 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrontier LLMs Still Struggle with Simple Reasoning Tasks
Jul 09, 2025
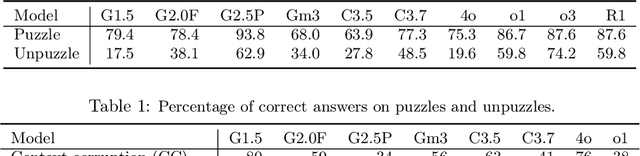
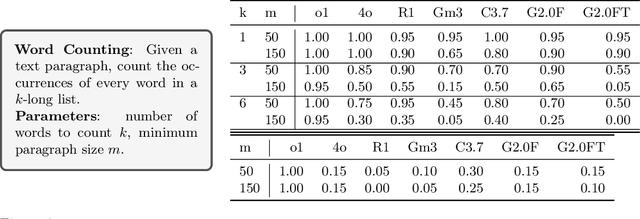
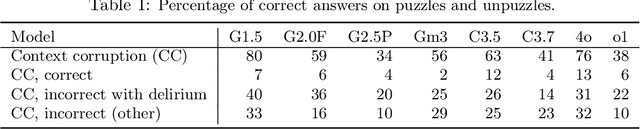
While state-of-the-art large language models (LLMs) demonstrate advanced reasoning capabilities-achieving remarkable performance on challenging competitive math and coding benchmarks-they also frequently fail on tasks that are easy for humans. This work studies the performance of frontier LLMs on a broad set of such "easy" reasoning problems. By extending previous work in the literature, we create a suite of procedurally generated simple reasoning tasks, including counting, first-order logic, proof trees, and travel planning, with changeable parameters (such as document length. or the number of variables in a math problem) that can arbitrarily increase the amount of computation required to produce the answer while preserving the fundamental difficulty. While previous work showed that traditional, non-thinking models can be made to fail on such problems, we demonstrate that even state-of-the-art thinking models consistently fail on such problems and for similar reasons (e.g. statistical shortcuts, errors in intermediate steps, and difficulties in processing long contexts). To further understand the behavior of the models, we introduce the unpuzzles dataset, a different "easy" benchmark consisting of trivialized versions of well-known math and logic puzzles. Interestingly, while modern LLMs excel at solving the original puzzles, they tend to fail on the trivialized versions, exhibiting several systematic failure patterns related to memorizing the originals. We show that this happens even if the models are otherwise able to solve problems with different descriptions but requiring the same logic. Our results highlight that out-of-distribution generalization is still problematic for frontier language models and the new generation of thinking models, even for simple reasoning tasks, and making tasks easier does not necessarily imply improved performance.
DataRater: Meta-Learned Dataset Curation
May 23, 2025The quality of foundation models depends heavily on their training data. Consequently, great efforts have been put into dataset curation. Yet most approaches rely on manual tuning of coarse-grained mixtures of large buckets of data, or filtering by hand-crafted heuristics. An approach that is ultimately more scalable (let alone more satisfying) is to \emph{learn} which data is actually valuable for training. This type of meta-learning could allow more sophisticated, fine-grained, and effective curation. Our proposed \emph{DataRater} is an instance of this idea. It estimates the value of training on any particular data point. This is done by meta-learning using `meta-gradients', with the objective of improving training efficiency on held out data. In extensive experiments across a range of model scales and datasets, we find that using our DataRater to filter data is highly effective, resulting in significantly improved compute efficiency.
Gemma 3 Technical Report
Mar 25, 2025We introduce Gemma 3, a multimodal addition to the Gemma family of lightweight open models, ranging in scale from 1 to 27 billion parameters. This version introduces vision understanding abilities, a wider coverage of languages and longer context - at least 128K tokens. We also change the architecture of the model to reduce the KV-cache memory that tends to explode with long context. This is achieved by increasing the ratio of local to global attention layers, and keeping the span on local attention short. The Gemma 3 models are trained with distillation and achieve superior performance to Gemma 2 for both pre-trained and instruction finetuned versions. In particular, our novel post-training recipe significantly improves the math, chat, instruction-following and multilingual abilities, making Gemma3-4B-IT competitive with Gemma2-27B-IT and Gemma3-27B-IT comparable to Gemini-1.5-Pro across benchmarks. We release all our models to the community.
