 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiple Networks are More Efficient than One: Fast and Accurate Models via Ensembles and Cascades
Dec 03, 2020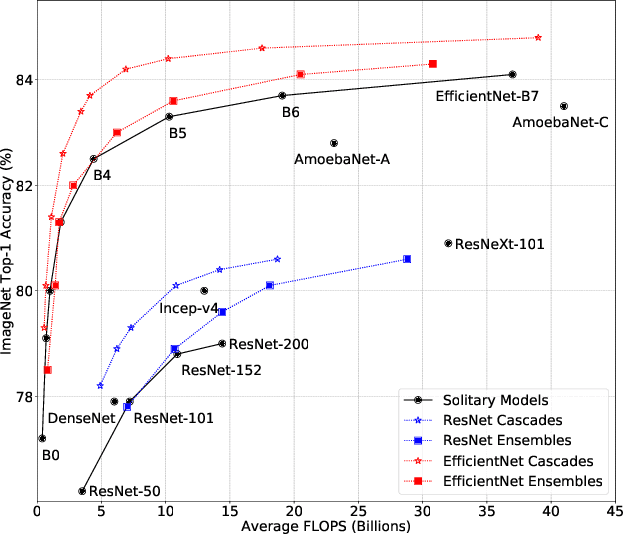
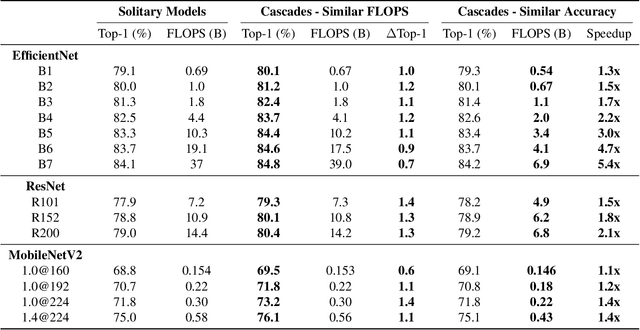
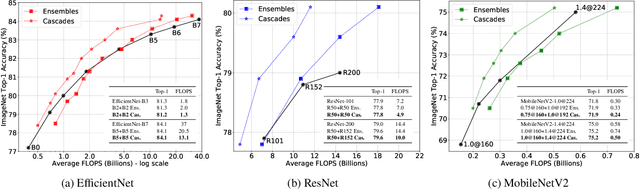
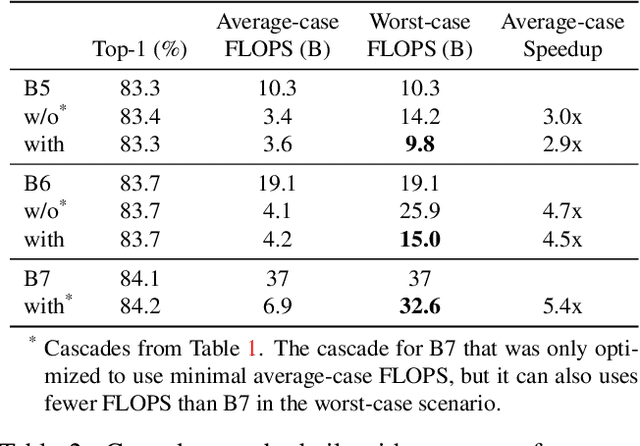
Recent work on efficient neural network architectures focuses on discovering a solitary network that can achieve superior computational efficiency and accuracy. While this paradigm has yielded impressive results, the search for novel architectures usually requires significant computational resources. In this work, we demonstrate a simple complementary paradigm to obtain efficient and accurate models that requires no architectural tuning. We show that committee-based models, i.e., ensembles or cascades of models, can easily obtain higher accuracy with less computation when compared to a single model. We extensively investigate the benefits of committee-based models on various vision tasks and architecture families. Our results suggest that in the large computation regime, model ensembles are a more cost-effective way to improve accuracy than using a large solitary model. We also find that the computational cost of an ensemble can be significantly reduced by converting them to cascades, while often retaining the original accuracy of the full ensemble.
