 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefined Detection for Gumbel Watermarking
Mar 31, 2026We propose a simple detection mechanism for the Gumbel watermarking scheme proposed by Aaronson (2022). The new mechanism is proven to be near-optimal in a problem-dependent sense among all model-agnostic watermarking schemes under the assumption that the next-token distribution is sampled i.i.d.
A Lyapunov Analysis of Softmax Policy Gradient for Stochastic Bandits
Mar 27, 2026We adapt the analysis of policy gradient for continuous time $k$-armed stochastic bandits by Lattimore (2026) to the standard discrete time setup. As in continuous time, we prove that with learning rate $η= O(Δ_{\min}^2/(Δ_{\max} \log(n)))$ the regret is $O(k \log(k) \log(n) / η)$ where $n$ is the horizon and $Δ_{\min}$ and $Δ_{\max}$ are the minimum and maximum gaps.
A Diffusion Analysis of Policy Gradient for Stochastic Bandits
Mar 10, 2026We study a continuous-time diffusion approximation of policy gradient for $k$-armed stochastic bandits. We prove that with a learning rate $η= O(Δ^2/\log(n))$ the regret is $O(k \log(k) \log(n) / η)$ where $n$ is the horizon and $Δ$ the minimum gap. Moreover, we construct an instance with only logarithmically many arms for which the regret is linear unless $η= O(Δ^2)$.
Online Newton Method for Bandit Convex Optimisation
Jun 10, 2024We introduce a computationally efficient algorithm for zeroth-order bandit convex optimisation and prove that in the adversarial setting its regret is at most $d^{3.5} \sqrt{n} \mathrm{polylog}(n, d)$ with high probability where $d$ is the dimension and $n$ is the time horizon. In the stochastic setting the bound improves to $M d^{2} \sqrt{n} \mathrm{polylog}(n, d)$ where $M \in [d^{-1/2}, d^{-1 / 4}]$ is a constant that depends on the geometry of the constraint set and the desired computational properties.
Bandit Convex Optimisation
Feb 09, 2024
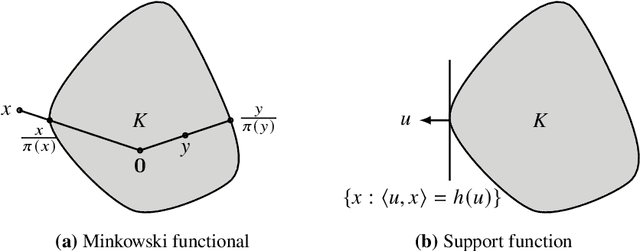
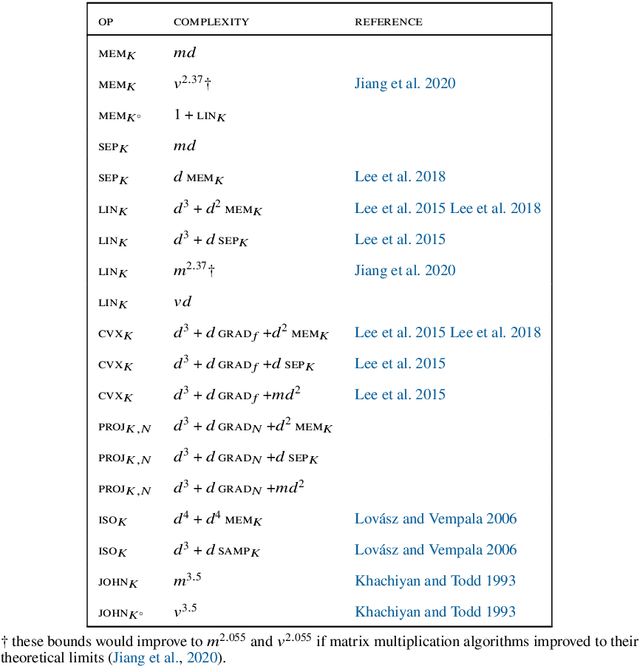
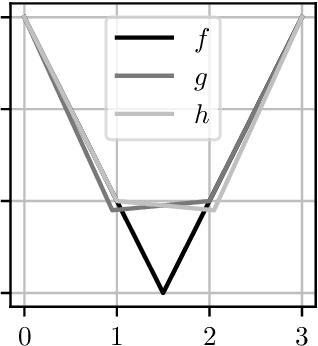
Bandit convex optimisation is a fundamental framework for studying zeroth-order convex optimisation. These notes cover the many tools used for this problem, including cutting plane methods, interior point methods, continuous exponential weights, gradient descent and online Newton step. The nuances between the many assumptions and setups are explained. Although there is not much truly new here, some existing tools are applied in novel ways to obtain new algorithms. A few bounds are improved in minor ways.
