 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow should the advent of large language models affect the practice of science?
Dec 05, 2023Large language models (LLMs) are being increasingly incorporated into scientific workflows. However, we have yet to fully grasp the implications of this integration. How should the advent of large language models affect the practice of science? For this opinion piece, we have invited four diverse groups of scientists to reflect on this query, sharing their perspectives and engaging in debate. Schulz et al. make the argument that working with LLMs is not fundamentally different from working with human collaborators, while Bender et al. argue that LLMs are often misused and over-hyped, and that their limitations warrant a focus on more specialized, easily interpretable tools. Marelli et al. emphasize the importance of transparent attribution and responsible use of LLMs. Finally, Botvinick and Gershman advocate that humans should retain responsibility for determining the scientific roadmap. To facilitate the discussion, the four perspectives are complemented with a response from each group. By putting these different perspectives in conversation, we aim to bring attention to important considerations within the academic community regarding the adoption of LLMs and their impact on both current and future scientific practices.
Fine-tuning language models to find agreement among humans with diverse preferences
Nov 28, 2022
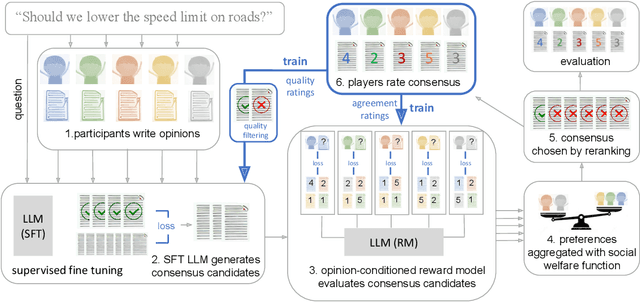
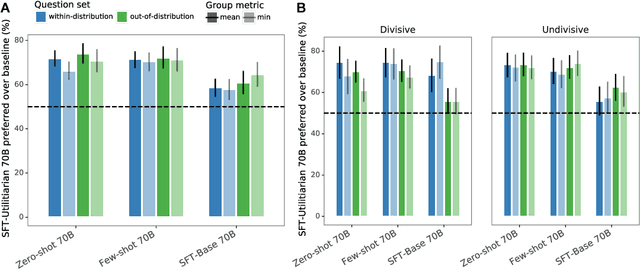
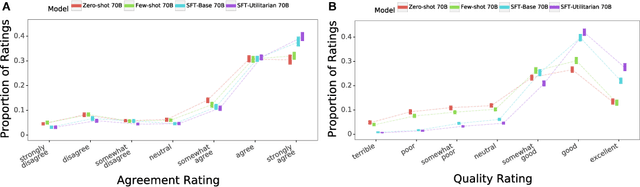
Recent work in large language modeling (LLMs) has used fine-tuning to align outputs with the preferences of a prototypical user. This work assumes that human preferences are static and homogeneous across individuals, so that aligning to a a single "generic" user will confer more general alignment. Here, we embrace the heterogeneity of human preferences to consider a different challenge: how might a machine help people with diverse views find agreement? We fine-tune a 70 billion parameter LLM to generate statements that maximize the expected approval for a group of people with potentially diverse opinions. Human participants provide written opinions on thousands of questions touching on moral and political issues (e.g., "should we raise taxes on the rich?"), and rate the LLM's generated candidate consensus statements for agreement and quality. A reward model is then trained to predict individual preferences, enabling it to quantify and rank consensus statements in terms of their appeal to the overall group, defined according to different aggregation (social welfare) functions. The model produces consensus statements that are preferred by human users over those from prompted LLMs (>70%) and significantly outperforms a tight fine-tuned baseline that lacks the final ranking step. Further, our best model's consensus statements are preferred over the best human-generated opinions (>65%). We find that when we silently constructed consensus statements from only a subset of group members, those who were excluded were more likely to dissent, revealing the sensitivity of the consensus to individual contributions. These results highlight the potential to use LLMs to help groups of humans align their values with one another.