Neighbourhood Distillation: On the benefits of non end-to-end distillation
Oct 08, 2020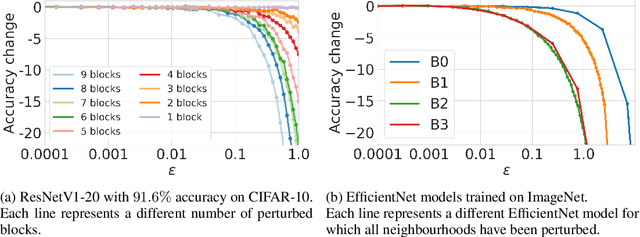
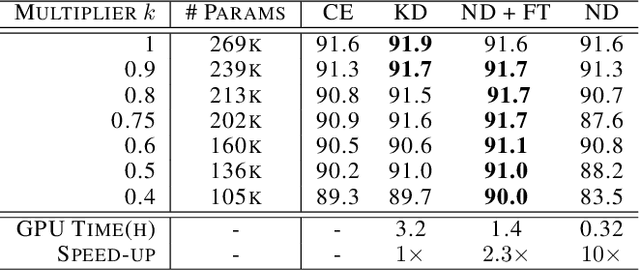
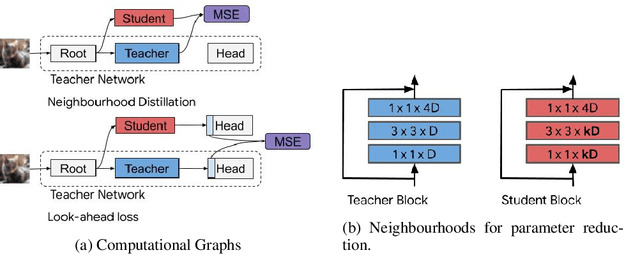
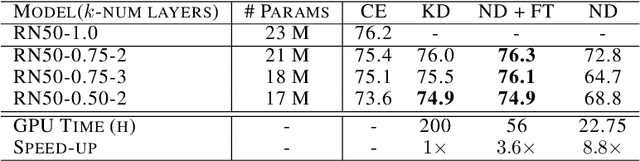
End-to-end training with back propagation is the standard method for training deep neural networks. However, as networks become deeper and bigger, end-to-end training becomes more challenging: highly non-convex models gets stuck easily in local optima, gradients signals are prone to vanish or explode during back-propagation, training requires computational resources and time. In this work, we propose to break away from the end-to-end paradigm in the context of Knowledge Distillation. Instead of distilling a model end-to-end, we propose to split it into smaller sub-networks - also called neighbourhoods - that are then trained independently. We empirically show that distilling networks in a non end-to-end fashion can be beneficial in a diverse range of use cases. First, we show that it speeds up Knowledge Distillation by exploiting parallelism and training on smaller networks. Second, we show that independently distilled neighbourhoods may be efficiently re-used for Neural Architecture Search. Finally, because smaller networks model simpler functions, we show that they are easier to train with synthetic data than their deeper counterparts.
