagation, training requires computational resources and time. In this work, we propose to break away from the end-to-end paradigm in the context of Knowledge Distillation. Instead of distilling a model end-to-end, we propose to split it into smaller sub-networks - also called neighbourhoods - that are then trained independently. We empirically show that distilling networks in a non end-to-end fashion can be beneficial in a diverse range of use cases. First, we show that it speeds up Knowledge Distillation by exploiting parallelism and training on smaller networks. Second, we show that independently distilled neighbourhoods may be efficiently re-used for Neural Architecture Search. Finally, because smaller networks model simpler functions, we show that they are easier to train with synthetic data than their deeper counterparts.
Fine-Grained Stochastic Architecture Search
Jun 17, 2020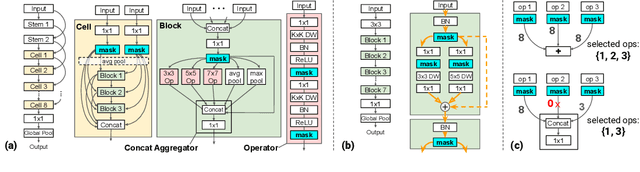
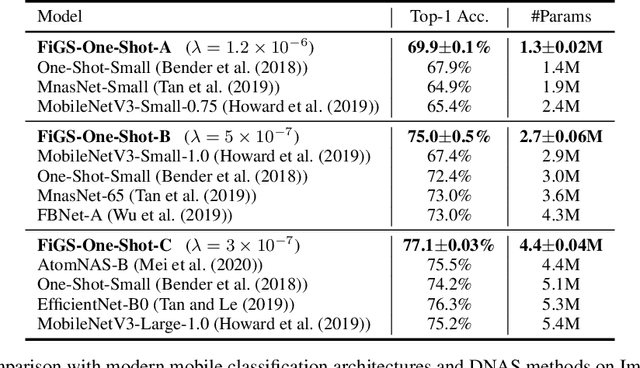
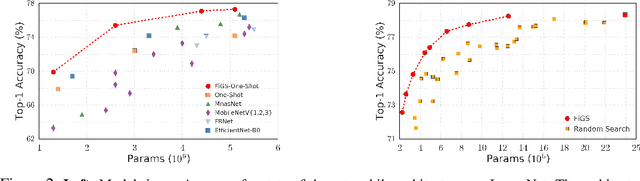

State-of-the-art deep networks are often too large to deploy on mobile devices and embedded systems. Mobile neural architecture search (NAS) methods automate the design of small models but state-of-the-art NAS methods are expensive to run. Differentiable neural architecture search (DNAS) methods reduce the search cost but explore a limited subspace of candidate architectures. In this paper, we introduce Fine-Grained Stochastic Architecture Search (FiGS), a differentiable search method that searches over a much larger set of candidate architectures. FiGS simultaneously selects and modifies operators in the search space by applying a structured sparse regularization penalty based on the Logistic-Sigmoid distribution. We show results across 3 existing search spaces, matching or outperforming the original search algorithms and producing state-of-the-art parameter-efficient models on ImageNet (e.g., 75.4% top-1 with 2.6M params). Using our architectures as backbones for object detection with SSDLite, we achieve significantly higher mAP on COCO (e.g., 25.8 with 3.0M params) than MobileNetV3 and MnasNet.
