 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLong-Span Question-Answering: Automatic Question Generation and QA-System Ranking via Side-by-Side Evaluation
May 31, 2024



We explore the use of long-context capabilities in large language models to create synthetic reading comprehension data from entire books. Previous efforts to construct such datasets relied on crowd-sourcing, but the emergence of transformers with a context size of 1 million or more tokens now enables entirely automatic approaches. Our objective is to test the capabilities of LLMs to analyze, understand, and reason over problems that require a detailed comprehension of long spans of text, such as questions involving character arcs, broader themes, or the consequences of early actions later in the story. We propose a holistic pipeline for automatic data generation including question generation, answering, and model scoring using an ``Evaluator''. We find that a relative approach, comparing answers between models in a pairwise fashion and ranking with a Bradley-Terry model, provides a more consistent and differentiating scoring mechanism than an absolute scorer that rates answers individually. We also show that LLMs from different model families produce moderate agreement in their ratings. We ground our approach using the manually curated NarrativeQA dataset, where our evaluator shows excellent agreement with human judgement and even finds errors in the dataset. Using our automatic evaluation approach, we show that using an entire book as context produces superior reading comprehension performance compared to baseline no-context (parametric knowledge only) and retrieval-based approaches.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Towards Robust and Efficient Continual Language Learning
Jul 11, 2023



As the application space of language models continues to evolve, a natural question to ask is how we can quickly adapt models to new tasks. We approach this classic question from a continual learning perspective, in which we aim to continue fine-tuning models trained on past tasks on new tasks, with the goal of "transferring" relevant knowledge. However, this strategy also runs the risk of doing more harm than good, i.e., negative transfer. In this paper, we construct a new benchmark of task sequences that target different possible transfer scenarios one might face, such as a sequence of tasks with high potential of positive transfer, high potential for negative transfer, no expected effect, or a mixture of each. An ideal learner should be able to maximally exploit information from all tasks that have any potential for positive transfer, while also avoiding the negative effects of any distracting tasks that may confuse it. We then propose a simple, yet effective, learner that satisfies many of our desiderata simply by leveraging a selective strategy for initializing new models from past task checkpoints. Still, limitations remain, and we hope this benchmark can help the community to further build and analyze such learners.
NEVIS'22: A Stream of 100 Tasks Sampled from 30 Years of Computer Vision Research
Nov 15, 2022We introduce the Never Ending VIsual-classification Stream (NEVIS'22), a benchmark consisting of a stream of over 100 visual classification tasks, sorted chronologically and extracted from papers sampled uniformly from computer vision proceedings spanning the last three decades. The resulting stream reflects what the research community thought was meaningful at any point in time. Despite being limited to classification, the resulting stream has a rich diversity of tasks from OCR, to texture analysis, crowd counting, scene recognition, and so forth. The diversity is also reflected in the wide range of dataset sizes, spanning over four orders of magnitude. Overall, NEVIS'22 poses an unprecedented challenge for current sequential learning approaches due to the scale and diversity of tasks, yet with a low entry barrier as it is limited to a single modality and each task is a classical supervised learning problem. Moreover, we provide a reference implementation including strong baselines and a simple evaluation protocol to compare methods in terms of their trade-off between accuracy and compute. We hope that NEVIS'22 can be useful to researchers working on continual learning, meta-learning, AutoML and more generally sequential learning, and help these communities join forces towards more robust and efficient models that efficiently adapt to a never ending stream of data. Implementations have been made available at https://github.com/deepmind/dm_nevis.
StreamingQA: A Benchmark for Adaptation to New Knowledge over Time in Question Answering Models
May 23, 2022
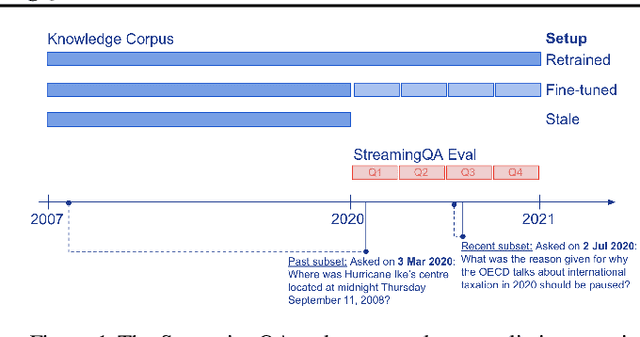

