 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan AI mediation improve democratic deliberation?
Jan 09, 2026The strength of democracy lies in the free and equal exchange of diverse viewpoints. Living up to this ideal at scale faces inherent tensions: broad participation, meaningful deliberation, and political equality often trade off with one another (Fishkin, 2011). We ask whether and how artificial intelligence (AI) could help navigate this "trilemma" by engaging with a recent example of a large language model (LLM)-based system designed to help people with diverse viewpoints find common ground (Tessler, Bakker, et al., 2024). Here, we explore the implications of the introduction of LLMs into deliberation augmentation tools, examining their potential to enhance participation through scalability, improve political equality via fair mediation, and foster meaningful deliberation by, for example, surfacing trustworthy information. We also point to key challenges that remain. Ultimately, a range of empirical, technical, and theoretical advancements are needed to fully realize the promise of AI-mediated deliberation for enhancing citizen engagement and strengthening democratic deliberation.
Value Profiles for Encoding Human Variation
Mar 19, 2025Modelling human variation in rating tasks is crucial for enabling AI systems for personalization, pluralistic model alignment, and computational social science. We propose representing individuals using value profiles -- natural language descriptions of underlying values compressed from in-context demonstrations -- along with a steerable decoder model to estimate ratings conditioned on a value profile or other rater information. To measure the predictive information in rater representations, we introduce an information-theoretic methodology. We find that demonstrations contain the most information, followed by value profiles and then demographics. However, value profiles offer advantages in terms of scrutability, interpretability, and steerability due to their compressed natural language format. Value profiles effectively compress the useful information from demonstrations (>70% information preservation). Furthermore, clustering value profiles to identify similarly behaving individuals better explains rater variation than the most predictive demographic groupings. Going beyond test set performance, we show that the decoder models interpretably change ratings according to semantic profile differences, are well-calibrated, and can help explain instance-level disagreement by simulating an annotator population. These results demonstrate that value profiles offer novel, predictive ways to describe individual variation beyond demographics or group information.
Language Agents as Digital Representatives in Collective Decision-Making
Feb 13, 2025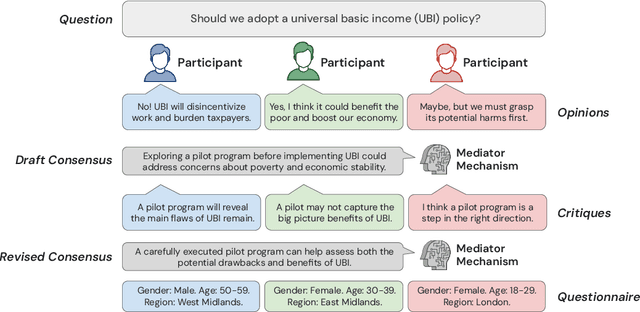

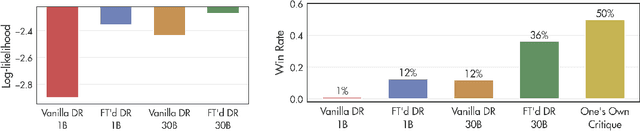
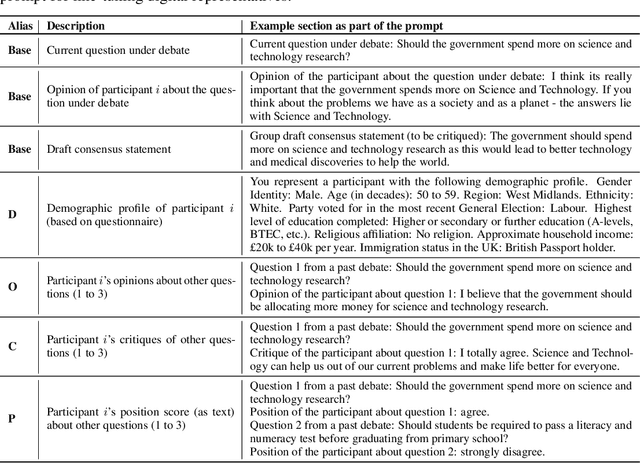
Consider the process of collective decision-making, in which a group of individuals interactively select a preferred outcome from among a universe of alternatives. In this context, "representation" is the activity of making an individual's preferences present in the process via participation by a proxy agent -- i.e. their "representative". To this end, learned models of human behavior have the potential to fill this role, with practical implications for multi-agent scenario studies and mechanism design. In this work, we investigate the possibility of training \textit{language agents} to behave in the capacity of representatives of human agents, appropriately expressing the preferences of those individuals whom they stand for. First, we formalize the setting of \textit{collective decision-making} -- as the episodic process of interaction between a group of agents and a decision mechanism. On this basis, we then formalize the problem of \textit{digital representation} -- as the simulation of an agent's behavior to yield equivalent outcomes from the mechanism. Finally, we conduct an empirical case study in the setting of \textit{consensus-finding} among diverse humans, and demonstrate the feasibility of fine-tuning large language models to act as digital representatives.