Fine-Grained Stochastic Architecture Search
Jun 17, 2020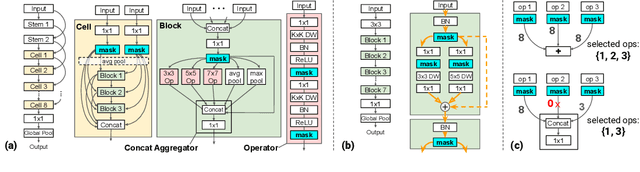
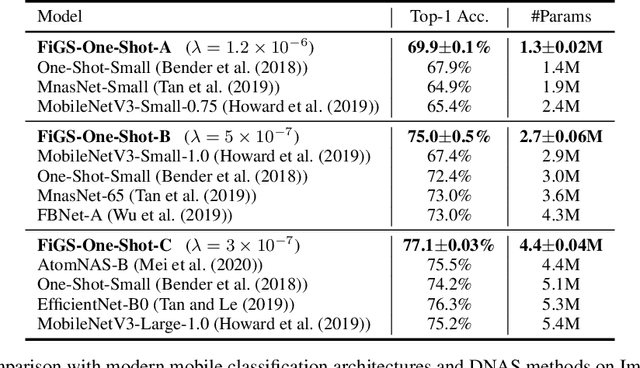
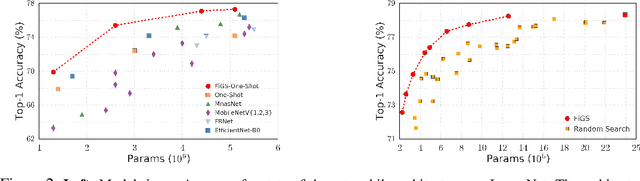

State-of-the-art deep networks are often too large to deploy on mobile devices and embedded systems. Mobile neural architecture search (NAS) methods automate the design of small models but state-of-the-art NAS methods are expensive to run. Differentiable neural architecture search (DNAS) methods reduce the search cost but explore a limited subspace of candidate architectures. In this paper, we introduce Fine-Grained Stochastic Architecture Search (FiGS), a differentiable search method that searches over a much larger set of candidate architectures. FiGS simultaneously selects and modifies operators in the search space by applying a structured sparse regularization penalty based on the Logistic-Sigmoid distribution. We show results across 3 existing search spaces, matching or outperforming the original search algorithms and producing state-of-the-art parameter-efficient models on ImageNet (e.g., 75.4% top-1 with 2.6M params). Using our architectures as backbones for object detection with SSDLite, we achieve significantly higher mAP on COCO (e.g., 25.8 with 3.0M params) than MobileNetV3 and MnasNet.
Sky Optimization: Semantically aware image processing of skies in low-light photography
Jun 15, 2020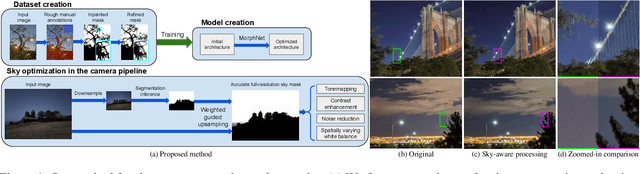

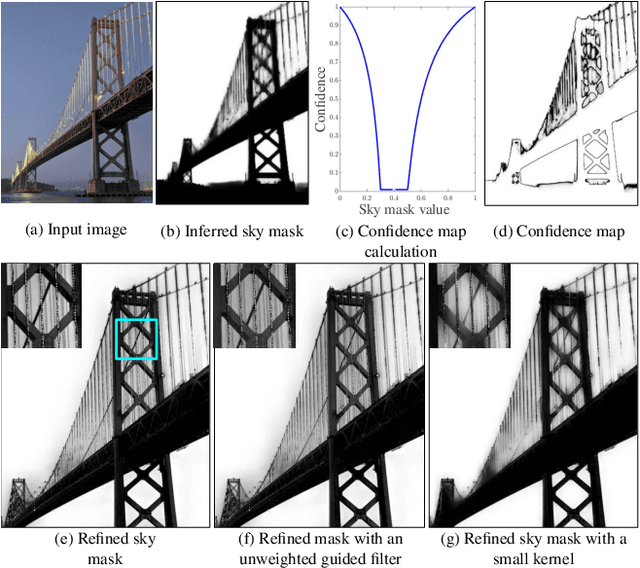
The sky is a major component of the appearance of a photograph, and its color and tone can strongly influence the mood of a picture. In nighttime photography, the sky can also suffer from noise and color artifacts. For this reason, there is a strong desire to process the sky in isolation from the rest of the scene to achieve an optimal look. In this work, we propose an automated method, which can run as a part of a camera pipeline, for creating accurate sky alpha-masks and using them to improve the appearance of the sky. Our method performs end-to-end sky optimization in less than half a second per image on a mobile device. We introduce a method for creating an accurate sky-mask dataset that is based on partially annotated images that are inpainted and refined by our modified weighted guided filter. We use this dataset to train a neural network for semantic sky segmentation. Due to the compute and power constraints of mobile devices, sky segmentation is performed at a low image resolution. Our modified weighted guided filter is used for edge-aware upsampling to resize the alpha-mask to a higher resolution. With this detailed mask we automatically apply post-processing steps to the sky in isolation, such as automatic spatially varying white-balance, brightness adjustments, contrast enhancement, and noise reduction.