Knowledge and language understanding of models evaluated through question answering (QA) has been usually studied on static snapshots of knowledge, like Wikipedia. However, our world is dynamic, evolves over time, and our models' knowledge becomes outdated. To study how semi-parametric QA models and their underlying parametric language models (LMs) adapt to evolving knowledge, we construct a new large-scale dataset, StreamingQA, with human written and generated questions asked on a given date, to be answered from 14 years of time-stamped news articles. We evaluate our models quarterly as they read new articles not seen in pre-training. We show that parametric models can be updated without full retraining, while avoiding catastrophic forgetting. For semi-parametric models, adding new articles into the search space allows for rapid adaptation, however, models with an outdated underlying LM under-perform those with a retrained LM. For questions about higher-frequency named entities, parametric updates are particularly beneficial. In our dynamic world, the StreamingQA dataset enables a more realistic evaluation of QA models, and our experiments highlight several promising directions for future research.
Internet-augmented language models through few-shot prompting for open-domain question answering
Mar 10, 2022
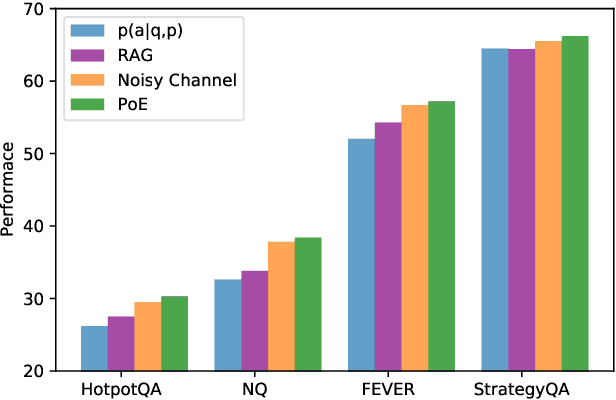
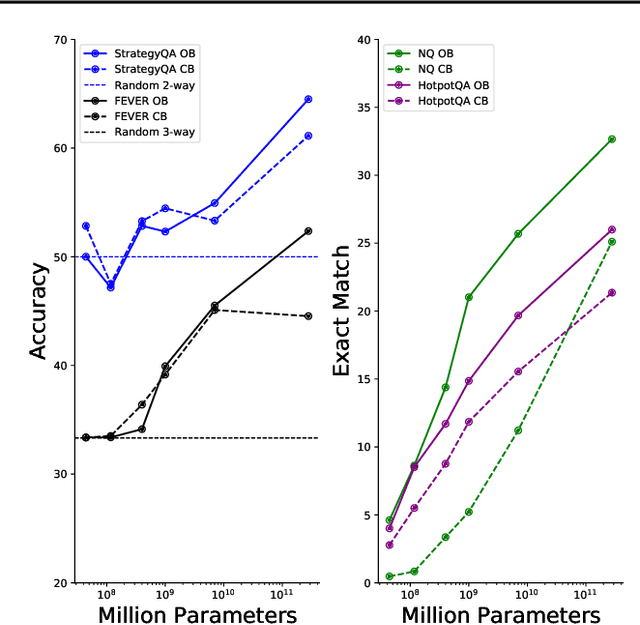
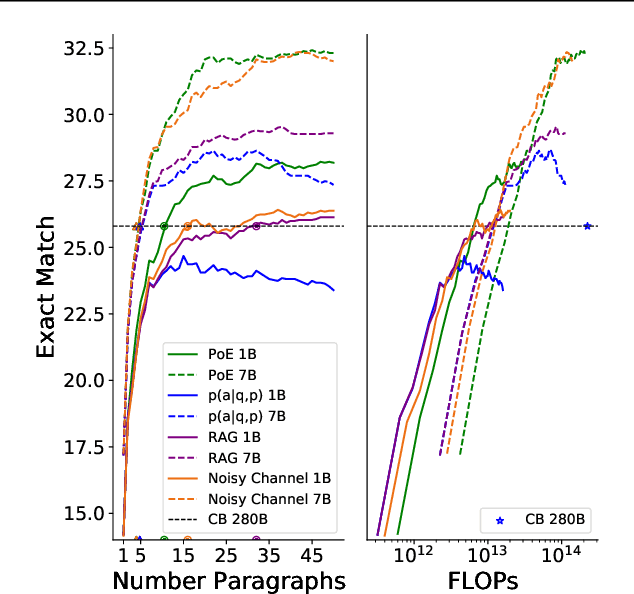
In this work, we aim to capitalize on the unique few-shot capabilities offered by large-scale language models to overcome some of their challenges with respect to grounding to factual and up-to-date information. Motivated by semi-parametric language models, which ground their decisions in external retrieved evidence, we use few-shot prompting to learn to condition language models on information returned from the web using Google Search, a broad and constantly updated knowledge source. Our approach does not involve fine-tuning or learning additional parameters, thus making it applicable to any language model, offering like this a strong baseline. Indeed, we find that language models conditioned on the web surpass performance of closed-book models of similar, or even larger, model sizes in open-domain question answering. Finally, we find that increasing the inference-time compute of models, achieved via using multiple retrieved evidences to generate multiple answers followed by a reranking stage, alleviates generally decreased performance of smaller few-shot language models. All in all, our findings suggest that it might be beneficial to slow down the race towards the biggest model and instead shift the attention towards finding more effective ways to use models, including but not limited to better prompting or increasing inference-time compute.
Scaling Language Models: Methods, Analysis & Insights from Training Gopher
Dec 08, 2021



