 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
EnsembleNet: End-to-End Optimization of Multi-headed Models
May 24, 2019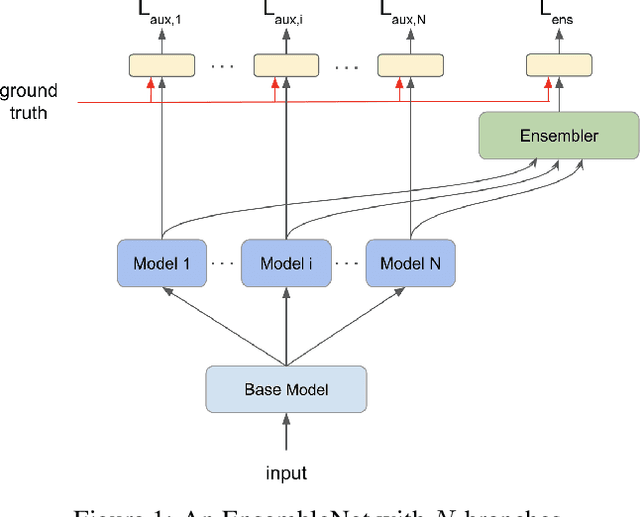
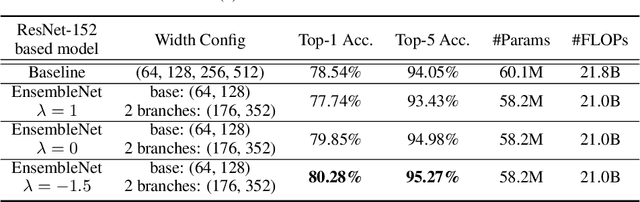
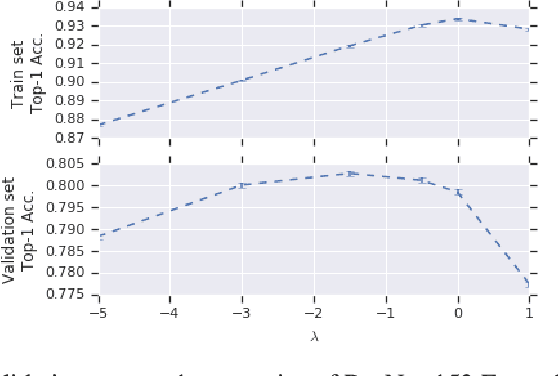
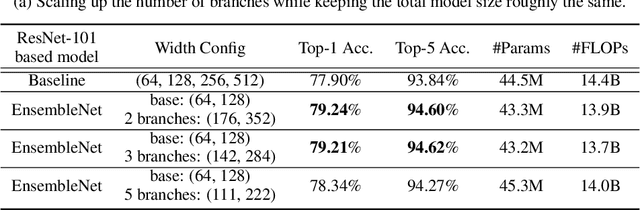
Ensembling is a universally useful approach to boost the performance of machine learning models. However, individual models in an ensemble are typically trained independently in separate stages, without information access about the overall ensemble. In this paper, model ensembles are treated as first-class citizens, and their performance is optimized end-to-end with parameter sharing and a novel loss structure that improves generalization. On large-scale datasets including ImageNet, Youtube-8M, and Kinetics, we demonstrate a procedure that starts from a strongly performing single deep neural network, and constructs an EnsembleNet that has both a smaller size and better performance. Moreover, an EnsembleNet can be trained in one stage just like a single model without manual intervention.