Sky Optimization: Semantically aware image processing of skies in low-light photography
Jun 15, 2020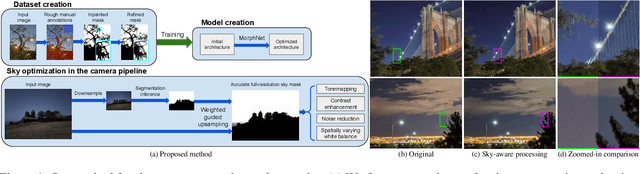

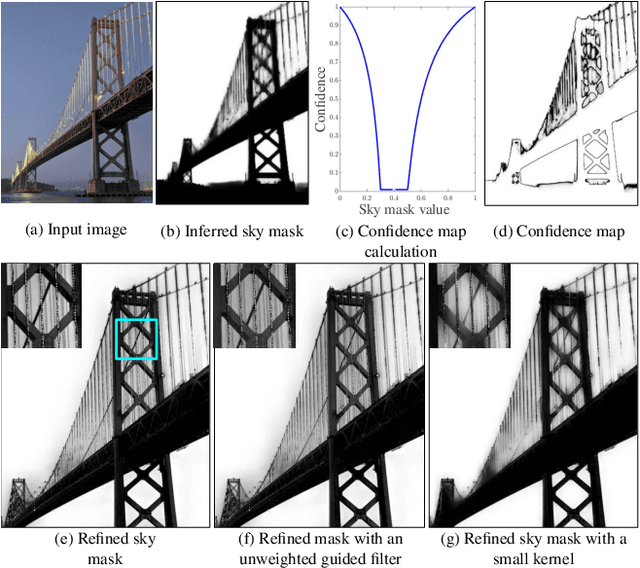
The sky is a major component of the appearance of a photograph, and its color and tone can strongly influence the mood of a picture. In nighttime photography, the sky can also suffer from noise and color artifacts. For this reason, there is a strong desire to process the sky in isolation from the rest of the scene to achieve an optimal look. In this work, we propose an automated method, which can run as a part of a camera pipeline, for creating accurate sky alpha-masks and using them to improve the appearance of the sky. Our method performs end-to-end sky optimization in less than half a second per image on a mobile device. We introduce a method for creating an accurate sky-mask dataset that is based on partially annotated images that are inpainted and refined by our modified weighted guided filter. We use this dataset to train a neural network for semantic sky segmentation. Due to the compute and power constraints of mobile devices, sky segmentation is performed at a low image resolution. Our modified weighted guided filter is used for edge-aware upsampling to resize the alpha-mask to a higher resolution. With this detailed mask we automatically apply post-processing steps to the sky in isolation, such as automatic spatially varying white-balance, brightness adjustments, contrast enhancement, and noise reduction.
Structured Multi-Hashing for Model Compression
Nov 25, 2019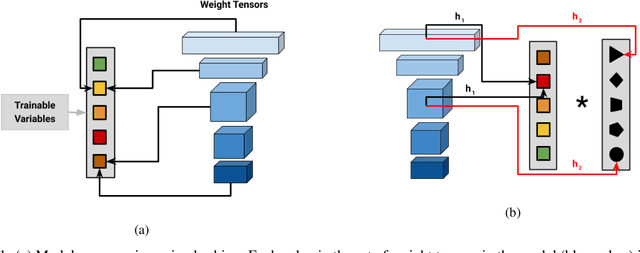
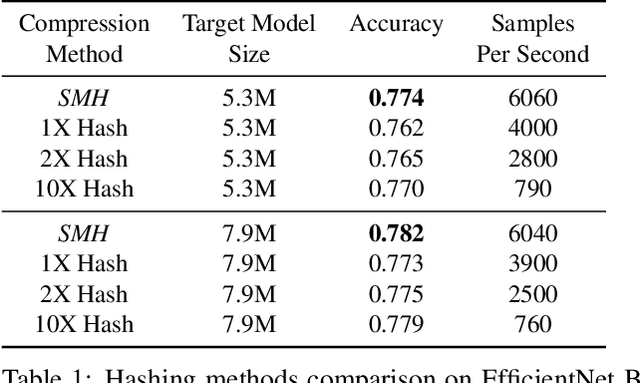
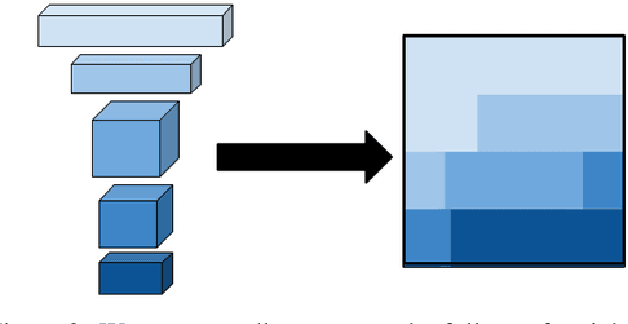
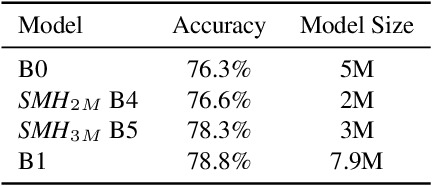
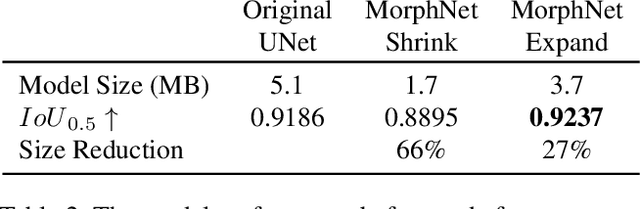
Despite the success of deep neural networks (DNNs), state-of-the-art models are too large to deploy on low-resource devices or common server configurations in which multiple models are held in memory. Model compression methods address this limitation by reducing the memory footprint, latency, or energy consumption of a model with minimal impact on