 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-Adversarial Inverse Reinforcement Learning for Decision-making Tasks
Mar 25, 2021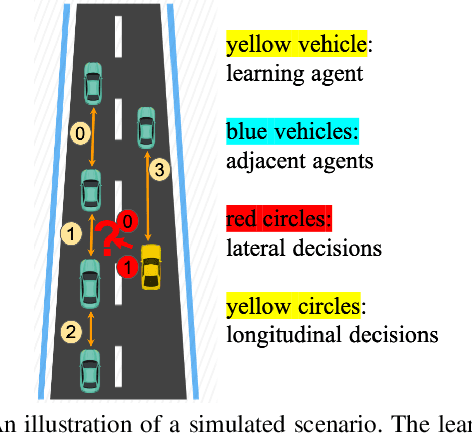
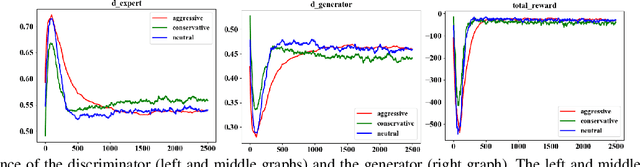
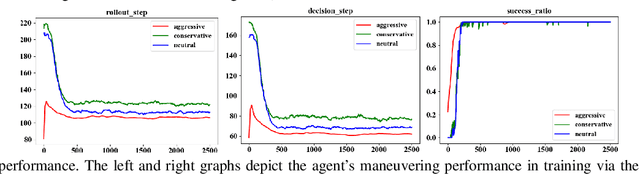
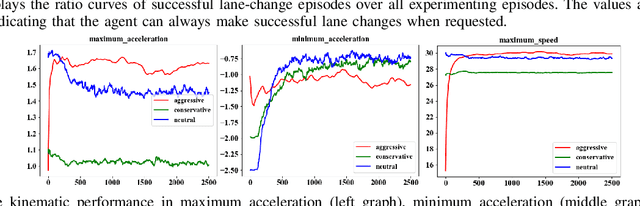
Learning from demonstrations has made great progress over the past few years. However, it is generally data hungry and task specific. In other words, it requires a large amount of data to train a decent model on a particular task, and the model often fails to generalize to new tasks that have a different distribution. In practice, demonstrations from new tasks will be continuously observed and the data might be unlabeled or only partially labeled. Therefore, it is desirable for the trained model to adapt to new tasks that have limited data samples available. In this work, we build an adaptable imitation learning model based on the integration of Meta-learning and Adversarial Inverse Reinforcement Learning (Meta-AIRL). We exploit the adversarial learning and inverse reinforcement learning mechanisms to learn policies and reward functions simultaneously from available training tasks and then adapt them to new tasks with the meta-learning framework. Simulation results show that the adapted policy trained with Meta-AIRL can effectively learn from limited number of demonstrations, and quickly reach the performance comparable to that of the experts on unseen tasks.
Unsupervised Monocular Depth Learning in Dynamic Scenes
Nov 07, 2020


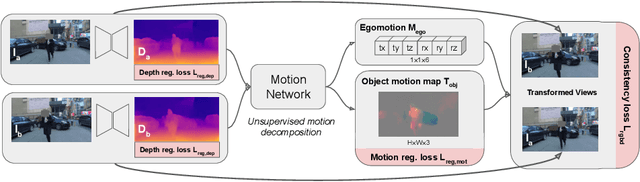
We present a method for jointly training the estimation of depth, ego-motion, and a dense 3D translation field of objects relative to the scene, with monocular photometric consistency being the sole source of supervision. We show that this apparently heavily underdetermined problem can be regularized by imposing the following prior knowledge about 3D translation fields: they are sparse, since most of the scene is static, and they tend to be constant for rigid moving objects. We show that this regularization alone is sufficient to train monocular depth prediction models that exceed the accuracy achieved in prior work for dynamic scenes, including methods that require semantic input. Code is at https://github.com/google-research/google-research/tree/master/depth_and_motion_learning .