Language modelling provides a step towards intelligent communication systems by harnessing large repositories of written human knowledge to better predict and understand the world. In this paper, we present an analysis of Transformer-based language model performance across a wide range of model scales -- from models with tens of millions of parameters up to a 280 billion parameter model called Gopher. These models are evaluated on 152 diverse tasks, achieving state-of-the-art performance across the majority. Gains from scale are largest in areas such as reading comprehension, fact-checking, and the identification of toxic language, but logical and mathematical reasoning see less benefit. We provide a holistic analysis of the training dataset and model's behaviour, covering the intersection of model scale with bias and toxicity. Finally we discuss the application of language models to AI safety and the mitigation of downstream harms.
Dynamic population-based meta-learning for multi-agent communication with natural language
Oct 27, 2021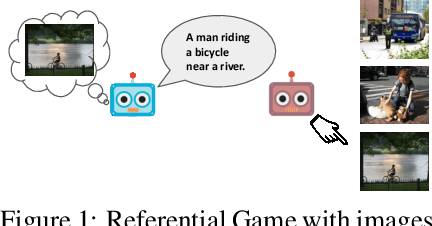



In this work, our goal is to train agents that can coordinate with seen, unseen as well as human partners in a multi-agent communication environment involving natural language. Previous work using a single set of agents has shown great progress in generalizing to known partners, however it struggles when coordinating with unfamiliar agents. To mitigate that, recent work explored the use of population-based approaches, where multiple agents interact with each other with the goal of learning more generic protocols. These methods, while able to result in good coordination between unseen partners, still only achieve so in cases of simple languages, thus failing to adapt to human partners using natural language. We attribute this to the use of static populations and instead propose a dynamic population-based meta-learning approach that builds such a population in an iterative manner. We perform a holistic evaluation of our method on two different referential games, and show that our agents outperform all prior work when communicating with seen partners and humans. Furthermore, we analyze the natural language generation skills of our agents, where we find that our agents also outperform strong baselines. Finally, we test the robustness of our agents when communicating with out-of-population agents and carefully test the importance of each component of our method through ablation studies.
Pitfalls of Static Language Modelling
Feb 03, 2021
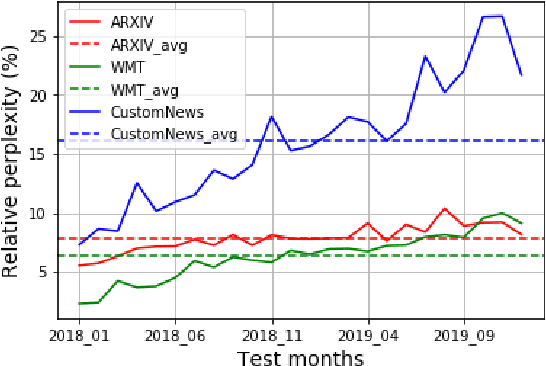
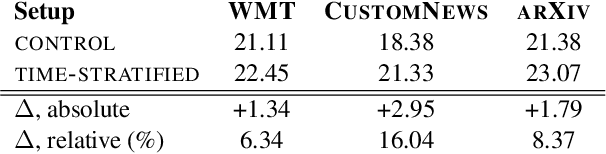
Our world is open-ended, non-stationary and constantly evolving; thus what we talk about and how we talk about it changes over time. This inherent dynamic nature of language comes in stark contrast to the current static language modelling paradigm, which constructs training and evaluation sets from overlapping time periods. Despite recent progress, we demonstrate that state-of-the-art Transformer models perform worse in the realistic setup of predicting future utterances from beyond their training period -- a consistent pattern across three datasets from two domains. We find that, while increasing model size alone -- a key driver behind recent progress -- does not provide a solution for the temporal generalization problem, having models that continually update their knowledge with new information can indeed slow down the degradation over time. Hence, given the compilation of ever-larger language modelling training datasets, combined with the growing list of language-model-based NLP applications that require up-to-date knowledge about the world, we argue that now is the right time to rethink our static language modelling evaluation protocol, and develop adaptive language models that can remain up-to-date with respect to our ever-changing and non-stationary world.