Computationally Efficient Neural Image Compression
Dec 18, 2019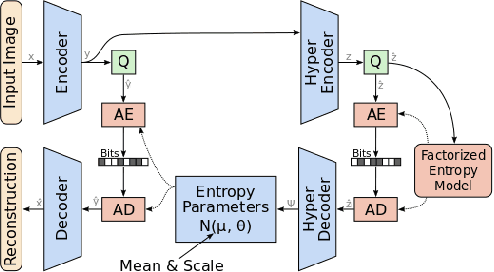


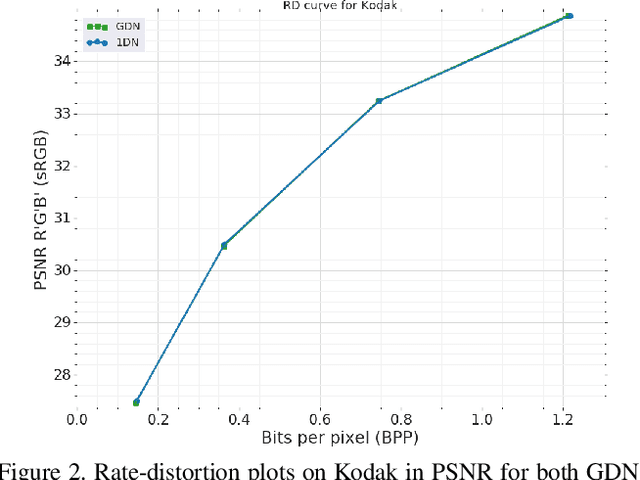
Image compression using neural networks have reached or exceeded non-neural methods (such as JPEG, WebP, BPG). While these networks are state of the art in ratedistortion performance, computational feasibility of these models remains a challenge. We apply automatic network optimization techniques to reduce the computational complexity of a popular architecture used in neural image compression, analyze the decoder complexity in execution runtime and explore the trade-offs between two distortion metrics, rate-distortion performance and run-time performance to design and research more computationally efficient neural image compression. We find that our method decreases the decoder run-time requirements by over 50% for a stateof-the-art neural architecture.
Structured Multi-Hashing for Model Compression
Nov 25, 2019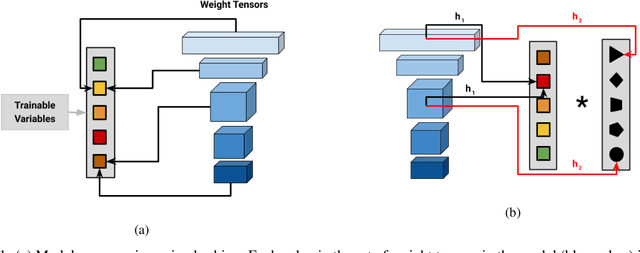
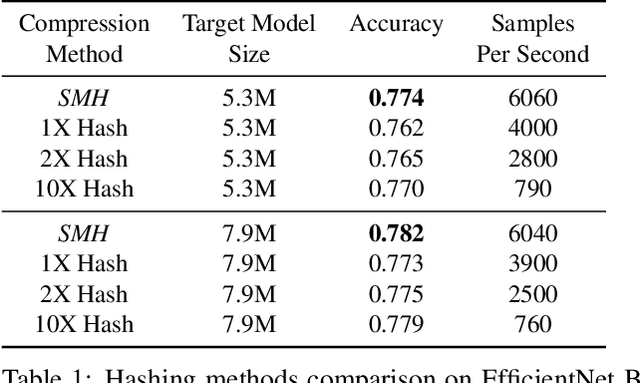
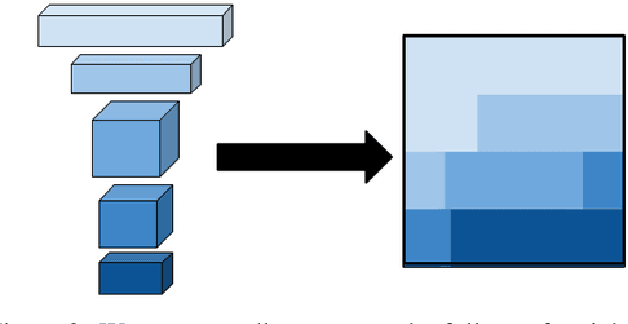
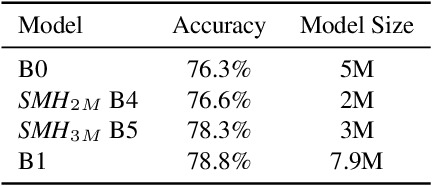
Despite the success of deep neural networks (DNNs), state-of-the-art models are too large to deploy on low-resource devices or common server configurations in which multiple models are held in memory. Model compression methods address this limitation by reducing the memory footprint, latency, or energy consumption of a model with minimal impact on accuracy. We focus on the task of reducing the number of learnable variables in the model. In this work we combine ideas from weight hashing and dimensionality reductions resulting in a simple and powerful structured multi-hashing method based on matrix products that allows direct control of model size