Fine-Grained Stochastic Architecture Search
Jun 17, 2020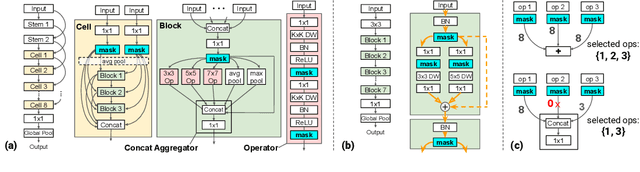
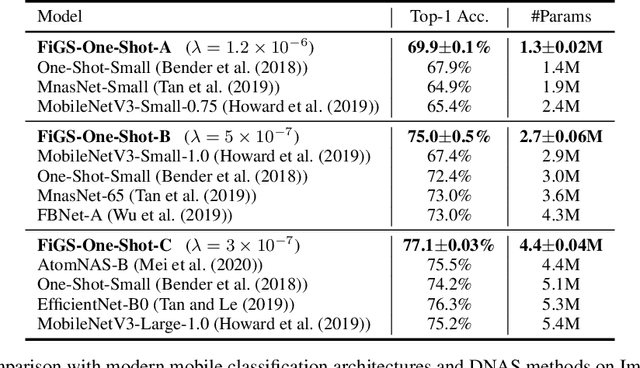
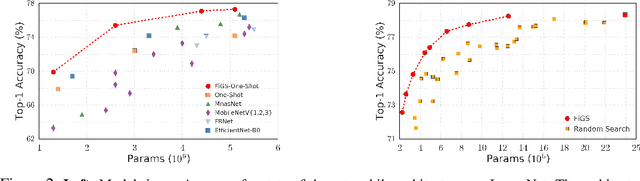

State-of-the-art deep networks are often too large to deploy on mobile devices and embedded systems. Mobile neural architecture search (NAS) methods automate the design of small models but state-of-the-art NAS methods are expensive to run. Differentiable neural architecture search (DNAS) methods reduce the search cost but explore a limited subspace of candidate architectures. In this paper, we introduce Fine-Grained Stochastic Architecture Search (FiGS), a differentiable search method that searches over a much larger set of candidate architectures. FiGS simultaneously selects and modifies operators in the search space by applying a structured sparse regularization penalty based on the Logistic-Sigmoid distribution. We show results across 3 existing search spaces, matching or outperforming the original search algorithms and producing state-of-the-art parameter-efficient models on ImageNet (e.g., 75.4% top-1 with 2.6M params). Using our architectures as backbones for object detection with SSDLite, we achieve significantly higher mAP on COCO (e.g., 25.8 with 3.0M params) than MobileNetV3 and MnasNet.
Adversarially Robust Frame Sampling with Bounded Irregularities
Feb 04, 2020
In recent years, video analysis tools for automatically extracting meaningful information from videos are widely studied and deployed. Because most of them use deep neural networks which are computationally expensive, feeding only a subset of video frames into such algorithms is desired. Sampling the frames with fixed rate is always attractive for its simplicity, representativeness, and interpretability. For example, a popular cloud video API generated video and shot labels by processing only the first frame of every second in a video. However, one can easily attack such strategies by placing chosen frames at the sampled locations. In this paper, we present an elegant solution to this sampling problem that is provably robust against adversarial attacks and introduces bounded irregularities as well.