AI and the Future of Digital Public Squares
Dec 13, 2024



Two substantial technological advances have reshaped the public square in recent decades: first with the advent of the internet and second with the recent introduction of large language models (LLMs). LLMs offer opportunities for a paradigm shift towards more decentralized, participatory online spaces that can be used to facilitate deliberative dialogues at scale, but also create risks of exacerbating societal schisms. Here, we explore four applications of LLMs to improve digital public squares: collective dialogue systems, bridging systems, community moderation, and proof-of-humanity systems. Building on the input from over 70 civil society experts and technologists, we argue that LLMs both afford promising opportunities to shift the paradigm for conversations at scale and pose distinct risks for digital public squares. We lay out an agenda for future research and investments in AI that will strengthen digital public squares and safeguard against potential misuses of AI.
A Mechanism-Based Approach to Mitigating Harms from Persuasive Generative AI
Apr 23, 2024



Recent generative AI systems have demonstrated more advanced persuasive capabilities and are increasingly permeating areas of life where they can influence decision-making. Generative AI presents a new risk profile of persuasion due the opportunity for reciprocal exchange and prolonged interactions. This has led to growing concerns about harms from AI persuasion and how they can be mitigated, highlighting the need for a systematic study of AI persuasion. The current definitions of AI persuasion are unclear and related harms are insufficiently studied. Existing harm mitigation approaches prioritise harms from the outcome of persuasion over harms from the process of persuasion. In this paper, we lay the groundwork for the systematic study of AI persuasion. We first put forward definitions of persuasive generative AI. We distinguish between rationally persuasive generative AI, which relies on providing relevant facts, sound reasoning, or other forms of trustworthy evidence, and manipulative generative AI, which relies on taking advantage of cognitive biases and heuristics or misrepresenting information. We also put forward a map of harms from AI persuasion, including definitions and examples of economic, physical, environmental, psychological, sociocultural, political, privacy, and autonomy harm. We then introduce a map of mechanisms that contribute to harmful persuasion. Lastly, we provide an overview of approaches that can be used to mitigate against process harms of persuasion, including prompt engineering for manipulation classification and red teaming. Future work will operationalise these mitigations and study the interaction between different types of mechanisms of persuasion.
Fine-tuning language models to find agreement among humans with diverse preferences
Nov 28, 2022
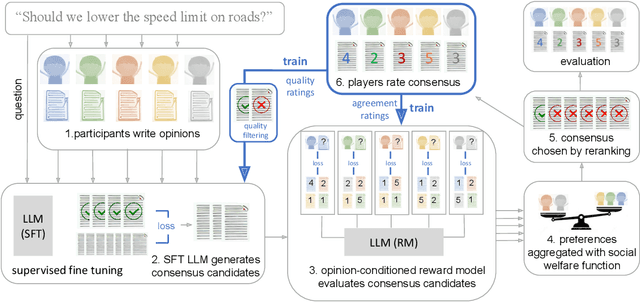
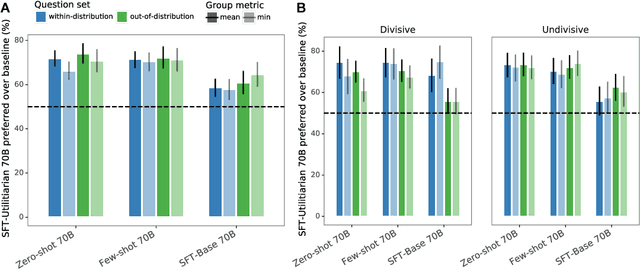
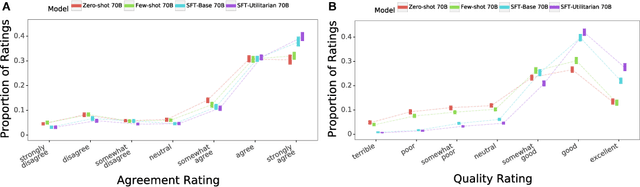
Recent work in large language modeling (LLMs) has used fine-tuning to align outputs with the preferences of a prototypical user. This work assumes that human preferences are static and homogeneous across individuals, so that aligning to a a single "generic" user will confer more general alignment. Here, we embrace the heterogeneity of human preferences to consider a different challenge: how might a machine help people with diverse views find agreement? We fine-tune a 70 billion parameter LLM to generate statements that maximize the expected approval for a group of people with potentially diverse opinions. Human participants provide written opinions on thousands of questions touching on moral and political issues (e.g., "should we raise taxes on the rich?"), and rate the LLM's generated candidate consensus statements for agreement and quality. A reward model is then trained to predict individual preferences, enabling it to quantify and rank consensus statements in terms of their appeal to the overall group, defined according to different aggregation (social welfare) functions. The model produces consensus statements that are preferred by human users over those from prompted LLMs (>70%) and significantly outperforms a tight fine-tuned baseline that lacks the final ranking step. Further, our best model's consensus statements are preferred over the best human-generated opinions (>65%). We find that when we silently constructed consensus statements from only a subset of group members, those who were excluded were more likely to dissent, revealing the sensitivity of the consensus to individual contributions. These results highlight the potential to use LLMs to help groups of humans align their values with one another.