of any deep network and is trained end-to-end. We demonstrate the strength of our approach by compressing models from the ResNet, EfficientNet, and MobileNet architecture families. Our method allows us to drastically decrease the number of variables while maintaining high accuracy. For instance, by applying our approach to EfficentNet-B4 (16M parameters) we reduce it to to the size of B0 (5M parameters), while gaining over 3% in accuracy over B0 baseline. On the commonly used benchmark CIFAR10 we reduce the ResNet32 model by 75% with no loss in quality, and are able to do a 10x compression while still achieving above 90% accuracy.
Seq2Slate: Re-ranking and Slate Optimization with RNNs
Oct 04, 2018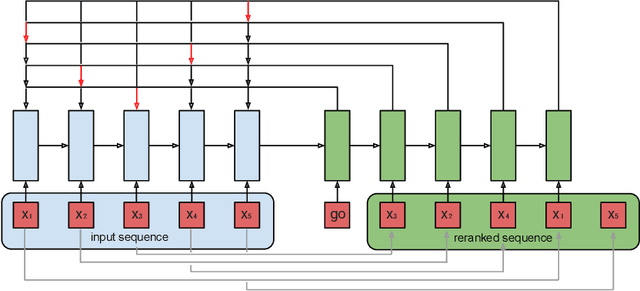
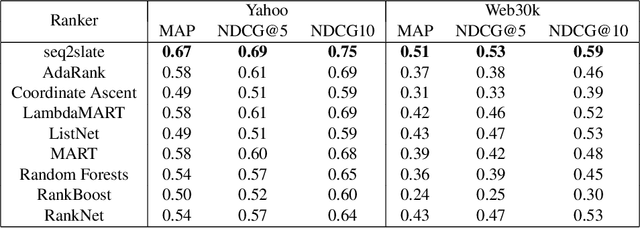

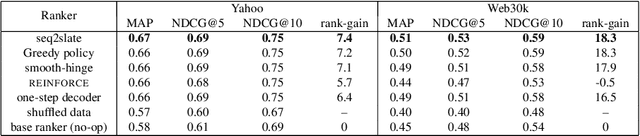
Ranking is a central task in machine learning and information retrieval. In this task, it is especially important to present the user with a slate of items that is appealing as a whole. This in turn requires taking into account interactions between items, since intuitively, placing an item on the slate affects the decision of which other items should be placed alongside it. In this work, we propose a sequence-to-sequence model for ranking called seq2slate. At each step, the model predicts the next item to place on the slate given the items already selected. The recurrent nature of the model allows complex dependencies between items to be captured directly in a flexible and scalable way. We show how to learn the model end-to-end from weak supervision in the form of easily obtained click-through data. We further demonstrate the usefulness of our approach in experiments on standard ranking benchmarks as well as in a real-world recommendation system.
