 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
StreamingQA: A Benchmark for Adaptation to New Knowledge over Time in Question Answering Models
May 23, 2022
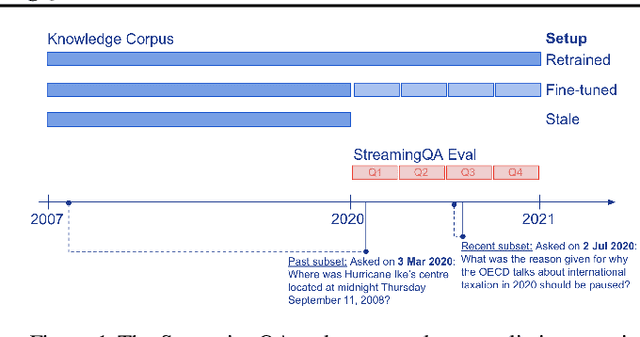

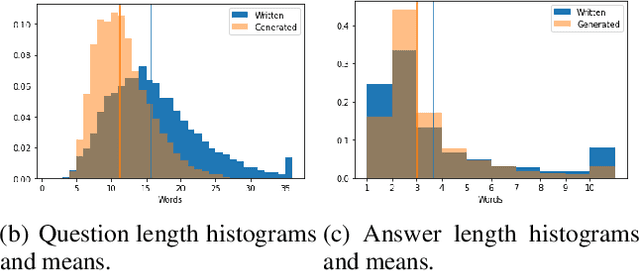
Knowledge and language understanding of models evaluated through question answering (QA) has been usually studied on static snapshots of knowledge, like Wikipedia. However, our world is dynamic, evolves over time, and our models' knowledge becomes outdated. To study how semi-parametric QA models and their underlying parametric language models (LMs) adapt to evolving knowledge, we construct a new large-scale dataset, StreamingQA, with human written and generated questions asked on a given date, to be answered from 14 years of time-stamped news articles. We evaluate our models quarterly as they read new articles not seen in pre-training. We show that parametric models can be updated without full retraining, while avoiding catastrophic forgetting. For semi-parametric models, adding new articles into the search space allows for rapid adaptation, however, models with an outdated underlying LM under-perform those with a retrained LM. For questions about higher-frequency named entities, parametric updates are particularly beneficial. In our dynamic world, the StreamingQA dataset enables a more realistic evaluation of QA models, and our experiments highlight several promising directions for future research.
Large-scale multilingual audio visual dubbing
Nov 06, 2020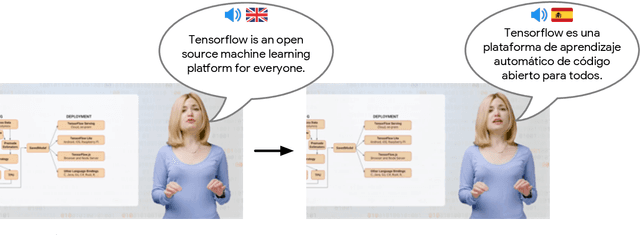
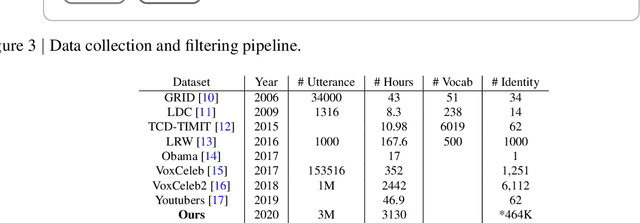
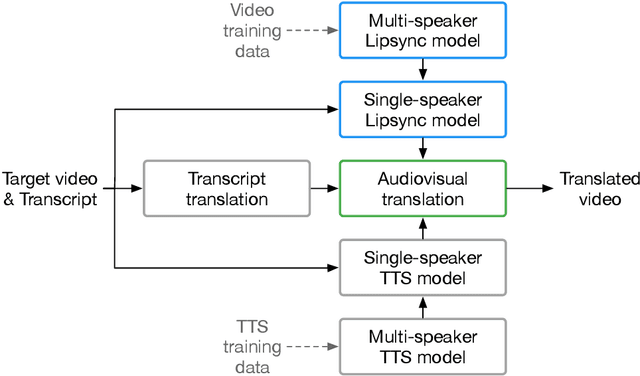
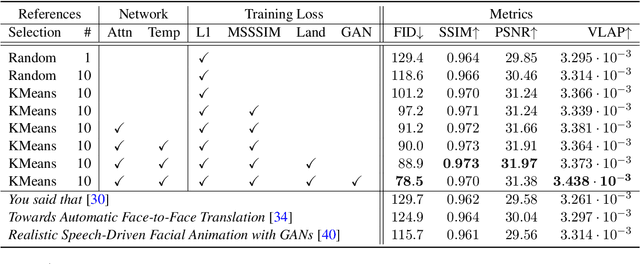
We describe a system for large-scale audiovisual translation and dubbing, which translates videos from one language to another. The source language's speech content is transcribed to text, translated, and automatically synthesized into target language speech using the original speaker's voice. The visual content is translated by synthesizing lip movements for the speaker to match the translated audio, creating a seamless audiovisual experience in the target language. The audio and