 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenContrails: Benchmarking Contrail Detection on GOES-16 ABI
Apr 20, 2023



Contrails (condensation trails) are line-shaped ice clouds caused by aircraft and are likely the largest contributor of aviation-induced climate change. Contrail avoidance is potentially an inexpensive way to significantly reduce the climate impact of aviation. An automated contrail detection system is an essential tool to develop and evaluate contrail avoidance systems. In this paper, we present a human-labeled dataset named OpenContrails to train and evaluate contrail detection models based on GOES-16 Advanced Baseline Imager (ABI) data. We propose and evaluate a contrail detection model that incorporates temporal context for improved detection accuracy. The human labeled dataset and the contrail detection outputs are publicly available on Google Cloud Storage at gs://goes_contrails_dataset.
EnsembleNet: End-to-End Optimization of Multi-headed Models
May 24, 2019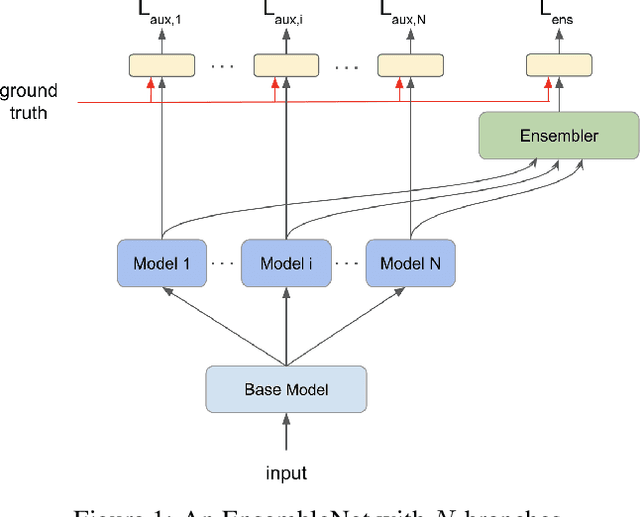
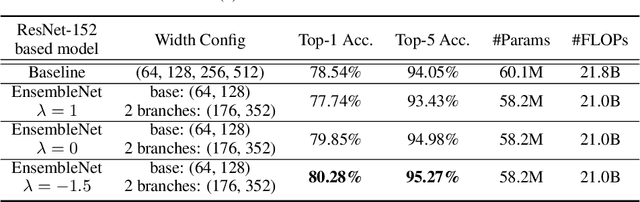
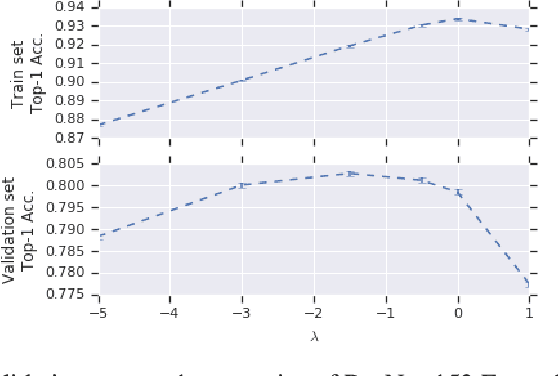
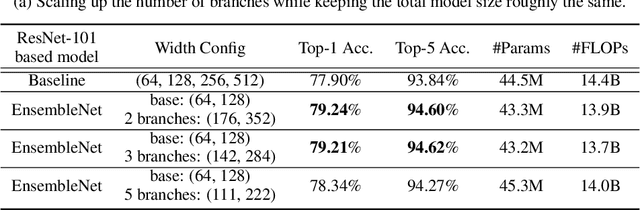
Ensembling is a universally useful approach to boost the performance of machine learning models. However, individual models in an ensemble are typically trained independently in separate stages, without information access about the overall ensemble. In this paper, model ensembles are treated as first-class citizens, and their performance is optimized end-to-end with parameter sharing and a novel loss structure that improves generalization. On large-scale datasets including ImageNet, Youtube-8M, and Kinetics, we demonstrate a procedure that starts from a strongly performing single deep neural network, and constructs an EnsembleNet that has both a smaller size and better performance. Moreover, an EnsembleNet can be trained in one stage just like a single model without manual intervention.