The Kinetics Human Action Video Dataset
May 19, 2017
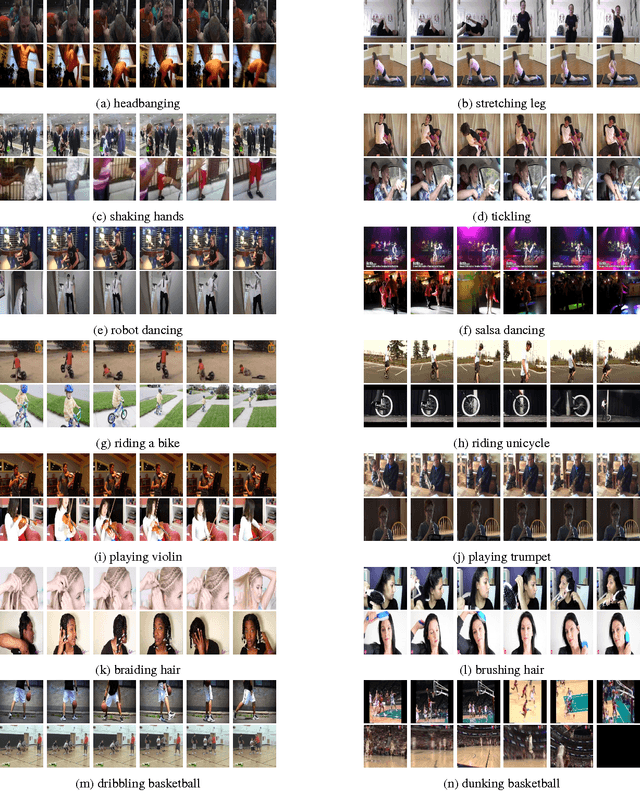
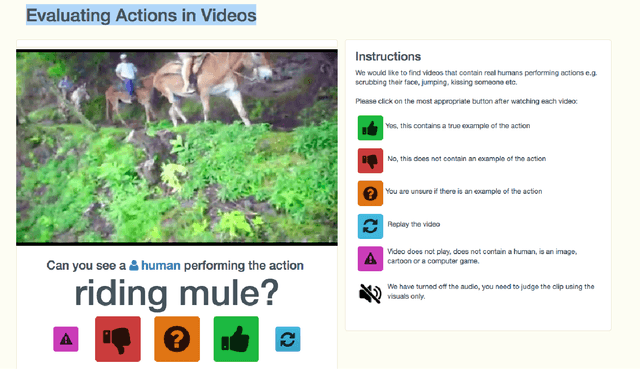
We describe the DeepMind Kinetics human action video dataset. The dataset contains 400 human action classes, with at least 400 video clips for each action. Each clip lasts around 10s and is taken from a different YouTube video. The actions are human focussed and cover a broad range of classes including human-object interactions such as playing instruments, as well as human-human interactions such as shaking hands. We describe the statistics of the dataset, how it was collected, and give some baseline performance figures for neural network architectures trained and tested for human action classification on this dataset. We also carry out a preliminary analysis of whether imbalance in the dataset leads to bias in the classifiers.
YouTube-8M: A Large-Scale Video Classification Benchmark
Sep 27, 2016



Many recent advancements in Computer Vision are attributed to large datasets. Open-source software packages for Machine Learning and inexpensive commodity hardware have reduced the barrier of entry for exploring novel approaches at scale. It is possible to train models over millions of examples within a few days. Although large-scale datasets exist for image understanding, such as ImageNet, there are no comparable size video classification datasets. In this paper, we introduce YouTube-8M, the largest multi-label video classification dataset, composed of ~8 million videos (500K hours of video), annotated with a vocabulary of 4800 visual entities. To get the videos and their labels, we used a YouTube video annotation system, which labels videos with their main topics. While the labels are machine-generated, they have high-precision and are derived from a variety of human-based signals including metadata and query click signals. We filtered the video labels (Knowledge Graph entities) using both automated and manual curation strategies, including asking human raters if the labels are visually recognizable. Then, we decoded each video at one-frame-per-second, and used a Deep CNN pre-trained on ImageNet to extract the hidden representation immediately prior to the classification layer. Finally, we compressed the frame features and make both the features and video-level labels available for download. We trained various (modest) classification models on the dataset, evaluated them using popular evaluation metrics, and report them as baselines. Despite the size of the dataset, some of our models train to convergence in less than a day on a single machine using TensorFlow. We plan to release code for training a TensorFlow model and for computing metrics.