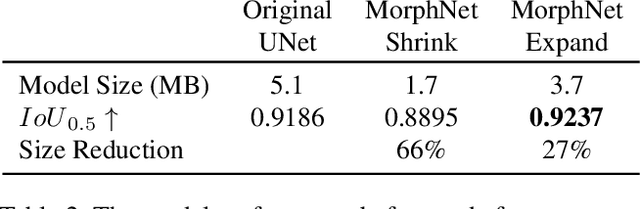
MorphNet: Fast & Simple Resource-Constrained Structure Learning of Deep Networks
Apr 17, 2018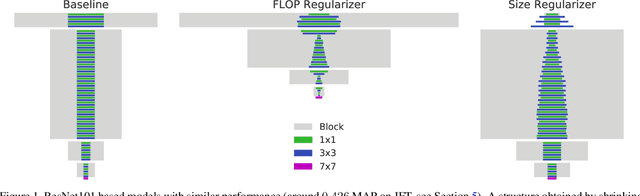
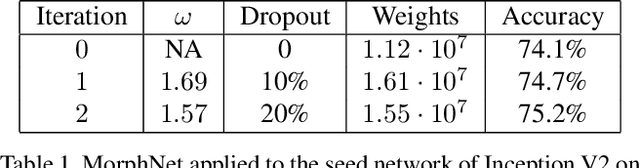
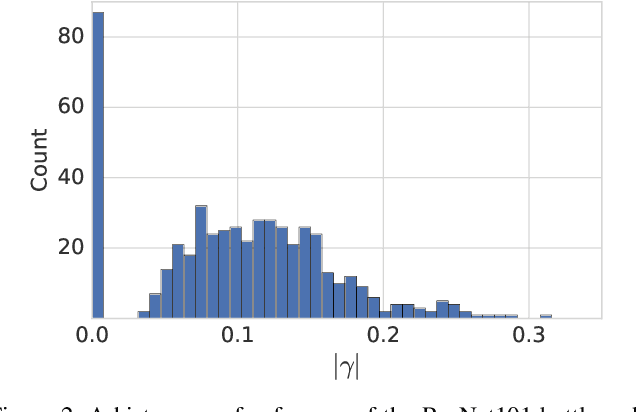
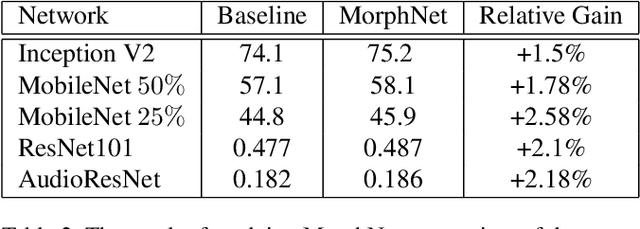
We present MorphNet, an approach to automate the design of neural network structures. MorphNet iteratively shrinks and expands a network, shrinking via a resource-weighted sparsifying regularizer on activations and expanding via a uniform multiplicative factor on all layers. In contrast to previous approaches, our method is scalable to large networks, adaptable to specific resource constraints (e.g. the number of floating-point operations per inference), and capable of increasing the network's performance. When applied to standard network architectures on a wide variety of datasets, our approach discovers novel structures in each domain, obtaining higher performance while respecting the resource constraint.
Constrained Classification and Ranking via Quantiles
Feb 28, 2018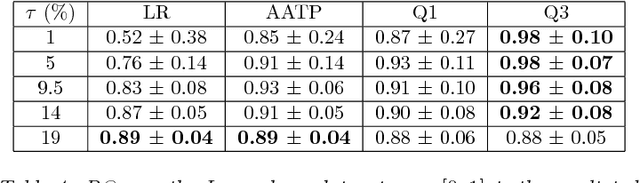
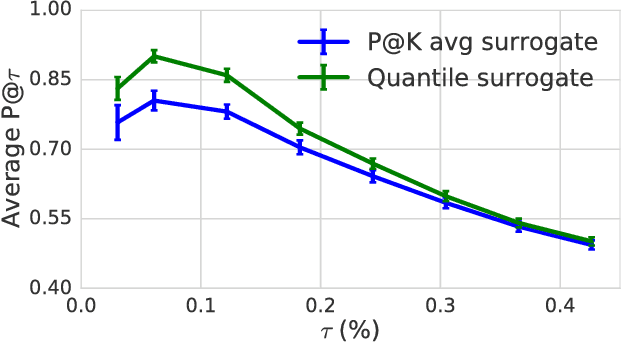
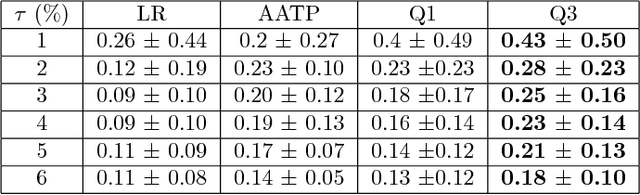
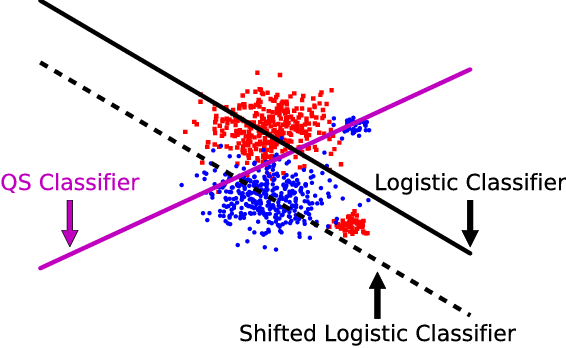
In most machine learning applications, classification accuracy is not the primary metric of interest. Binary classifiers which face class imbalance are often evaluated by the $F_\beta$ score, area under the precision-recall curve, Precision at K, and more. The maximization of many of these metrics can be expressed as a constrained optimization problem, where the constraint is a function of the classifier's predictions. In this paper we propose a novel framework