 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaximum Likelihood Learning of Latent Dynamics Without Reconstruction
May 29, 2025We introduce a novel unsupervised learning method for time series data with latent dynamical structure: the recognition-parametrized Gaussian state space model (RP-GSSM). The RP-GSSM is a probabilistic model that learns Markovian Gaussian latents explaining statistical dependence between observations at different time steps, combining the intuition of contrastive methods with the flexible tools of probabilistic generative models. Unlike contrastive approaches, the RP-GSSM is a valid probabilistic model learned via maximum likelihood. Unlike generative approaches, the RP-GSSM has no need for an explicit network mapping from latents to observations, allowing it to focus model capacity on inference of latents. The model is both tractable and expressive: it admits exact inference thanks to its jointly Gaussian latent prior, while maintaining expressivity with an arbitrarily nonlinear neural network link between observations and latents. These qualities allow the RP-GSSM to learn task-relevant latents without ad-hoc regularization, auxiliary losses, or optimizer scheduling. We show how this approach outperforms alternatives on problems that include learning nonlinear stochastic dynamics from video, with or without background distractors. Our results position the RP-GSSM as a useful foundation model for a variety of downstream applications.
Non-Stationary Learning of Neural Networks with Automatic Soft Parameter Reset
Nov 06, 2024



Neural networks are traditionally trained under the assumption that data come from a stationary distribution. However, settings which violate this assumption are becoming more popular; examples include supervised learning under distributional shifts, reinforcement learning, continual learning and non-stationary contextual bandits. In this work we introduce a novel learning approach that automatically models and adapts to non-stationarity, via an Ornstein-Uhlenbeck process with an adaptive drift parameter. The adaptive drift tends to draw the parameters towards the initialisation distribution, so the approach can be understood as a form of soft parameter reset. We show empirically that our approach performs well in non-stationary supervised and off-policy reinforcement learning settings.
A solution for the mean parametrization of the von Mises-Fisher distribution
Apr 10, 2024The von Mises-Fisher distribution as an exponential family can be expressed in terms of either its natural or its mean parameters. Unfortunately, however, the normalization function for the distribution in terms of its mean parameters is not available in closed form, limiting the practicality of the mean parametrization and complicating maximum-likelihood estimation more generally. We derive a second-order ordinary differential equation, the solution to which yields the mean-parameter normalizer along with its first two derivatives, as well as the variance function of the family. We also provide closed-form approximations to the solution of the differential equation. This allows rapid evaluation of both densities and natural parameters in terms of mean parameters. We show applications to topic modeling with mixtures of von Mises-Fisher distributions using Bregman Clustering.
A State Representation for Diminishing Rewards
Sep 07, 2023A common setting in multitask reinforcement learning (RL) demands that an agent rapidly adapt to various stationary reward functions randomly sampled from a fixed distribution. In such situations, the successor representation (SR) is a popular framework which supports rapid policy evaluation by decoupling a policy's expected discounted, cumulative state occupancies from a specific reward function. However, in the natural world, sequential tasks are rarely independent, and instead reflect shifting priorities based on the availability and subjective perception of rewarding stimuli. Reflecting this disjunction, in this paper we study the phenomenon of diminishing marginal utility and introduce a novel state representation, the $\lambda$ representation ($\lambda$R) which, surprisingly, is required for policy evaluation in this setting and which generalizes the SR as well as several other state representations from the literature. We establish the $\lambda$R's formal properties and examine its normative advantages in the context of machine learning, as well as its usefulness for studying natural behaviors, particularly foraging.
Prediction under Latent Subgroup Shifts with High-Dimensional Observations
Jun 23, 2023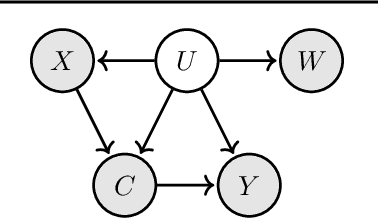
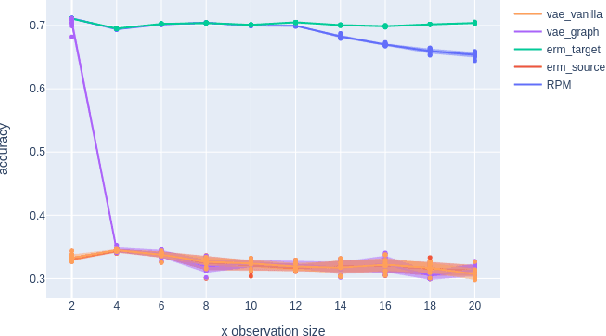
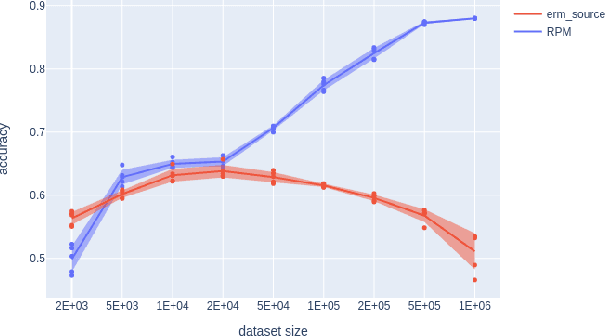
We introduce a new approach to prediction in graphical models with latent-shift adaptation, i.e., where source and target environments differ in the distribution of an unobserved confounding latent variable. Previous work has shown that as long as "concept" and "proxy" variables with appropriate dependence are observed in the source environment, the latent-associated distributional changes can be identified, and target predictions adapted accurately. However, practical estimation methods do not scale well when the observations are complex and high-dimensional, even if the confounding latent is categorical. Here we build upon a recently proposed probabilistic unsupervised learning framework, the recognition-parametrised model (RPM), to recover low-dimensional, discrete latents from image observations. Applied to the problem of latent shifts, our novel form of RPM identifies causal latent structure in the source environment, and adapts properly to predict in the target. We demonstrate results in settings where predictor and proxy are high-dimensional images, a context to which previous methods fail to scale.
Successor-Predecessor Intrinsic Exploration
May 24, 2023Exploration is essential in reinforcement learning, particularly in environments where external rewards are sparse. Here we focus on exploration with intrinsic rewards, where the agent transiently augments the external rewards with self-generated intrinsic rewards. Although the study of intrinsic rewards has a long history, existing methods focus on composing the intrinsic reward based on measures of future prospects of states, ignoring the information contained in the retrospective structure of transition sequences. Here we argue that the agent can utilise retrospective information to generate explorative behaviour with structure-awareness, facilitating efficient exploration based on global instead of local information. We propose Successor-Predecessor Intrinsic Exploration (SPIE), an exploration algorithm based on a novel intrinsic reward combining prospective and retrospective information. We show that SPIE yields more efficient and ethologically plausible exploratory behaviour in environments with sparse rewards and bottleneck states than competing methods. We also implement SPIE in deep reinforcement learning agents, and show that the resulting agent achieves stronger empirical performance than existing methods on sparse-reward Atari games.
Unsupervised representational learning with recognition-parametrised probabilistic models
Sep 13, 2022
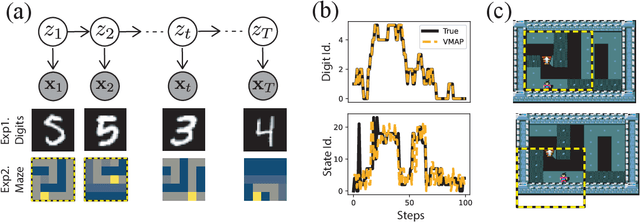