visual translation subsystems each contain a large-scale generic synthesis model trained on thousands of hours of data in the corresponding domain. These generic models are fine-tuned to a specific speaker before translation, either using an auxiliary corpus of data from the target speaker, or using the video to be translated itself as the input to the fine-tuning process. This report gives an architectural overview of the full system, as well as an in-depth discussion of the video dubbing component. The role of the audio and text components in relation to the full system is outlined, but their design is not discussed in detail. Translated and dubbed demo videos generated using our system can be viewed at https://www.youtube.com/playlist?list=PLSi232j2ZA6_1Exhof5vndzyfbxAhhEs5
A Combinatorial Perspective on Transfer Learning
Oct 23, 2020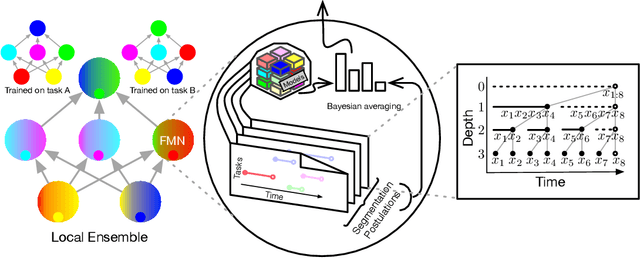
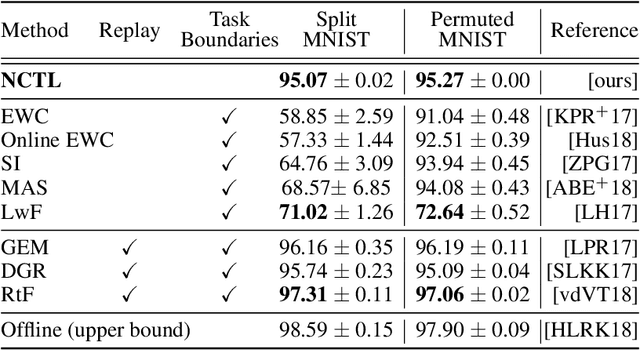
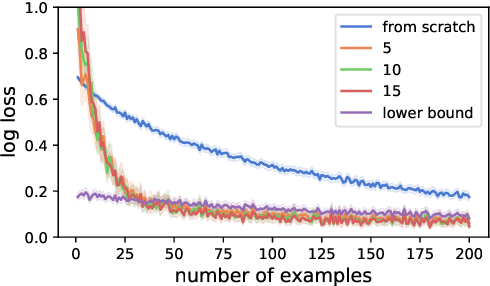
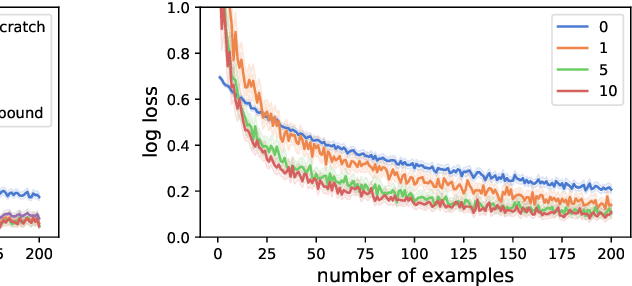
Human intelligence is characterized not only by the capacity to learn complex skills, but the ability to rapidly adapt and acquire new skills within an ever-changing environment. In this work we study how the learning of modular solutions can allow for effective generalization to both unseen and potentially differently distributed data. Our main postulate is that the combination of task segmentation, modular learning and memory-based ensembling can give rise to generalization on an exponentially growing number of unseen tasks. We provide a concrete instantiation of this idea using a combination of: (1) the Forget-Me-Not Process, for task segmentation and memory based ensembling; and (2) Gated Linear Networks, which in contrast to contemporary deep learning techniques use a modular and local learning mechanism. We demonstrate that this system exhibits a number of desirable continual learning properties: robustness to catastrophic forgetting, no negative transfer and increasing levels of positive transfer as more tasks are seen. We show competitive performance against both offline and online methods on standard continual learning benchmarks.