TAN: Temporal Aggregation Network for Dense Multi-label Action Recognition
Dec 14, 2018
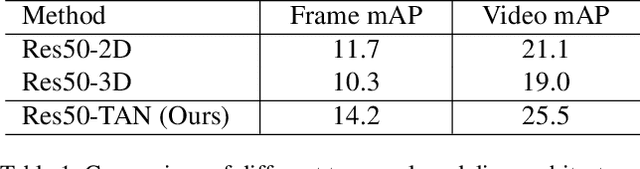
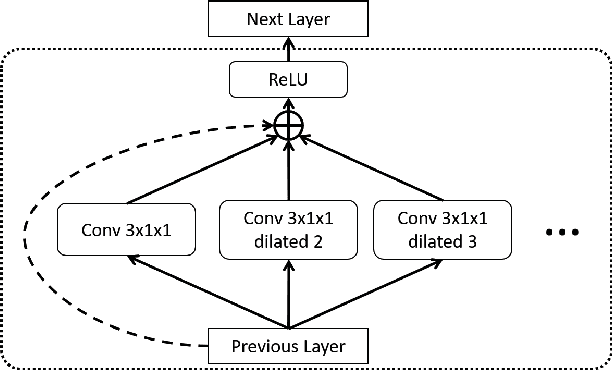
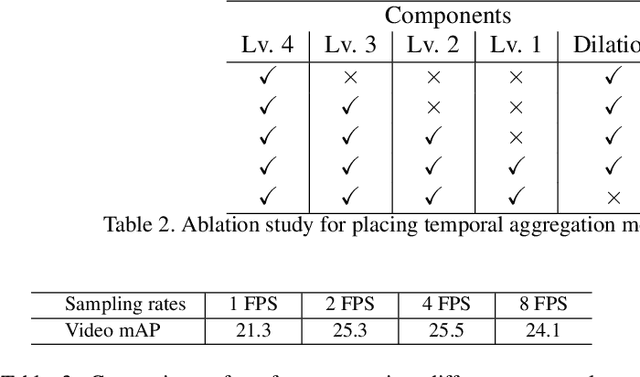
We present Temporal Aggregation Network (TAN) which decomposes 3D convolutions into spatial and temporal aggregation blocks. By stacking spatial and temporal convolutions repeatedly, TAN forms a deep hierarchical representation for capturing spatio-temporal information in videos. Since we do not apply 3D convolutions in each layer but only apply temporal aggregation blocks once after each spatial downsampling layer in the network, we significantly reduce the model complexity. The use of dilated convolutions at different resolutions of the network helps in aggregating multi-scale spatio-temporal information efficiently. Experiments show that our model is well suited for dense multi-label action recognition, which is a challenging sub-topic of action recognition that requires predicting multiple action labels in each frame. We outperform state-of-the-art methods by 5% and 3% on the Charades and Multi-THUMOS dataset respectively.
ActionFlowNet: Learning Motion Representation for Action Recognition
Feb 16, 2018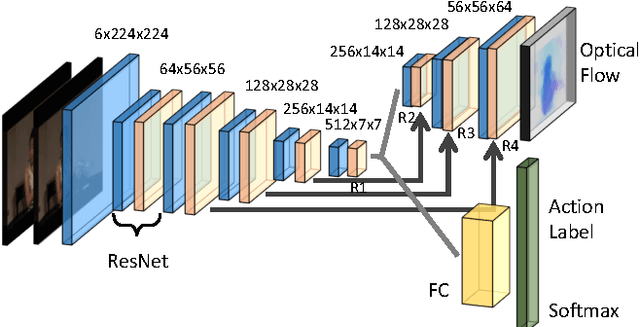
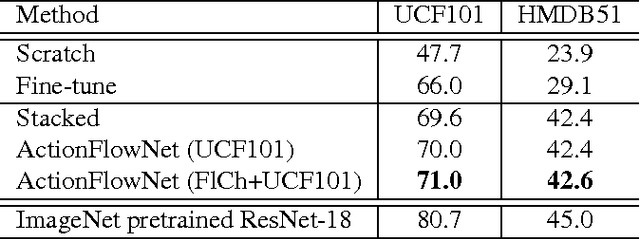
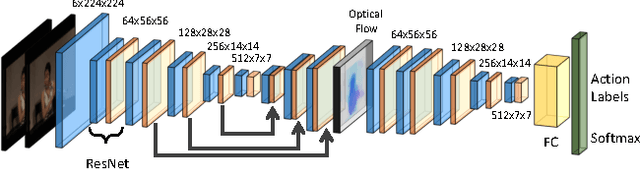
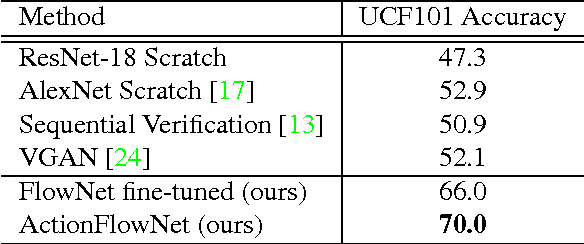
Even with the recent advances in convolutional neural networks (CNN) in various visual recognition tasks, the state-of-the-art action recognition system still relies on hand crafted motion feature such as optical flow to achieve the best performance. We propose a multitask learning model ActionFlowNet to train a single stream network directly from raw pixels to jointly estimate optical flow while recognizing actions with convolutional neural networks, capturing both appearance and motion in a single model. We additionally provide insights to how the quality of the learned optical flow affects the action recognition. Our