We introduce a new approach to probabilistic unsupervised learning based on the recognition-parametrised model (RPM): a normalised semi-parametric hypothesis class for joint distributions over observed and latent variables. Under the key assumption that observations are conditionally independent given the latents, RPMs directly encode the "recognition" process, parametrising both the prior distribution on the latents and their conditional distributions given observations. This recognition model is paired with non-parametric descriptions of the marginal distribution of each observed variable. Thus, the focus is on learning a good latent representation that captures dependence between the measurements. The RPM permits exact maximum likelihood learning in settings with discrete latents and a tractable prior, even when the mapping between continuous observations and the latents is expressed through a flexible model such as a neural network. We develop effective approximations for the case of continuous latent variables with tractable priors. Unlike the approximations necessary in dual-parametrised models such as Helmholtz machines and variational autoencoders, these RPM approximations introduce only minor bias, which may often vanish asymptotically. Furthermore, where the prior on latents is intractable the RPM may be combined effectively with standard probabilistic techniques such as variational Bayes. We demonstrate the model in high dimensional data settings, including a form of weakly supervised learning on MNIST digits and the discovery of latent maps from sensory observations. The RPM provides an effective way to discover, represent and reason probabilistically about the latent structure underlying observational data, functions which are critical to both animal and artificial intelligence.
Amortised Inference in Structured Generative Models with Explaining Away
Sep 12, 2022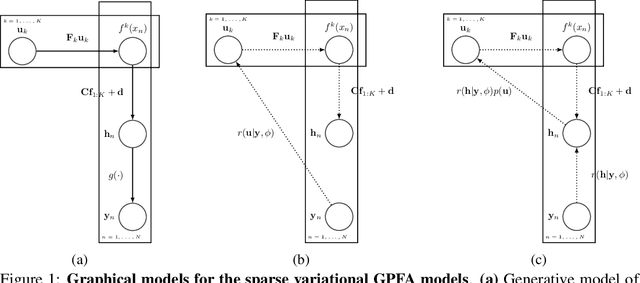
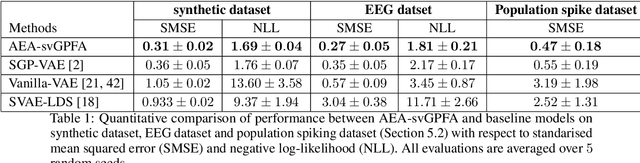
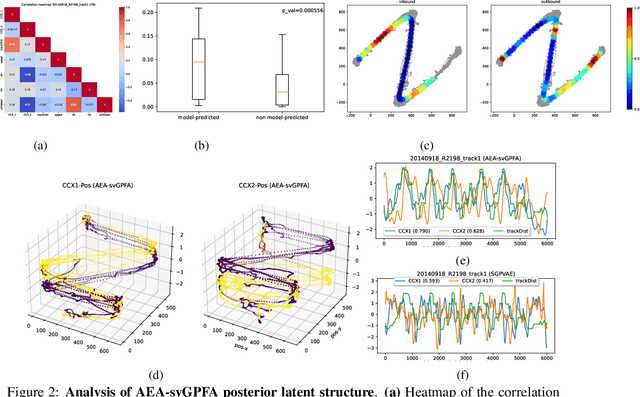
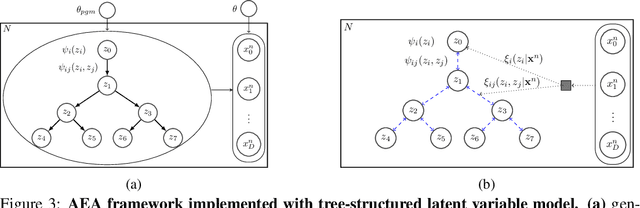
A key goal of unsupervised learning is to go beyond density estimation and sample generation to reveal the structure inherent within observed data. Such structure can be expressed in the pattern of interactions between explanatory latent variables captured through a probabilistic graphical model. Although the learning of structured graphical models has a long history, much recent work in unsupervised modelling has instead emphasised flexible deep-network-based generation, either transforming independent latent generators to model complex data or assuming that distinct observed variables are derived from different latent nodes. Here, we extend the output of amortised variational inference to incorporate structured factors over multiple variables, able to capture the observation-induced posterior dependence between latents that results from "explaining away" and thus allow complex observations to depend on multiple nodes of a structured graph. We show that appropriately parameterised factors can be combined efficiently with variational message passing in elaborate graphical structures. We instantiate the framework based on Gaussian Process Factor Analysis models, and empirically evaluate its improvement over existing methods on synthetic data with known generative processes. We then fit the structured model to high-dimensional neural spiking time-series from the hippocampus of freely moving rodents, demonstrating that the model identifies latent signals that correlate with behavioural covariates.
Minimum Description Length Control
Jul 24, 2022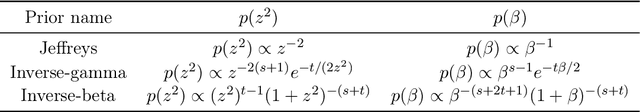