accuracy. We focus on the task of reducing the number of learnable variables in the model. In this work we combine ideas from weight hashing and dimensionality reductions resulting in a simple and powerful structured multi-hashing method based on matrix products that allows direct control of model size of any deep network and is trained end-to-end. We demonstrate the strength of our approach by compressing models from the ResNet, EfficientNet, and MobileNet architecture families. Our method allows us to drastically decrease the number of variables while maintaining high accuracy. For instance, by applying our approach to EfficentNet-B4 (16M parameters) we reduce it to to the size of B0 (5M parameters), while gaining over 3% in accuracy over B0 baseline. On the commonly used benchmark CIFAR10 we reduce the ResNet32 model by 75% with no loss in quality, and are able to do a 10x compression while still achieving above 90% accuracy.
Synthetic Depth-of-Field with a Single-Camera Mobile Phone
Jun 11, 2018

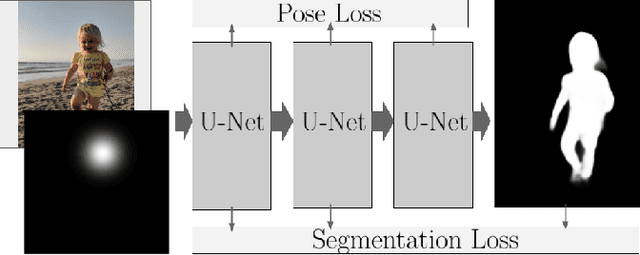
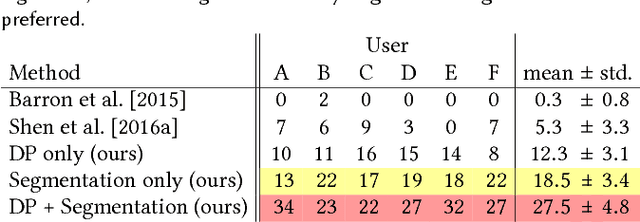
Shallow depth-of-field is commonly used by photographers to isolate a subject from a distracting background. However, standard cell phone cameras cannot produce such images optically, as their short focal lengths and small apertures capture nearly all-in-focus images. We present a system to computationally synthesize shallow depth-of-field images with a single mobile camera and a single button press. If the image is of a person, we use a person segmentation network to separate the person and their accessories from the background. If available, we also use dense dual-pixel auto-focus hardware, effectively a 2-sample light field with an approximately 1 millimeter baseline, to compute a dense depth map. These two signals are combined and used to render a defocused image. Our system can process a 5.4 megapixel image in 4 seconds on a mobile phone, is fully automatic, and is robust enough to be used by non-experts. The modular nature of our system allows it to degrade naturally in the absence of a dual-pixel sensor or a human subject.