Gaussian Gated Linear Networks
Jun 10, 2020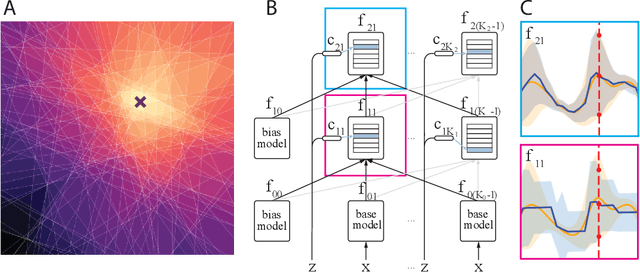
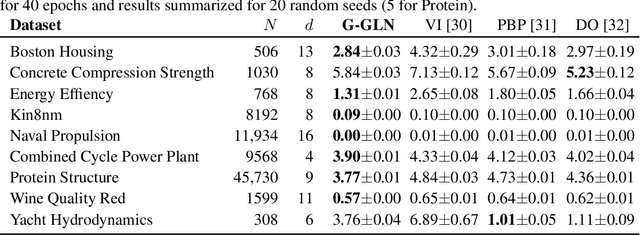
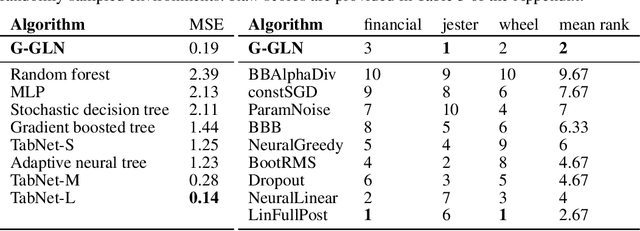
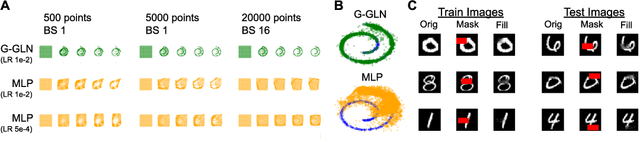
We propose the Gaussian Gated Linear Network (G-GLN), an extension to the recently proposed GLN family of deep neural networks. Instead of using backpropagation to learn features, GLNs have a distributed and local credit assignment mechanism based on optimizing a convex objective. This gives rise to many desirable properties including universality, data-efficient online learning, trivial interpretability and robustness to catastrophic forgetting. We extend the GLN framework from classification to multiple regression and density modelling by generalizing geometric mixing to a product of Gaussian densities. The G-GLN achieves competitive or state-of-the-art performance on several univariate and multivariate regression benchmarks, and we demonstrate its applicability to practical tasks including online contextual bandits and density estimation via denoising.