model significantly improves action recognition accuracy by a large margin 31% compared to state-of-the-art CNN-based action recognition models trained without external large scale data and additional optical flow input. Without pretraining on large external labeled datasets, our model, by well exploiting the motion information, achieves competitive recognition accuracy to the models trained with large labeled datasets such as ImageNet and Sport-1M.
Generating Holistic 3D Scene Abstractions for Text-based Image Retrieval
Apr 11, 2017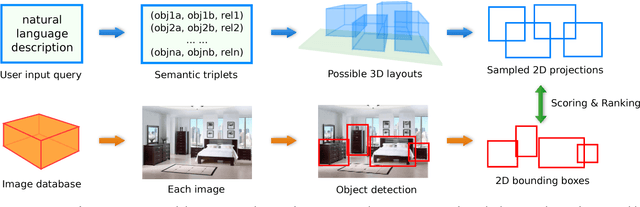

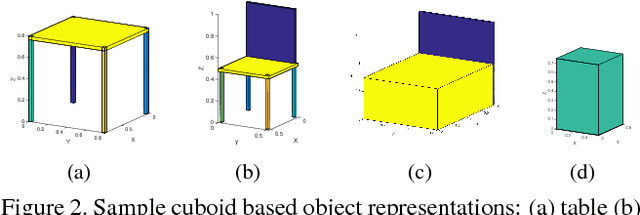
Spatial relationships between objects provide important information for text-based image retrieval. As users are more likely to describe a scene from a real world perspective, using 3D spatial relationships rather than 2D relationships that assume a particular viewing direction, one of the main challenges is to infer the 3D structure that bridges images with users' text descriptions. However, direct inference of 3D structure from images requires learning from large scale annotated data. Since interactions between objects can be reduced to a limited set of atomic spatial relations in 3D, we study the possibility of inferring 3D structure from a text description rather than an image, applying physical relation models to synthesize holistic 3D abstract object layouts satisfying the spatial constraints present in a textual description. We present a generic framework for retrieving images from a textual description of a scene by matching images with these generated abstract object layouts. Images are ranked by matching object detection outputs (bounding boxes) to 2D layout candidates (also represented by bounding boxes) which are obtained by projecting the 3D scenes with sampled camera directions. We validate our approach using public indoor scene datasets and show that our method outperforms baselines built upon object occurrence histograms and learned 2D pairwise relations.