Quadratic Q-network for Learning Continuous Control for Autonomous Vehicles
Nov 29, 2019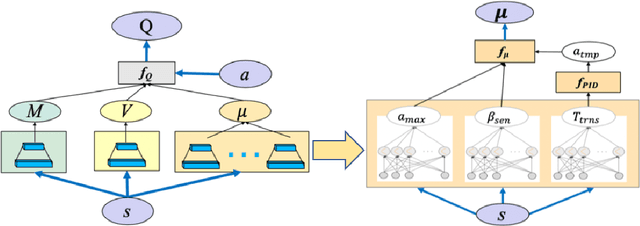

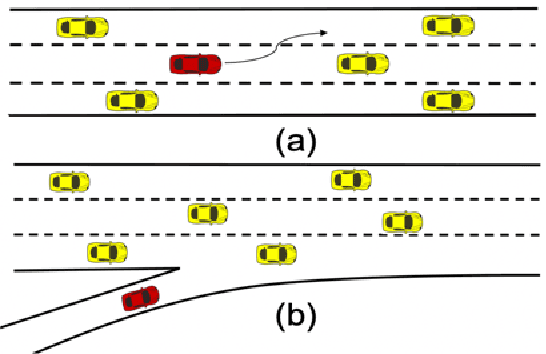

Reinforcement Learning algorithms have recently been proposed to learn time-sequential control policies in the field of autonomous driving. Direct applications of Reinforcement Learning algorithms with discrete action space will yield unsatisfactory results at the operational level of driving where continuous control actions are actually required. In addition, the design of neural networks often fails to incorporate the domain knowledge of the targeting problem such as the classical control theories in our case. In this paper, we propose a hybrid model by combining Q-learning and classic PID (Proportion Integration Differentiation) controller for handling continuous vehicle control problems under dynamic driving environment. Particularly, instead of using a big neural network as Q-function approximation, we design a Quadratic Q-function over actions with multiple simple neural networks for finding optimal values within a continuous space. We also build an action network based on the domain knowledge of the control mechanism of a PID controller to guide the agent to explore optimal actions more efficiently.We test our proposed approach in simulation under two common but challenging driving situations, the lane change scenario and ramp merge scenario. Results show that the autonomous vehicle agent can successfully learn a smooth and efficient driving behavior in both situations.
Continuous Control for Automated Lane Change Behavior Based on Deep Deterministic Policy Gradient Algorithm
Jun 05, 2019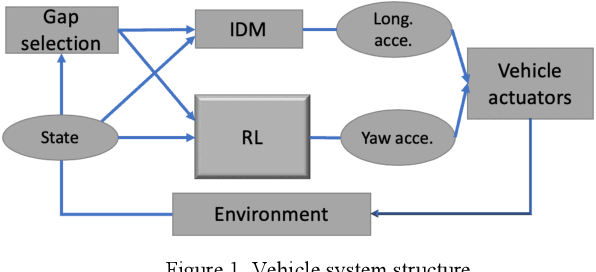
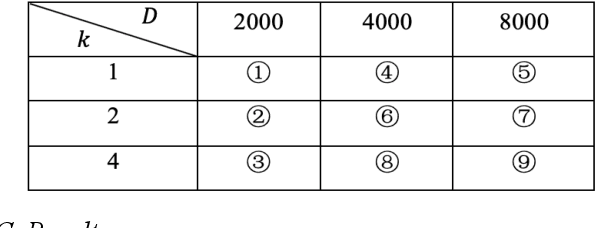
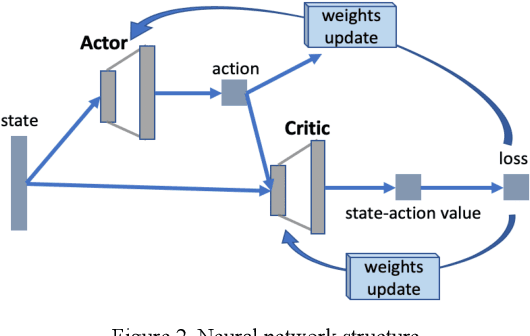
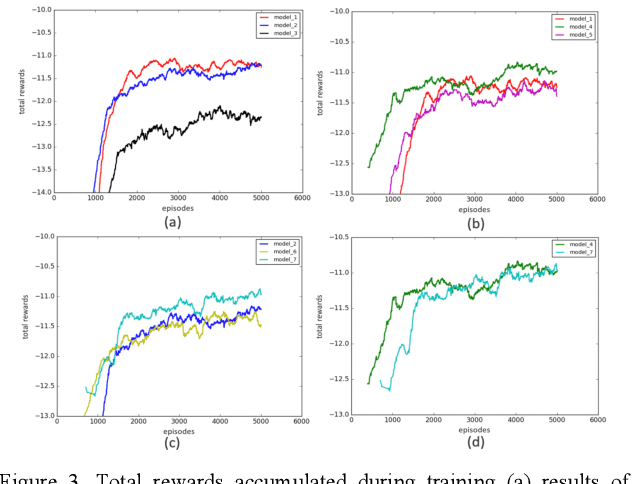
Lane change is a challenging task which requires delicate actions to ensure safety and comfort. Some recent studies have attempted to solve the lane-change control problem with Reinforcement Learning (RL), yet the action is confined to discrete action space. To overcome this limitation, we formulate the lane change behavior with continuous action in a model-free dynamic driving environment based on Deep Deterministic Policy Gradient (DDPG). The reward function, which is critical for learning the optimal policy, is defined by control values, position deviation status, and maneuvering time to provide the RL agent informative signals. The RL agent is trained from scratch without resorting to any prior knowledge of the environment and vehicle dynamics since they are not easy to obtain. Seven models under different hyperparameter settings are compared. A video showing the learning progress of the driving behavior is available. It demonstrates the RL vehicle agent initially runs out of road boundary frequently, but eventually has managed to smoothly and stably change to the target lane with a success rate of 100% under diverse driving situations in simulation.