for learning with constraints that can be expressed as a predicted positive rate (or negative rate) on a subset of the training data. We explicitly model the threshold at which a classifier must operate to satisfy the constraint, yielding a surrogate loss function which avoids the complexity of constrained optimization. The method is model-agnostic and only marginally more expensive than minimization of the unconstrained loss. Experiments on a variety of benchmarks show competitive performance relative to existing baselines.
Learning Max-Margin Tree Predictors
Sep 26, 2013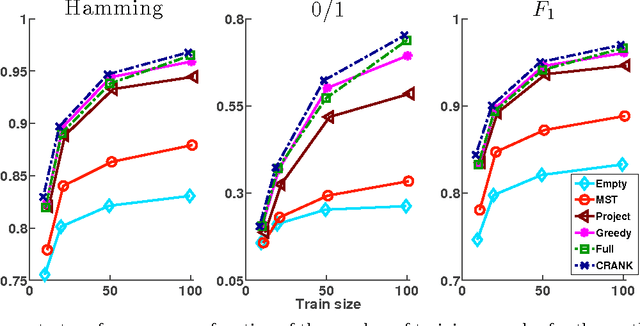
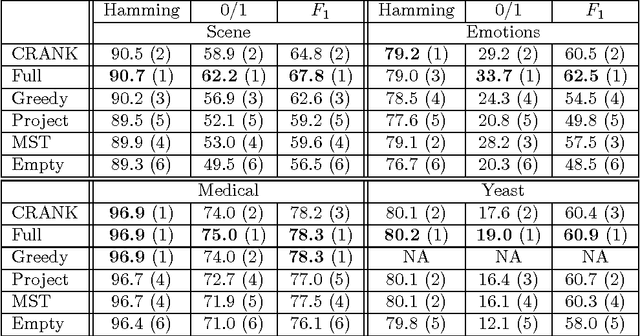
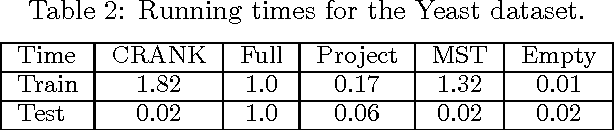
Structured prediction is a powerful framework for coping with joint prediction of interacting outputs. A central difficulty in using this framework is that often the correct label dependence structure is unknown. At the same time, we would like to avoid an overly complex structure that will lead to intractable prediction. In this work we address the challenge of learning tree structured predictive models that achieve high accuracy while at the same time facilitate efficient (linear time) inference. We start by proving that this task is in general NP-hard, and then suggest an approximate alternative. Briefly, our CRANK approach relies on a novel Circuit-RANK regularizer that penalizes non-tree structures and that can be optimized using a CCCP procedure. We demonstrate the effectiveness of our approach on several domains and show that, despite the relative simplicity of the structure, prediction accuracy is competitive with a fully connected model that is computationally costly at prediction time.