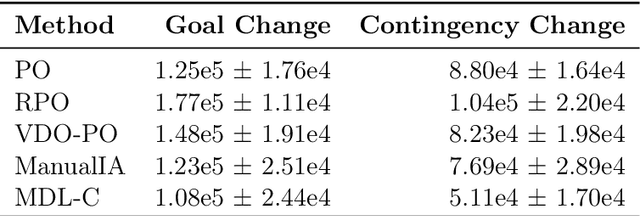

We propose a novel framework for multitask reinforcement learning based on the minimum description length (MDL) principle. In this approach, which we term MDL-control (MDL-C), the agent learns the common structure among the tasks with which it is faced and then distills it into a simpler representation which facilitates faster convergence and generalization to new tasks. In doing so, MDL-C naturally balances adaptation to each task with epistemic uncertainty about the task distribution. We motivate MDL-C via formal connections between the MDL principle and Bayesian inference, derive theoretical performance guarantees, and demonstrate MDL-C's empirical effectiveness on both discrete and high-dimensional continuous control tasks.
Divergent representations of ethological visual inputs emerge from supervised, unsupervised, and reinforcement learning
Dec 03, 2021



Artificial neural systems trained using reinforcement, supervised, and unsupervised learning all acquire internal representations of high dimensional input. To what extent these representations depend on the different learning objectives is largely unknown. Here we compare the representations learned by eight different convolutional neural networks, each with identical ResNet architectures and trained on the same family of egocentric images, but embedded within different learning systems. Specifically, the representations are trained to guide action in a compound reinforcement learning task; to predict one or a combination of three task-related targets with supervision; or using one of three different unsupervised objectives. Using representational similarity analysis, we find that the network trained with reinforcement learning differs most from the other networks. Through further analysis using metrics inspired by the neuroscience literature, we find that the model trained with reinforcement learning has a sparse and high-dimensional representation wherein individual images are represented with very different patterns of neural activity. Further analysis suggests these representations may arise in order to guide long-term behavior and goal-seeking in the RL agent. Our results provide insights into how the properties of neural representations are influenced by objective functions and can inform transfer learning approaches.