EnsembleNet: End-to-End Optimization of Multi-headed Models
May 24, 2019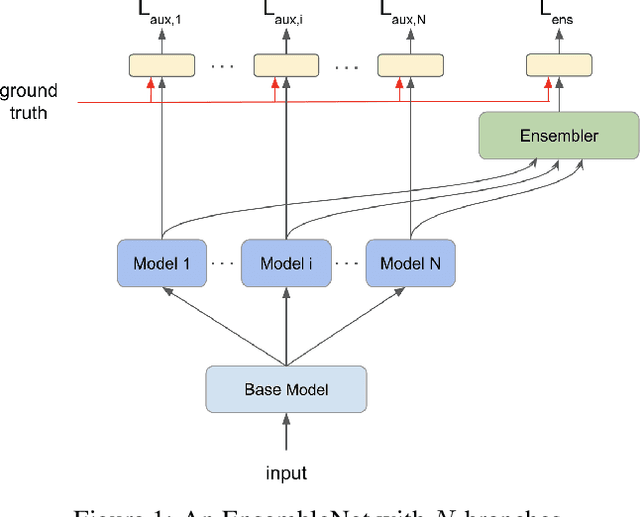
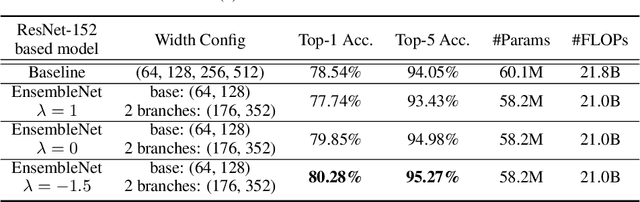
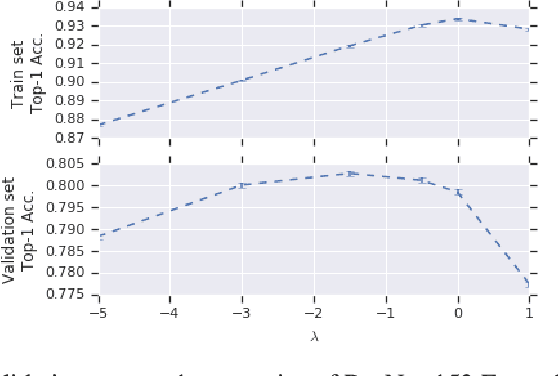
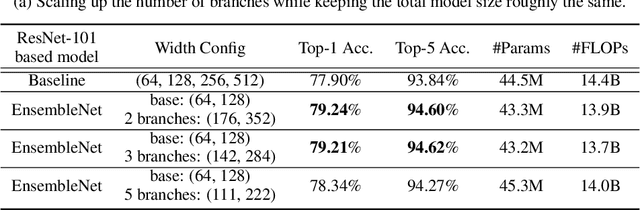
Ensembling is a universally useful approach to boost the performance of machine learning models. However, individual models in an ensemble are typically trained independently in separate stages, without information access about the overall ensemble. In this paper, model ensembles are treated as first-class citizens, and their performance is optimized end-to-end with parameter sharing and a novel loss structure that improves generalization. On large-scale datasets including ImageNet, Youtube-8M, and Kinetics, we demonstrate a procedure that starts from a strongly performing single deep neural network, and constructs an EnsembleNet that has both a smaller size and better performance. Moreover, an EnsembleNet can be trained in one stage just like a single model without manual intervention.