Adaptive patch foraging in deep reinforcement learning agents
Oct 14, 2022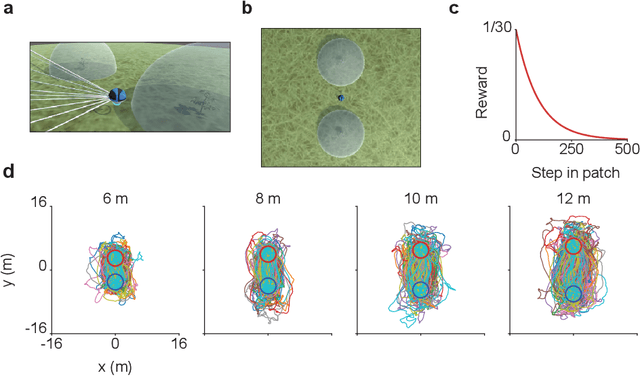

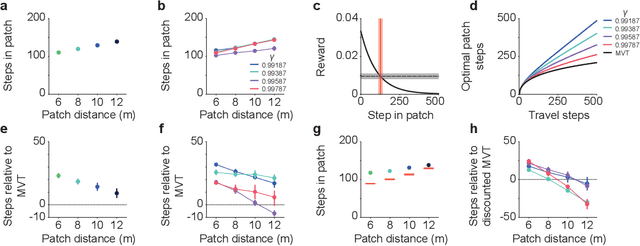
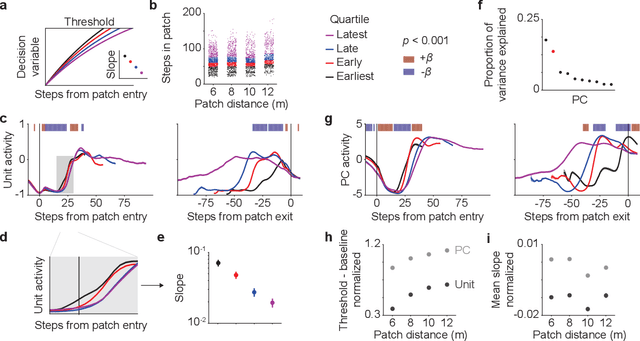
Patch foraging is one of the most heavily studied behavioral optimization challenges in biology. However, despite its importance to biological intelligence, this behavioral optimization problem is understudied in artificial intelligence research. Patch foraging is especially amenable to study given that it has a known optimal solution, which may be difficult to discover given current techniques in deep reinforcement learning. Here, we investigate deep reinforcement learning agents in an ecological patch foraging task. For the first time, we show that machine learning agents can learn to patch forage adaptively in patterns similar to biological foragers, and approach optimal patch foraging behavior when accounting for temporal discounting. Finally, we show emergent internal dynamics in these agents that resemble single-cell recordings from foraging non-human primates, which complements experimental and theoretical work on the neural mechanisms of biological foraging. This work suggests that agents interacting in complex environments with ecologically valid pressures arrive at common solutions, suggesting the emergence of foundational computations behind adaptive, intelligent behavior in both biological and artificial agents.
Minimum Description Length Control
Jul 24, 2022

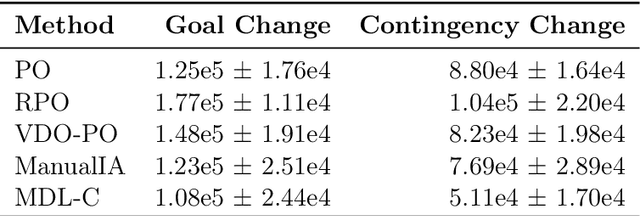

We propose a novel framework for multitask reinforcement learning based on the minimum description length (MDL) principle. In this approach, which we term MDL-control (MDL-C), the agent learns the common structure among the tasks with which it is faced and then distills it into a simpler representation which facilitates faster convergence and generalization to new tasks. In doing so, MDL-C naturally balances adaptation to each task with epistemic uncertainty about the task distribution. We motivate MDL-C via formal connections between the MDL principle and Bayesian inference, derive theoretical performance guarantees, and demonstrate MDL-C's empirical effectiveness on both discrete and high-dimensional continuous control tasks.