A Scalable Crawling Algorithm Utilizing Noisy Change-Indicating Signals
Feb 04, 2025Web refresh crawling is the problem of keeping a cache of web pages fresh, that is, having the most recent copy available when a page is requested, given a limited bandwidth available to the crawler. Under the assumption that the change and request events, resp., to each web page follow independent Poisson processes, the optimal scheduling policy was derived by Azar et al. 2018. In this paper, we study an extension of this problem where side information indicating content changes, such as various types of web pings, for example, signals from sitemaps, content delivery networks, etc., is available. Incorporating such side information into the crawling policy is challenging, because (i) the signals can be noisy with false positive events and with missing change events; and (ii) the crawler should achieve a fair performance over web pages regardless of the quality of the side information, which might differ from web page to web page. We propose a scalable crawling algorithm which (i) uses the noisy side information in an optimal way under mild assumptions; (ii) can be deployed without heavy centralized computation; (iii) is able to crawl web pages at a constant total rate without spikes in the total bandwidth usage over any time interval, and automatically adapt to the new optimal solution when the total bandwidth changes without centralized computation. Experiments clearly demonstrate the versatility of our approach.
Non-Stationary Learning of Neural Networks with Automatic Soft Parameter Reset
Nov 06, 2024



Neural networks are traditionally trained under the assumption that data come from a stationary distribution. However, settings which violate this assumption are becoming more popular; examples include supervised learning under distributional shifts, reinforcement learning, continual learning and non-stationary contextual bandits. In this work we introduce a novel learning approach that automatically models and adapts to non-stationarity, via an Ornstein-Uhlenbeck process with an adaptive drift parameter. The adaptive drift tends to draw the parameters towards the initialisation distribution, so the approach can be understood as a form of soft parameter reset. We show empirically that our approach performs well in non-stationary supervised and off-policy reinforcement learning settings.
Toward Understanding In-context vs. In-weight Learning
Oct 30, 2024It has recently been demonstrated empirically that in-context learning emerges in transformers when certain distributional properties are present in the training data, but this ability can also diminish upon further training. We provide a new theoretical understanding of these phenomena by identifying simplified distributional properties that give rise to the emergence and eventual disappearance of in-context learning. We do so by first analyzing a simplified model that uses a gating mechanism to choose between an in-weight and an in-context predictor. Through a combination of a generalization error and regret analysis we identify conditions where in-context and in-weight learning emerge. These theoretical findings are then corroborated experimentally by comparing the behaviour of a full transformer on the simplified distributions to that of the stylized model, demonstrating aligned results. We then extend the study to a full large language model, showing how fine-tuning on various collections of natural language prompts can elicit similar in-context and in-weight learning behaviour.
Learning Continually by Spectral Regularization
Jun 10, 2024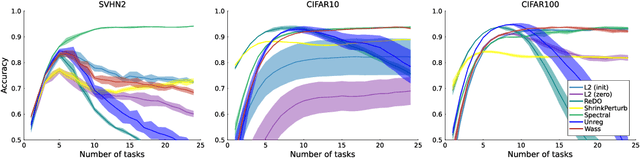

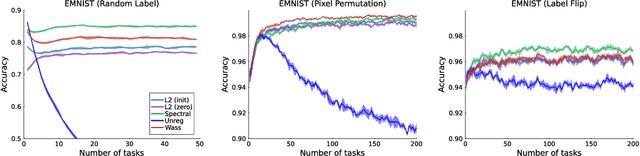
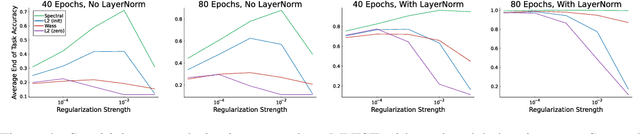
Loss of plasticity is a phenomenon where neural networks become more difficult to train during the course of learning. Continual learning algorithms seek to mitigate this effect by sustaining good predictive performance while maintaining network trainability. We develop new techniques for improving continual learning by first reconsidering how initialization can ensure trainability during early phases of learning. From this perspective, we derive new regularization strategies for continual learning that ensure beneficial initialization properties are better maintained throughout training. In particular, we investigate two new regularization techniques for continual learning: (i) Wasserstein regularization toward the initial weight distribution, which is less restrictive than regularizing toward initial weights; and (ii) regularizing weight matrix singular values, which directly ensures gradient diversity is maintained throughout training. We present an experimental analysis that shows these alternative regularizers can improve continual learning performance across a range of supervised learning tasks and model architectures. The alternative regularizers prove to be less sensitive to hyperparameters while demonstrating better training in individual tasks, sustaining trainability as new tasks arrive, and achieving better generalization performance.