Exploiting Local Features from Deep Networks for Image Retrieval
Apr 30, 2015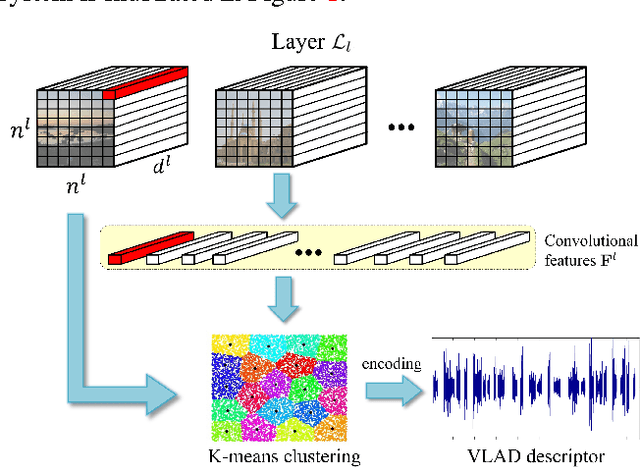
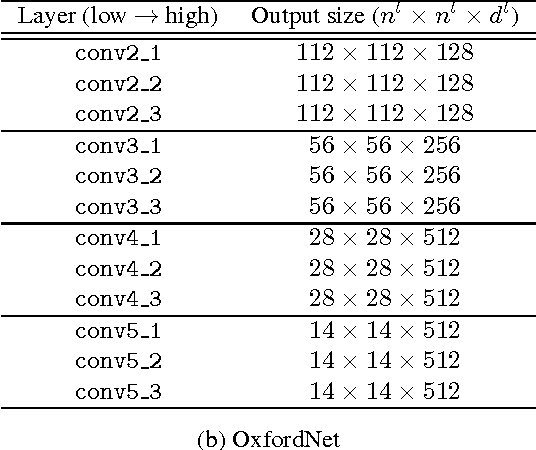
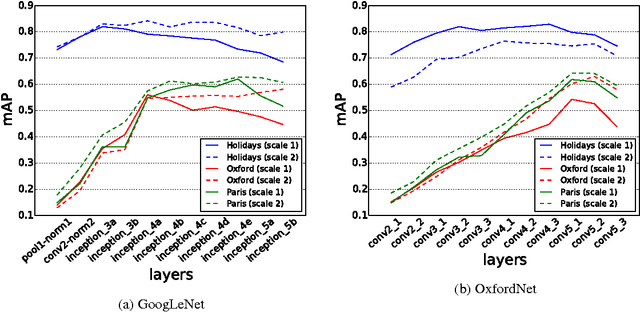
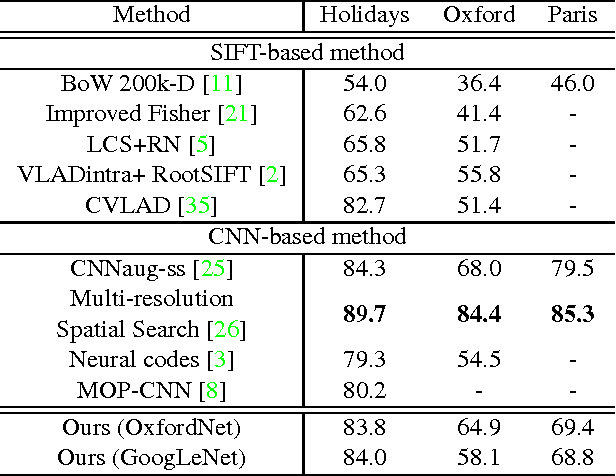
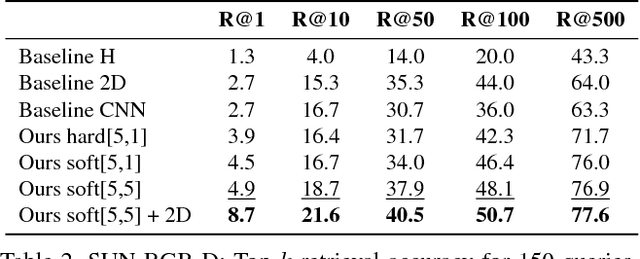
Deep convolutional neural networks have been successfully applied to image classification tasks. When these same networks have been applied to image retrieval, the assumption has been made that the last layers would give the best performance, as they do in classification. We show that for instance-level image retrieval, lower layers often perform better than the last layers in convolutional neural networks. We present an approach for extracting convolutional features from different layers of the networks, and adopt VLAD encoding to encode features into a single vector for each image. We investigate the effect of different layers and scales of input images on the performance of convolutional features using the recent deep networks OxfordNet and GoogLeNet. Experiments demonstrate that intermediate layers or higher layers with finer scales produce better results for image retrieval, compared to the last layer. When using compressed 128-D VLAD descriptors, our method obtains state-of-the-art results and outperforms other VLAD and CNN based approaches on two out of three test datasets. Our work provides guidance for transferring deep networks trained on image classification to image retrieval tasks.