The Frost Hollow Experiments: Pavlovian Signalling as a Path to Coordination and Communication Between Agents
Mar 17, 2022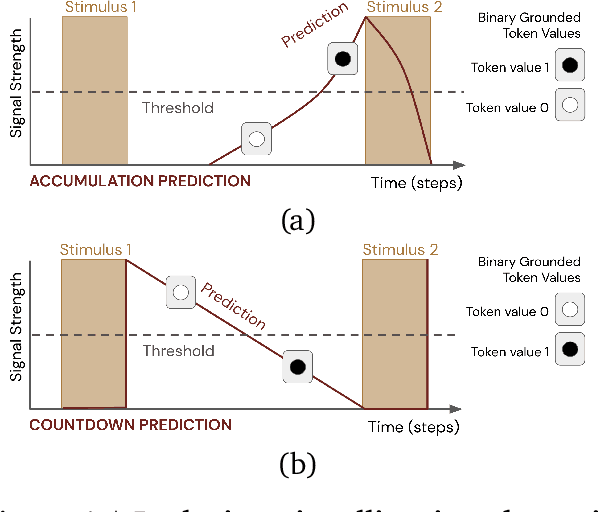

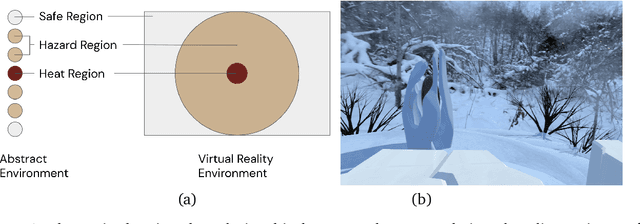
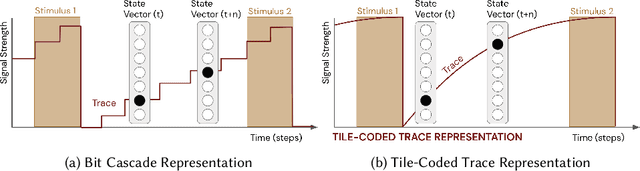
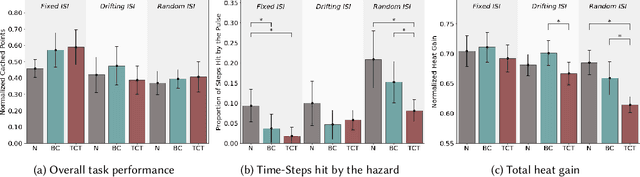
Learned communication between agents is a powerful tool when approaching decision-making problems that are hard to overcome by any single agent in isolation. However, continual coordination and communication learning between machine agents or human-machine partnerships remains a challenging open problem. As a stepping stone toward solving the continual communication learning problem, in this paper we contribute a multi-faceted study into what we term Pavlovian signalling -- a process by which learned, temporally extended predictions made by one agent inform decision-making by another agent with different perceptual access to their shared environment. We seek to establish how different temporal processes and representational choices impact Pavlovian signalling between learning agents. To do so, we introduce a partially observable decision-making domain we call the Frost Hollow. In this domain a prediction learning agent and a reinforcement learning agent are coupled into a two-part decision-making system that seeks to acquire sparse reward while avoiding time-conditional hazards. We evaluate two domain variations: 1) machine prediction and control learning in a linear walk, and 2) a prediction learning machine interacting with a human participant in a virtual reality environment. Our results showcase the speed of learning for Pavlovian signalling, the impact that different temporal representations do (and do not) have on agent-agent coordination, and how temporal aliasing impacts agent-agent and human-agent interactions differently. As a main contribution, we establish Pavlovian signalling as a natural bridge between fixed signalling paradigms and fully adaptive communication learning. Our results therefore point to an actionable, constructivist path towards continual communication learning between reinforcement learning agents, with potential impact in a range of real-world settings.