Depth from Videos in the Wild: Unsupervised Monocular Depth Learning from Unknown Cameras
Apr 10, 2019
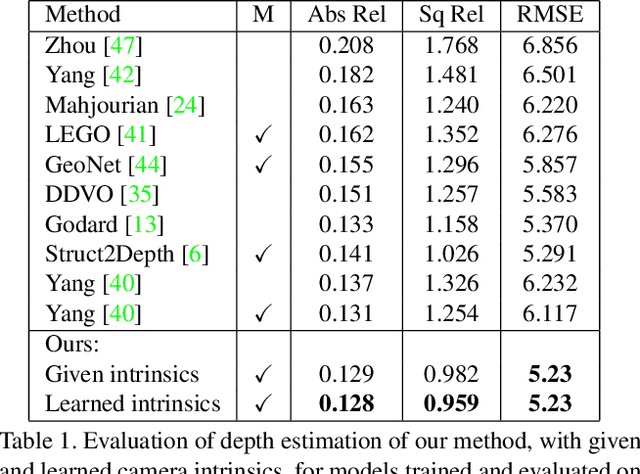
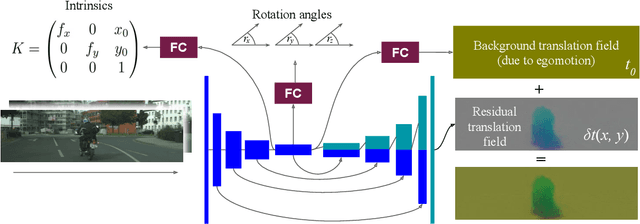
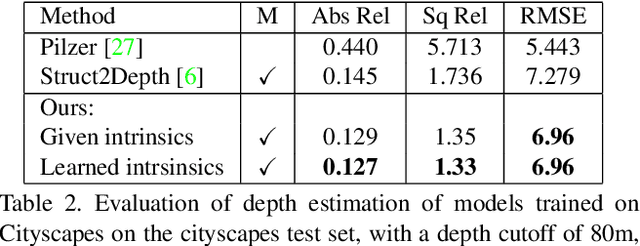
We present a novel method for simultaneous learning of depth, egomotion, object motion, and camera intrinsics from monocular videos, using only consistency across neighboring video frames as supervision signal. Similarly to prior work, our method learns by applying differentiable warping to frames and comparing the result to adjacent ones, but it provides several improvements: We address occlusions geometrically and differentiably, directly using the depth maps as predicted during training. We introduce randomized layer normalization, a novel powerful regularizer, and we account for object motion relative to the scene. To the best of our knowledge, our work is the first to learn the camera intrinsic parameters, including lens distortion, from video in an unsupervised manner, thereby allowing us to extract accurate depth and motion from arbitrary videos of unknown origin at scale. We evaluate our results on the Cityscapes, KITTI and EuRoC datasets, establishing new state of the art on depth prediction and odometry, and demonstrate qualitatively that depth prediction can be learned from a collection of YouTube videos.