Prior-Dependent Allocations for Bayesian Fixed-Budget Best-Arm Identification in Structured Bandits
Feb 08, 2024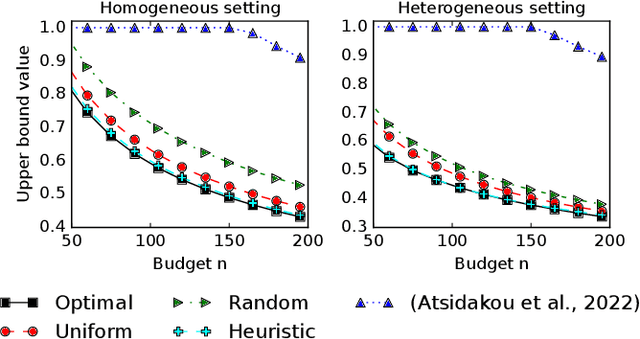
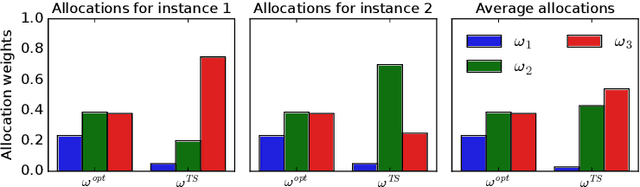
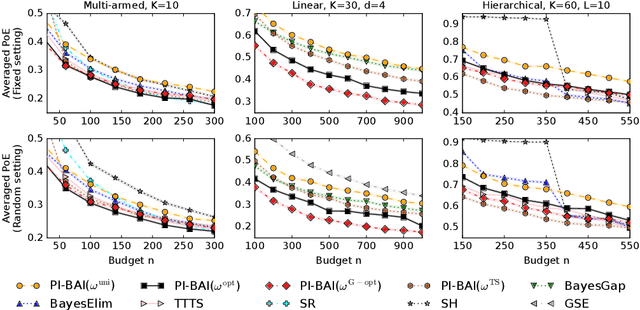
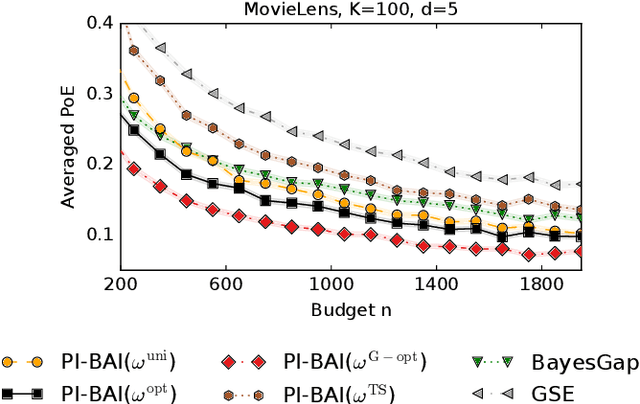
We study the problem of Bayesian fixed-budget best-arm identification (BAI) in structured bandits. We propose an algorithm that uses fixed allocations based on the prior information and the structure of the environment. We provide theoretical bounds on its performance across diverse models, including the first prior-dependent upper bounds for linear and hierarchical BAI. Our key contribution is introducing new proof methods that result in tighter bounds for multi-armed BAI compared to existing methods. We extensively compare our approach to other fixed-budget BAI methods, demonstrating its consistent and robust performance in various settings. Our work improves our understanding of Bayesian fixed-budget BAI in structured bandits and highlights the effectiveness of our approach in practical scenarios.