Assessing Group-level Gender Bias in Professional Evaluations: The Case of Medical Student End-of-Shift Feedback
Jun 01, 2022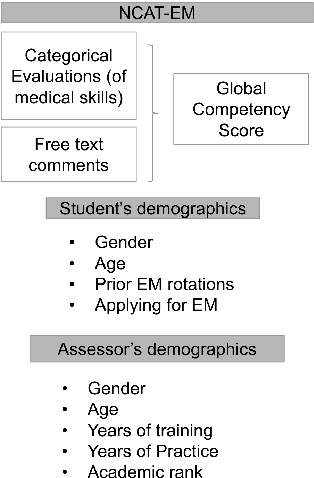
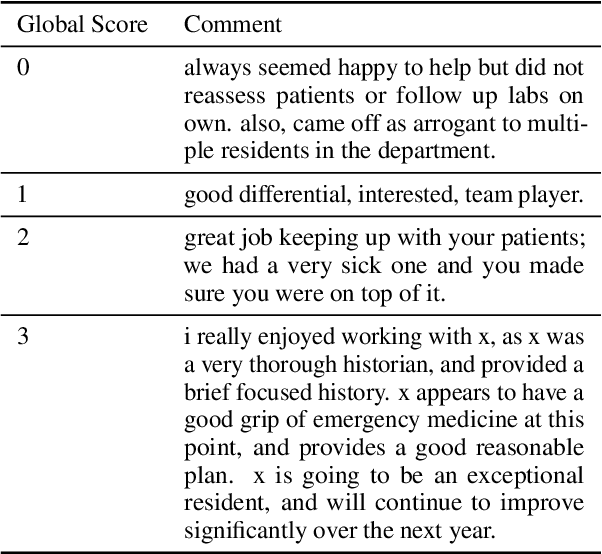

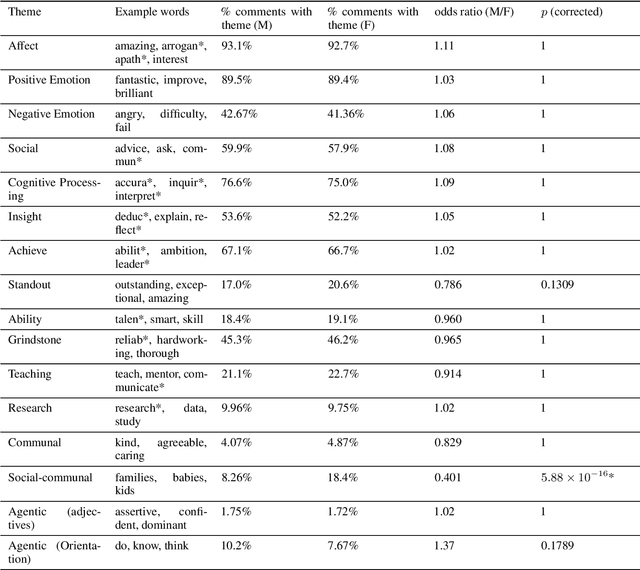
Although approximately 50% of medical school graduates today are women, female physicians tend to be underrepresented in senior positions, make less money than their male counterparts and receive fewer promotions. There is a growing body of literature demonstrating gender bias in various forms of evaluation in medicine, but this work was mainly conducted by looking for specific words using fixed dictionaries such as LIWC and focused on recommendation letters. We use a dataset of written and quantitative assessments of medical student performance on individual shifts of work, collected across multiple institutions, to investigate the extent to which gender bias exists in a day-to-day context for medical students. We investigate differences in the narrative comments given to male and female students by both male or female faculty assessors, using a fine-tuned BERT model. This allows us to examine whether groups are written about in systematically different ways, without relying on hand-crafted wordlists or topic models. We compare these results to results from the traditional LIWC method and find that, although we find no evidence of group-level gender bias in this dataset, terms related to family and children are used more in feedback given to women.
Can language models learn from explanations in context?