Online Learning in Contextual Bandits using Gated Linear Networks
Feb 21, 2020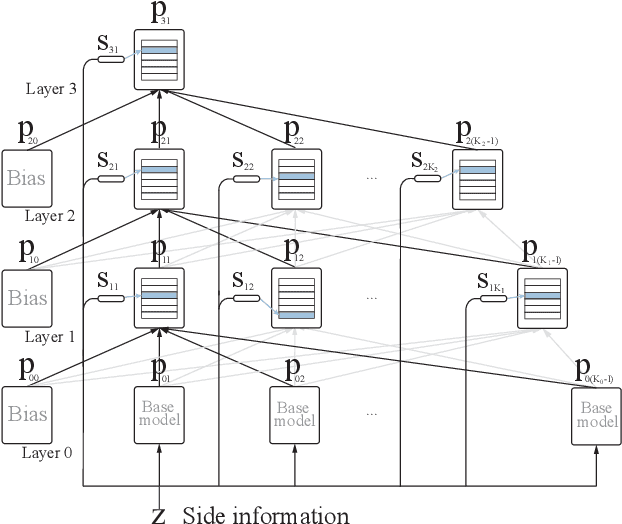
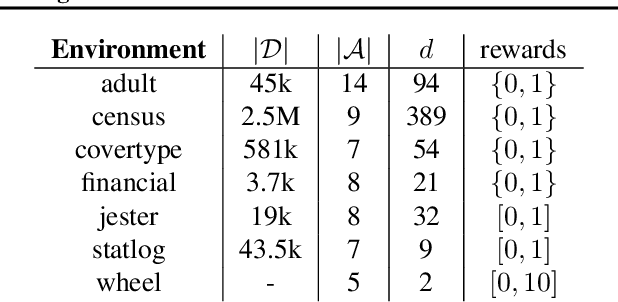
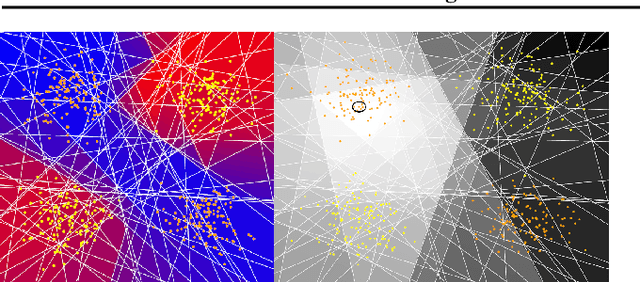
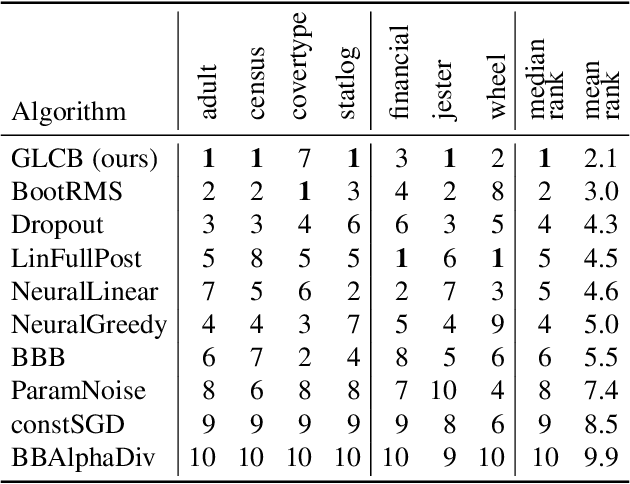
We introduce a new and completely online contextual bandit algorithm called Gated Linear Contextual Bandits (GLCB). This algorithm is based on Gated Linear Networks (GLNs), a recently introduced deep learning architecture with properties well-suited to the online setting. Leveraging data-dependent gating properties of the GLN we are able to estimate prediction uncertainty with effectively zero algorithmic overhead. We empirically evaluate GLCB compared to 9 state-of-the-art algorithms that leverage deep neural networks, on a standard benchmark suite of discrete and continuous contextual bandit problems. GLCB obtains median first-place despite being the only online method, and we further support these results with a theoretical study of its convergence properties.