Probabilistic Inference in Reinforcement Learning Done Right
Nov 22, 2023A popular perspective in Reinforcement learning (RL) casts the problem as probabilistic inference on a graphical model of the Markov decision process (MDP). The core object of study is the probability of each state-action pair being visited under the optimal policy. Previous approaches to approximate this quantity can be arbitrarily poor, leading to algorithms that do not implement genuine statistical inference and consequently do not perform well in challenging problems. In this work, we undertake a rigorous Bayesian treatment of the posterior probability of state-action optimality and clarify how it flows through the MDP. We first reveal that this quantity can indeed be used to generate a policy that explores efficiently, as measured by regret. Unfortunately, computing it is intractable, so we derive a new variational Bayesian approximation yielding a tractable convex optimization problem and establish that the resulting policy also explores efficiently. We call our approach VAPOR and show that it has strong connections to Thompson sampling, K-learning, and maximum entropy exploration. We conclude with some experiments demonstrating the performance advantage of a deep RL version of VAPOR.
Context-lumpable stochastic bandits
Jun 22, 2023We consider a contextual bandit problem with $S $ contexts and $A $ actions. In each round $t=1,2,\dots$ the learner observes a random context and chooses an action based on its past experience. The learner then observes a random reward whose mean is a function of the context and the action for the round. Under the assumption that the contexts can be lumped into $r\le \min\{S ,A \}$ groups such that the mean reward for the various actions is the same for any two contexts that are in the same group, we give an algorithm that outputs an $\epsilon$-optimal policy after using at most $\widetilde O(r (S +A )/\epsilon^2)$ samples with high probability and provide a matching $\widetilde\Omega(r (S +A )/\epsilon^2)$ lower bound. In the regret minimization setting, we give an algorithm whose cumulative regret up to time $T$ is bounded by $\widetilde O(\sqrt{r^3(S +A )T})$. To the best of our knowledge, we are the first to show the near-optimal sample complexity in the PAC setting and $\widetilde O(\sqrt{{poly}(r)(S+K)T})$ minimax regret in the online setting for this problem. We also show our algorithms can be applied to more general low-rank bandits and get improved regret bounds in some scenarios.
Sequential Best-Arm Identification with Application to Brain-Computer Interface
May 17, 2023A brain-computer interface (BCI) is a technology that enables direct communication between the brain and an external device or computer system. It allows individuals to interact with the device using only their thoughts, and holds immense potential for a wide range of applications in medicine, rehabilitation, and human augmentation. An electroencephalogram (EEG) and event-related potential (ERP)-based speller system is a type of BCI that allows users to spell words without using a physical keyboard, but instead by recording and interpreting brain signals under different stimulus presentation paradigms. Conventional non-adaptive paradigms treat each word selection independently, leading to a lengthy learning process. To improve the sampling efficiency, we cast the problem as a sequence of best-arm identification tasks in multi-armed bandits. Leveraging pre-trained large language models (LLMs), we utilize the prior knowledge learned from previous tasks to inform and facilitate subsequent tasks. To do so in a coherent way, we propose a sequential top-two Thompson sampling (STTS) algorithm under the fixed-confidence setting and the fixed-budget setting. We study the theoretical property of the proposed algorithm, and demonstrate its substantial empirical improvement through both synthetic data analysis as well as a P300 BCI speller simulator example.
A Second-Order Method for Stochastic Bandit Convex Optimisation
Feb 10, 2023

We introduce a simple and efficient algorithm for unconstrained zeroth-order stochastic convex bandits and prove its regret is at most $(1 + r/d)[d^{1.5} \sqrt{n} + d^3] polylog(n, d, r)$ where $n$ is the horizon, $d$ the dimension and $r$ is the radius of a known ball containing the minimiser of the loss.
Leveraging Demonstrations to Improve Online Learning: Quality Matters
Feb 08, 2023



We investigate the extent to which offline demonstration data can improve online learning. It is natural to expect some improvement, but the question is how, and by how much? We show that the degree of improvement must depend on the quality of the demonstration data. To generate portable insights, we focus on Thompson sampling (TS) applied to a multi-armed bandit as a prototypical online learning algorithm and model. The demonstration data is generated by an expert with a given competence level, a notion we introduce. We propose an informed TS algorithm that utilizes the demonstration data in a coherent way through Bayes' rule and derive a prior-dependent Bayesian regret bound. This offers insight into how pretraining can greatly improve online performance and how the degree of improvement increases with the expert's competence level. We also develop a practical, approximate informed TS algorithm through Bayesian bootstrapping and show substantial empirical regret reduction through experiments.