Assessing Human Interaction in Virtual Reality With Continually Learning Prediction Agents Based on Reinforcement Learning Algorithms: A Pilot Study
Dec 14, 2021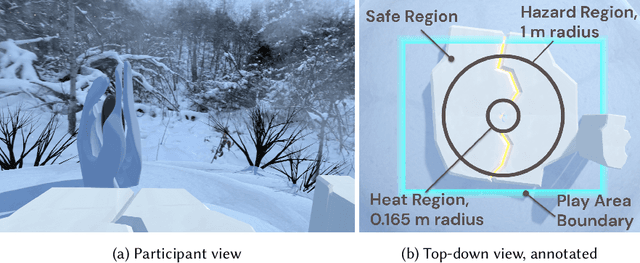
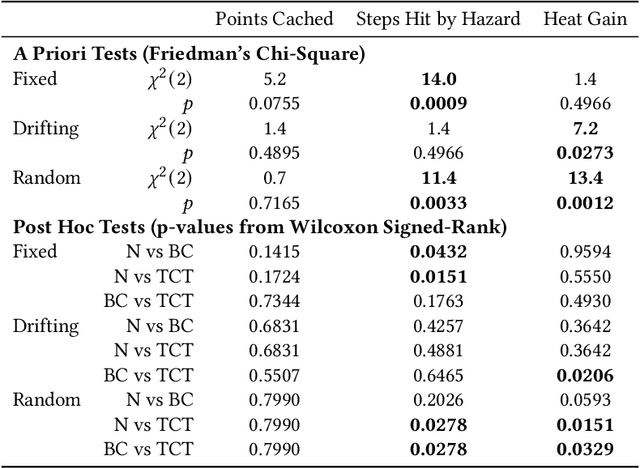
Artificial intelligence systems increasingly involve continual learning to enable flexibility in general situations that are not encountered during system training. Human interaction with autonomous systems is broadly studied, but research has hitherto under-explored interactions that occur while the system is actively learning, and can noticeably change its behaviour in minutes. In this pilot study, we investigate how the interaction between a human and a continually learning prediction agent develops as the agent develops competency. Additionally, we compare two different agent architectures to assess how representational choices in agent design affect the human-agent interaction. We develop a virtual reality environment and a time-based prediction task wherein learned predictions from a reinforcement learning (RL) algorithm augment human predictions. We assess how a participant's performance and behaviour in this task differs across agent types, using both quantitative and qualitative analyses. Our findings suggest that human trust of the system may be influenced by early interactions with the agent, and that trust in turn affects strategic behaviour, but limitations of the pilot study rule out any conclusive statement. We identify trust as a key feature of interaction to focus on when considering RL-based technologies, and make several recommendations for modification to this study in preparation for a larger-scale investigation. A video summary of this paper can be found at https://youtu.be/oVYJdnBqTwQ .
Perceiver IO: A General Architecture for Structured Inputs & Outputs
Aug 02, 2021
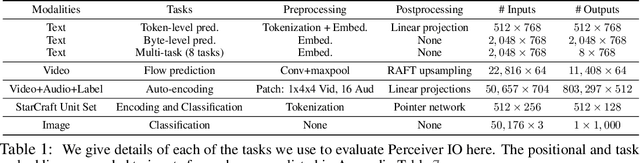
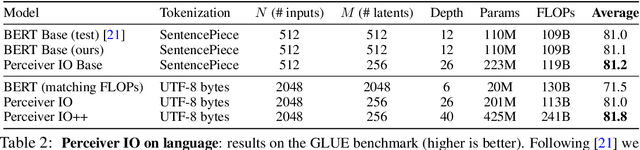
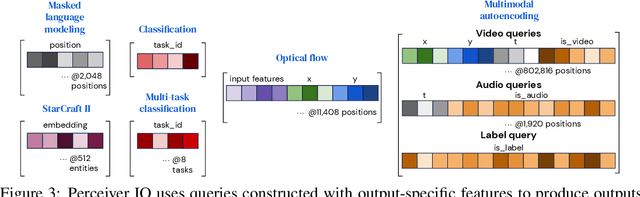
The recently-proposed Perceiver model obtains good results on several domains (images, audio, multimodal, point clouds) while scaling linearly in compute and memory with the input size. While the Perceiver supports many kinds of inputs, it can only produce very simple outputs such as class scores. Perceiver IO overcomes this limitation without sacrificing the original's appealing properties by learning to flexibly query the model's latent space to produce outputs of arbitrary size and semantics. Perceiver IO still decouples model depth from data size and still scales linearly with data size, but now with respect to both input and output sizes. The full Perceiver IO model achieves strong results on tasks with highly structured output spaces, such as natural language and visual understanding, StarCraft II, and multi-task and multi-modal domains. As highlights, Perceiver IO matches a Transformer-based BERT baseline on the GLUE language benchmark without the need for input tokenization and achieves state-of-the-art performance on Sintel optical flow estimation.