Automated Driving Maneuvers under Interactive Environment based on Deep Reinforcement Learning
Jan 24, 2019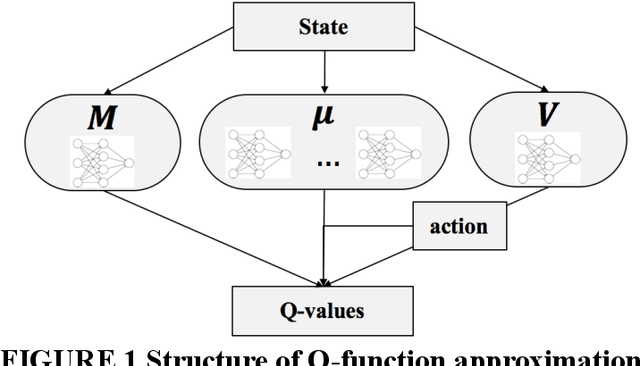
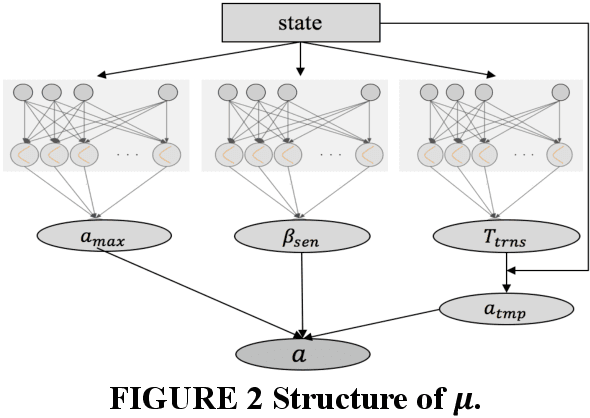
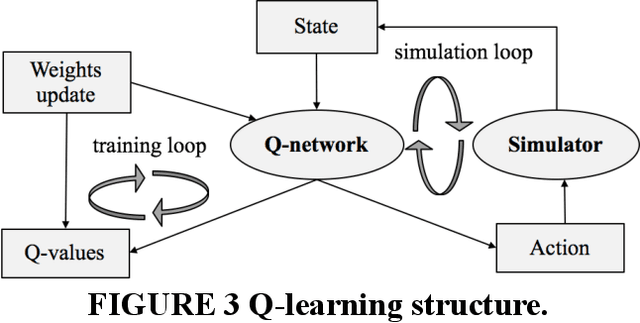
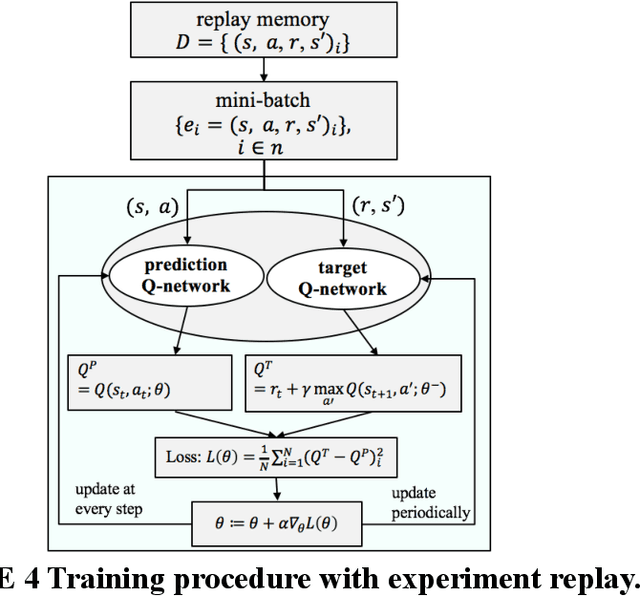
Safe and efficient autonomous driving maneuvers in an interactive and complex environment can be considerably challenging due to the unpredictable actions of other surrounding agents that may be cooperative or adversarial in their interactions with the ego vehicle. One of the state-of-the-art approaches is to apply Reinforcement Learning (RL) to learn a time-sequential driving policy, to execute proper control strategy or tracking trajectory in dynamic situations. However, direct application of RL algorithms is not satisfactorily enough to deal with the cases in the autonomous driving domain, mainly due to the complex driving environment and continuous action space. In this paper, we adopt Q-learning as our basic learning framework and design a unique format of the Q-function approximator that consists of neural networks to handle the continuous action space challenge. The learning model is present in a closed form of continuous control variables and trained in a simulation platform that we have developed with embedded properties of real-time vehicle interactions. The proposed algorithm avoids invoking an additional actor network that learns to take actions, as in actor-critic algorithms. At the same time, some prior knowledge of vehicle dynamics is also fed into the model to assist learning. We test our algorithm with a challenging use case - lane change maneuver, to verify the practicability and feasibility of the proposed approach. Results from accumulated rewards and vehicle performance show that RL vehicle agents successfully learn a safe, comfort and efficient driving policy as defined in the reward function.