No Fuss Distance Metric Learning using Proxies
Aug 01, 2017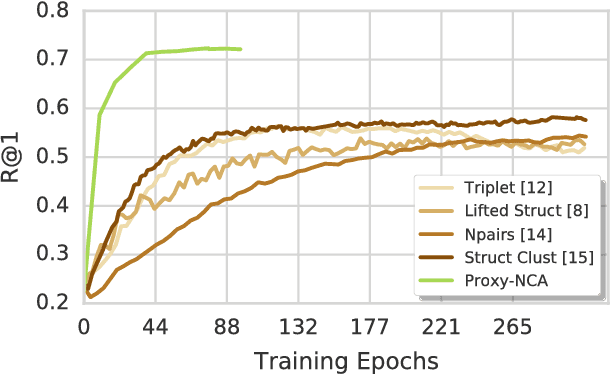
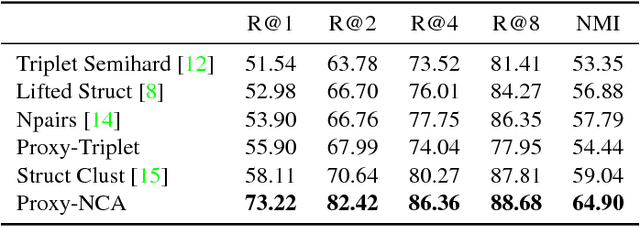
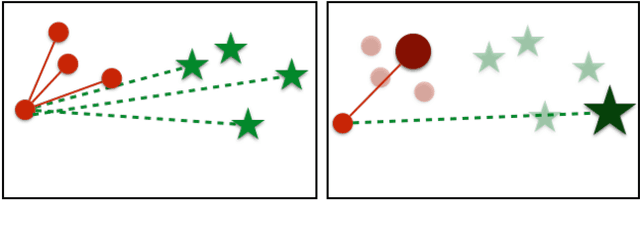
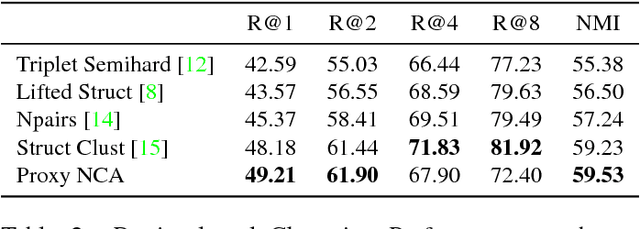
We address the problem of distance metric learning (DML), defined as learning a distance consistent with a notion of semantic similarity. Traditionally, for this problem supervision is expressed in the form of sets of points that follow an ordinal relationship -- an anchor point $x$ is similar to a set of positive points $Y$, and dissimilar to a set of negative points $Z$, and a loss defined over these distances is minimized. While the specifics of the optimization differ, in this work we collectively call this type of supervision Triplets and all methods that follow this pattern Triplet-Based methods. These methods are challenging to optimize. A main issue is the need for finding informative triplets, which is usually achieved by a variety of tricks such as increasing the batch size, hard or semi-hard triplet mining, etc. Even with these tricks, the convergence rate of such methods is slow. In this paper we propose to optimize the triplet loss on a different space of triplets, consisting of an anchor data point and similar and dissimilar proxy points which are learned as well. These proxies approximate the original data points, so that a triplet loss over the proxies is a tight upper bound of the original loss. This proxy-based loss is empirically better behaved. As a result, the proxy-loss improves on state-of-art results for three standard zero-shot learning datasets, by up to 15% points, while converging three times as fast as other triplet-based losses.
How useful is photo-realistic rendering for visual learning?
Sep 08, 2016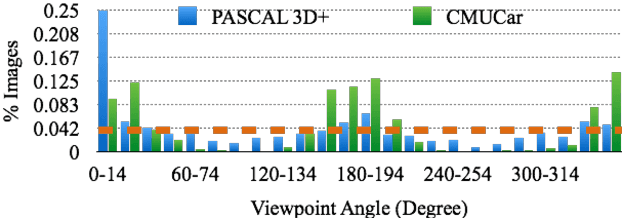
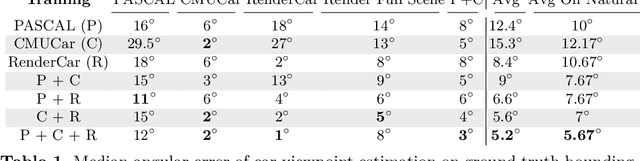


Data seems cheap to get, and in many ways it is, but the process of creating a high quality labeled dataset from a mass of data is time-consuming and expensive. With the advent of rich 3D repositories, photo-realistic rendering systems offer the opportunity to provide nearly limitless data. Yet, their primary value for visual learning may be the quality of the data they can provide rather than the quantity. Rendering engines offer the promise of perfect labels in addition to the data: what the precise camera pose is; what the precise lighting location, temperature, and distribution is; what the geometry of the object is. In this work we focus on semi-automating dataset creation through use of synthetic data and apply this method to an important task -- object viewpoint estimation. Using state-of-the-art rendering software we generate a large labeled dataset of cars rendered densely in viewpoint space. We investigate the effect of rendering parameters on estimation performance and show realism is important. We show that generalizing from synthetic data is not harder than the domain adaptation required between two real-image datasets and that combining synthetic images with a small amount of real data improves estimation accuracy.