Beyond Short Snippets: Deep Networks for Video Classification
Apr 13, 2015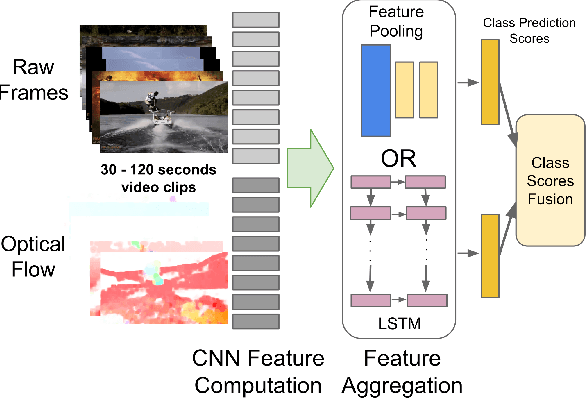
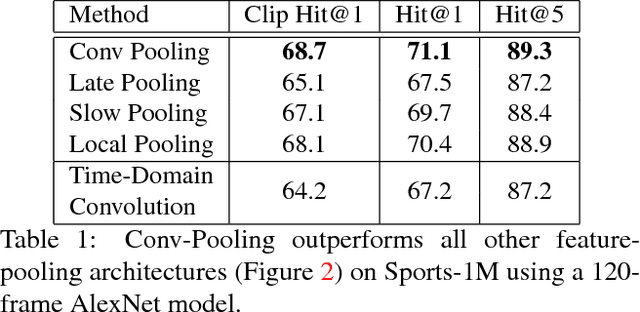
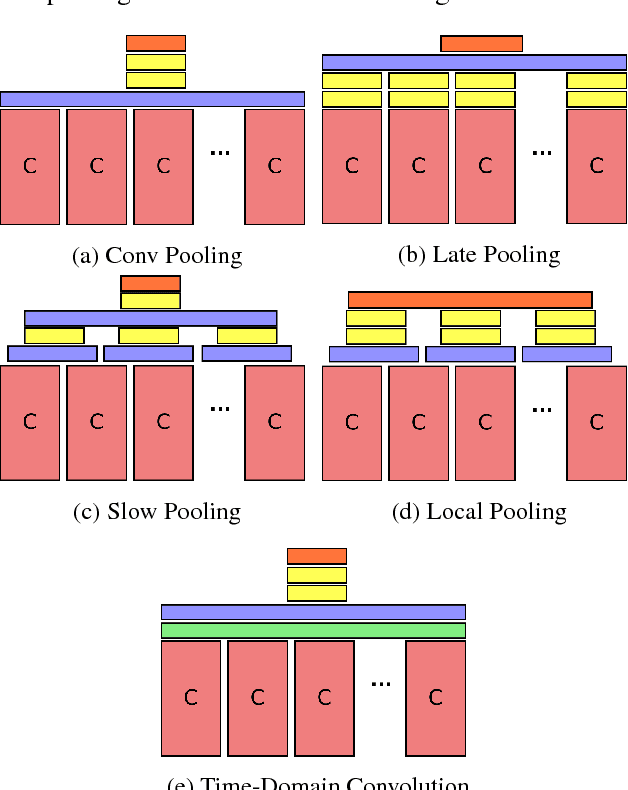
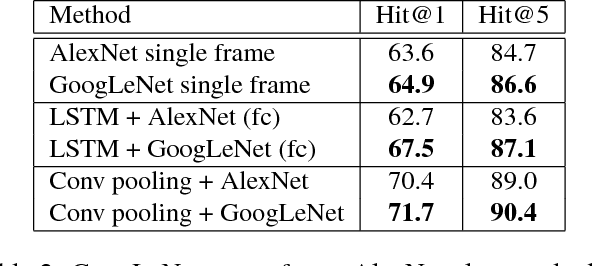
Convolutional neural networks (CNNs) have been extensively applied for image recognition problems giving state-of-the-art results on recognition, detection, segmentation and retrieval. In this work we propose and evaluate several deep neural network architectures to combine image information across a video over longer time periods than previously attempted. We propose two methods capable of handling full length videos. The first method explores various convolutional temporal feature pooling architectures, examining the various design choices which need to be made when adapting a CNN for this task. The second proposed method explicitly models the video as an ordered sequence of frames. For this purpose we employ a recurrent neural network that uses Long Short-Term Memory (LSTM) cells which are connected to the output of the underlying CNN. Our best networks exhibit significant performance improvements over previously published results on the Sports 1 million dataset (73.1% vs. 60.9%) and the UCF-101 datasets with (88.6% vs. 88.0%) and without additional optical flow information (82.6% vs. 72.8%).