Static and Dynamic Values of Computation in MCTS
Feb 11, 2020
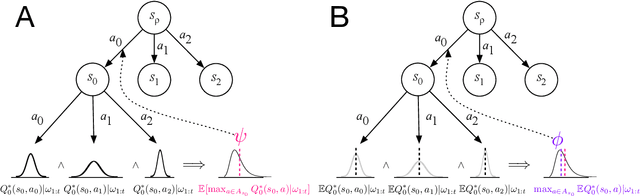
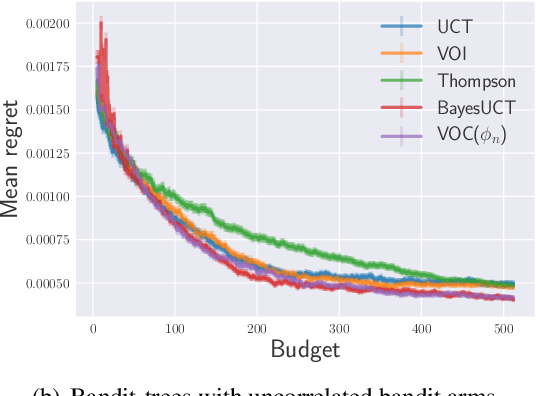
Monte-Carlo Tree Search (MCTS) is one of the most-widely used methods for planning, and has powered many recent advances in artificial intelligence. In MCTS, one typically performs computations (i.e., simulations) to collect statistics about the possible future consequences of actions, and then chooses accordingly. Many popular MCTS methods such as UCT and its variants decide which computations to perform by trading-off exploration and exploitation. In this work, we take a more direct approach, and explicitly quantify the value of a computation based on its expected impact on the quality of the action eventually chosen. Our approach goes beyond the "myopic" limitations of existing computation-value-based methods in two senses: (I) we are able to account for the impact of non-immediate (ie, future) computations (II) on non-immediate actions. We show that policies that greedily optimize computation values are optimal under certain assumptions and obtain results that are competitive with the state-of-the-art.
Behaviour Suite for Reinforcement Learning
Aug 13, 2019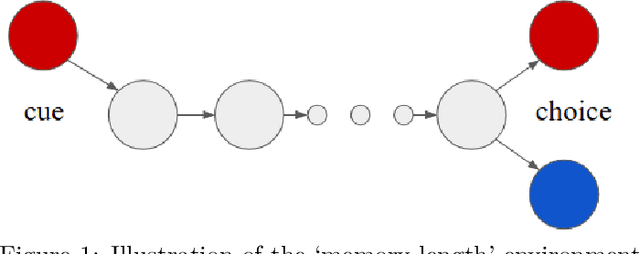
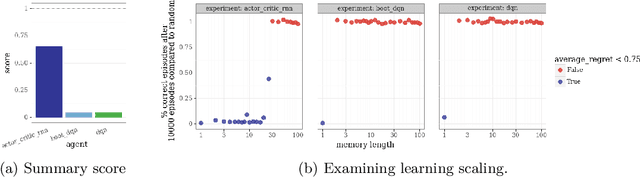
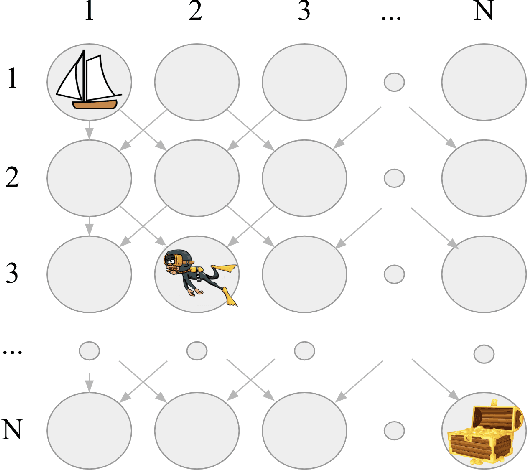
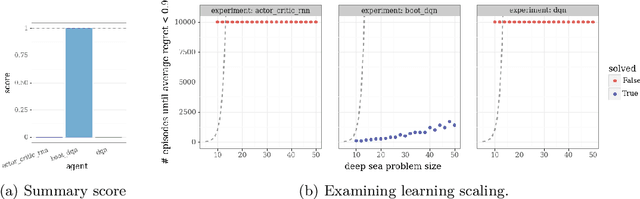
This paper introduces the Behaviour Suite for Reinforcement Learning, or bsuite for short. bsuite is a collection of carefully-designed experiments that investigate core capabilities of reinforcement learning (RL) agents with two objectives. First, to collect clear, informative and scalable problems that capture key issues in the design of general and efficient learning algorithms. Second, to study agent behaviour through their performance on these shared benchmarks. To complement this effort, we open source github.com/deepmind/bsuite, which automates evaluation and analysis of any agent on bsuite. This library facilitates reproducible and accessible research on the core issues in RL, and ultimately the design of superior learning algorithms. Our code is Python, and easy to use within existing projects. We include examples with OpenAI Baselines, Dopamine as well as new reference implementations. Going forward, we hope to incorporate more excellent experiments from the research community, and commit to a periodic review of bsuite from a committee of prominent researchers.