Stabilizing Transformers for Reinforcement Learning
Oct 13, 2019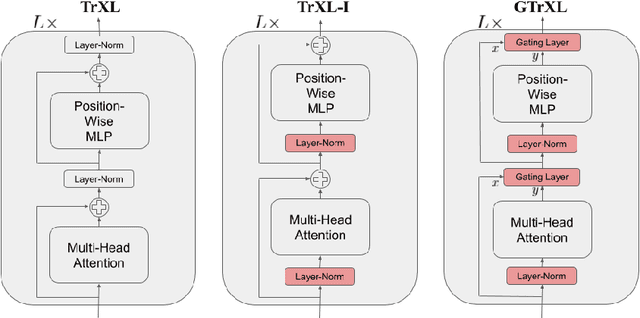
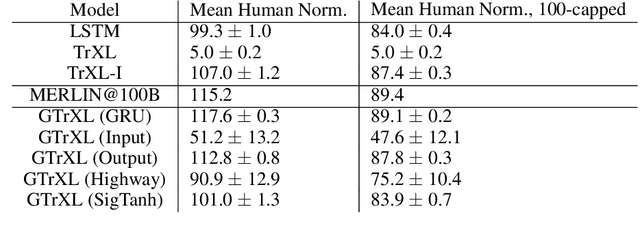
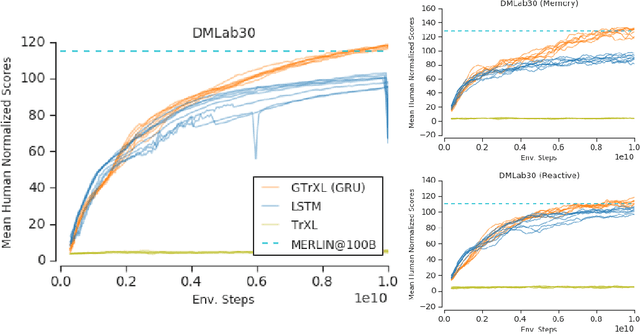
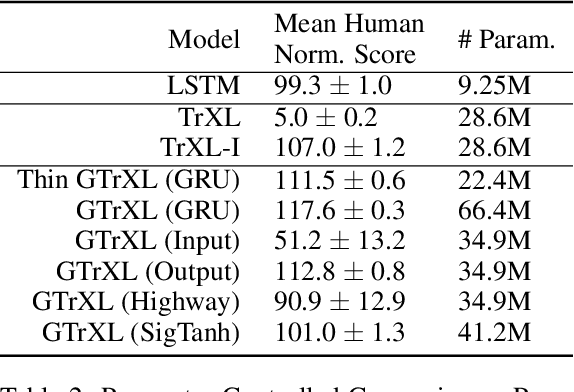
Owing to their ability to both effectively integrate information over long time horizons and scale to massive amounts of data, self-attention architectures have recently shown breakthrough success in natural language processing (NLP), achieving state-of-the-art results in domains such as language modeling and machine translation. Harnessing the transformer's ability to process long time horizons of information could provide a similar performance boost in partially observable reinforcement learning (RL) domains, but the large-scale transformers used in NLP have yet to be successfully applied to the RL setting. In this work we demonstrate that the standard transformer architecture is difficult to optimize, which was previously observed in the supervised learning setting but becomes especially pronounced with RL objectives. We propose architectural modifications that substantially improve the stability and learning speed of the original Transformer and XL variant. The proposed architecture, the Gated Transformer-XL (GTrXL), surpasses LSTMs on challenging memory environments and achieves state-of-the-art results on the multi-task DMLab-30 benchmark suite, exceeding the performance of an external memory architecture. We show that the GTrXL, trained using the same losses, has stability and performance that consistently matches or exceeds a competitive LSTM baseline, including on more reactive tasks where memory is less critical. GTrXL offers an easy-to-train, simple-to-implement but substantially more expressive architectural alternative to the standard multi-layer LSTM ubiquitously used for RL agents in partially observable environments.