Online RL in Linearly $q^π$-Realizable MDPs Is as Easy as in Linear MDPs If You Learn What to Ignore
Oct 11, 2023
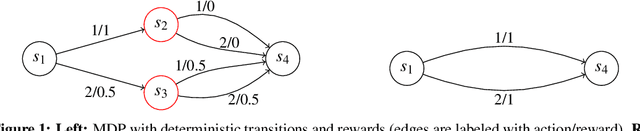
We consider online reinforcement learning (RL) in episodic Markov decision processes (MDPs) under the linear $q^\pi$-realizability assumption, where it is assumed that the action-values of all policies can be expressed as linear functions of state-action features. This class is known to be more general than linear MDPs, where the transition kernel and the reward function are assumed to be linear functions of the feature vectors. As our first contribution, we show that the difference between the two classes is the presence of states in linearly $q^\pi$-realizable MDPs where for any policy, all the actions have approximately equal values, and skipping over these states by following an arbitrarily fixed policy in those states transforms the problem to a linear MDP. Based on this observation, we derive a novel (computationally inefficient) learning algorithm for linearly $q^\pi$-realizable MDPs that simultaneously learns what states should be skipped over and runs another learning algorithm on the linear MDP hidden in the problem. The method returns an $\epsilon$-optimal policy after $\text{polylog}(H, d)/\epsilon^2$ interactions with the MDP, where $H$ is the time horizon and $d$ is the dimension of the feature vectors, giving the first polynomial-sample-complexity online RL algorithm for this setting. The results are proved for the misspecified case, where the sample complexity is shown to degrade gracefully with the misspecification error.
Optimistic Natural Policy Gradient: a Simple Efficient Policy Optimization Framework for Online RL
May 18, 2023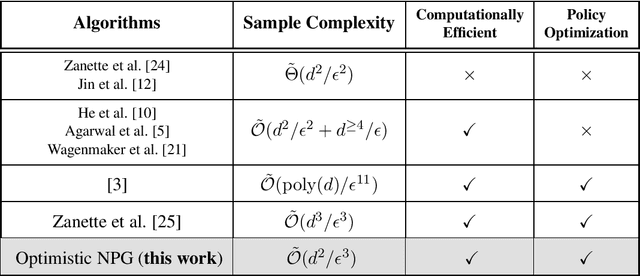
While policy optimization algorithms have played an important role in recent empirical success of Reinforcement Learning (RL), the existing theoretical understanding of policy optimization remains rather limited -- they are either restricted to tabular MDPs or suffer from highly suboptimal sample complexity, especial in online RL where exploration is necessary. This paper proposes a simple efficient policy optimization framework -- Optimistic NPG for online RL. Optimistic NPG can be viewed as simply combining of the classic natural policy gradient (NPG) algorithm [Kakade, 2001] with optimistic policy evaluation subroutines to encourage exploration. For $d$-dimensional linear MDPs, Optimistic NPG is computationally efficient, and learns an $\varepsilon$-optimal policy within $\tilde{O}(d^2/\varepsilon^3)$ samples, which is the first computationally efficient algorithm whose sample complexity has the optimal dimension dependence $\tilde{\Theta}(d^2)$. It also improves over state-of-the-art results of policy optimization algorithms [Zanette et al., 2021] by a factor of $d$. For general function approximation that subsumes linear MDPs, Optimistic NPG, to our best knowledge, is also the first policy optimization algorithm that achieves the polynomial sample complexity for learning near-optimal policies.