V-MPO: On-Policy Maximum a Posteriori Policy Optimization for Discrete and Continuous Control
Sep 26, 2019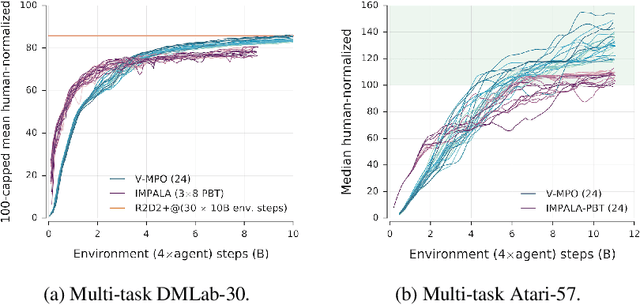
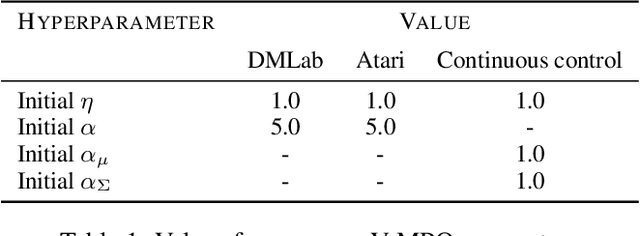
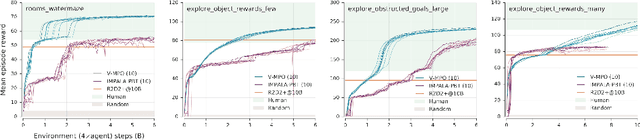

Some of the most successful applications of deep reinforcement learning to challenging domains in discrete and continuous control have used policy gradient methods in the on-policy setting. However, policy gradients can suffer from large variance that may limit performance, and in practice require carefully tuned entropy regularization to prevent policy collapse. As an alternative to policy gradient algorithms, we introduce V-MPO, an on-policy adaptation of Maximum a Posteriori Policy Optimization (MPO) that performs policy iteration based on a learned state-value function. We show that V-MPO surpasses previously reported scores for both the Atari-57 and DMLab-30 benchmark suites in the multi-task setting, and does so reliably without importance weighting, entropy regularization, or population-based tuning of hyperparameters. On individual DMLab and Atari levels, the proposed algorithm can achieve scores that are substantially higher than has previously been reported. V-MPO is also applicable to problems with high-dimensional, continuous action spaces, which we demonstrate in the context of learning to control simulated humanoids with 22 degrees of freedom from full state observations and 56 degrees of freedom from pixel observations, as well as example OpenAI Gym tasks where V-MPO achieves substantially higher asymptotic scores than previously reported.
Learned human-agent decision-making, communication and joint action in a virtual reality environment
May 07, 2019
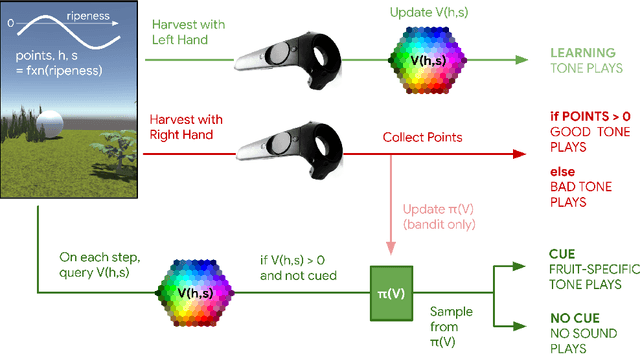
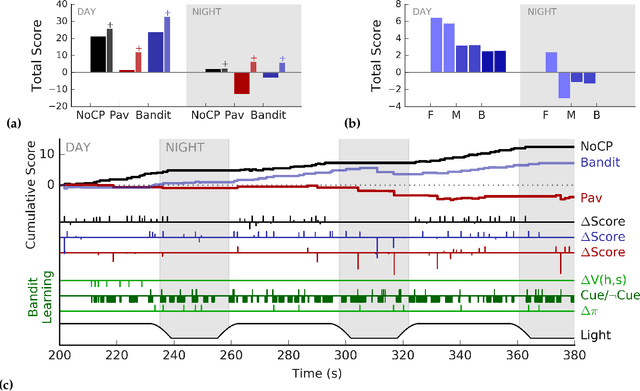
Humans make decisions and act alongside other humans to pursue both short-term and long-term goals. As a result of ongoing progress in areas such as computing science and automation, humans now also interact with non-human agents of varying complexity as part of their day-to-day activities; substantial work is being done to integrate increasingly intelligent machine agents into human work and play. With increases in the cognitive, sensory, and motor capacity of these agents, intelligent machinery for human assistance can now reasonably be considered to engage in joint action with humans---i.e., two or more agents adapting their behaviour and their understanding of each other so as to progress in shared objectives or goals. The mechanisms, conditions, and opportunities for skillful joint action in human-machine partnerships is of great interest to multiple communities. Despite this, human-machine joint action is as yet under-explored, especially in cases where a human and an intelligent machine interact in a persistent way during the course of real-time, daily-life experience. In this work, we contribute a virtual reality environment wherein a human and an agent can adapt their predictions, their actions, and their communication so as to pursue a simple foraging task. In a case study with a single participant, we provide an example of human-agent coordination and decision-making involving prediction learning on the part of the human and the machine agent, and control learning on the part of the machine agent wherein audio communication signals are used to cue its human partner in service of acquiring shared reward. These comparisons suggest the utility of studying human-machine coordination in a virtual reality environment, and identify further research that will expand our understanding of persistent human-machine joint action.