Apr 05, 2022
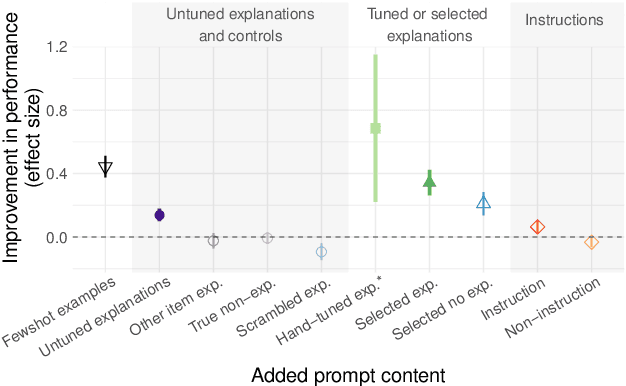
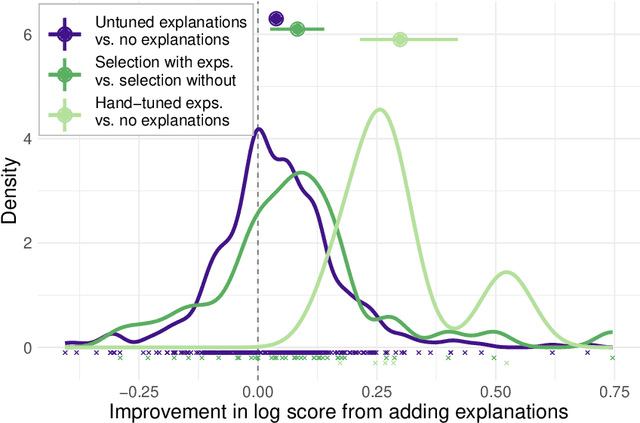
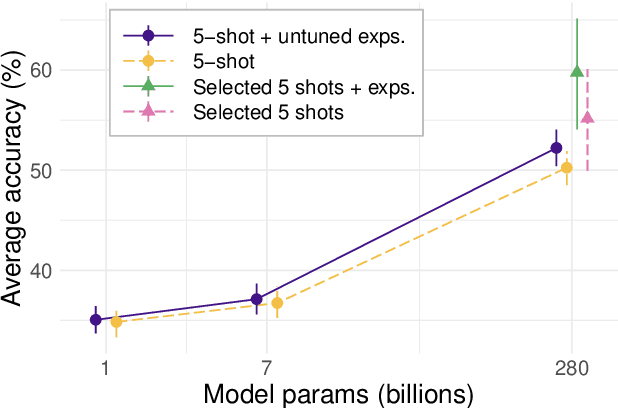
Large language models can perform new tasks by adapting to a few in-context examples. For humans, rapid learning from examples can benefit from explanations that connect examples to task principles. We therefore investigate whether explanations of few-shot examples can allow language models to adapt more effectively. We annotate a set of 40 challenging tasks from BIG-Bench with explanations of answers to a small subset of questions, as well as a variety of matched control explanations. We evaluate the effects of various zero-shot and few-shot prompts that include different types of explanations, instructions, and controls on the performance of a range of large language models. We analyze these results using statistical multilevel modeling techniques that account for the nested dependencies among conditions, tasks, prompts, and models. We find that explanations of examples can improve performance. Adding untuned explanations to a few-shot prompt offers a modest improvement in performance; about 1/3 the effect size of adding few-shot examples, but twice the effect size of task instructions. We then show that explanations tuned for performance on a small validation set offer substantially larger benefits; building a prompt by selecting examples and explanations together substantially improves performance over selecting examples alone. Hand-tuning explanations can substantially improve performance on challenging tasks. Furthermore, even untuned explanations outperform carefully matched controls, suggesting that the benefits are due to the link between an example and its explanation, rather than lower-level features of the language used. However, only large models can benefit from explanations. In summary, explanations can support the in-context learning abilities of large language models on
Growing knowledge culturally across generations to solve novel, complex tasks
Jul 28, 2021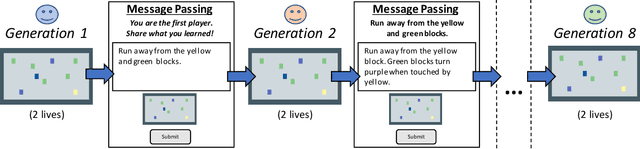
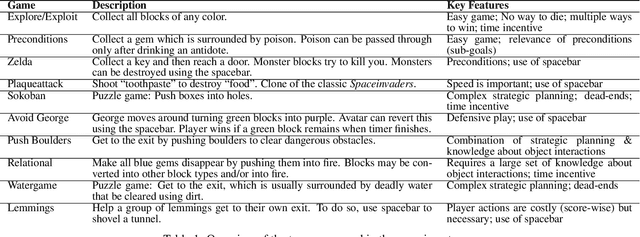

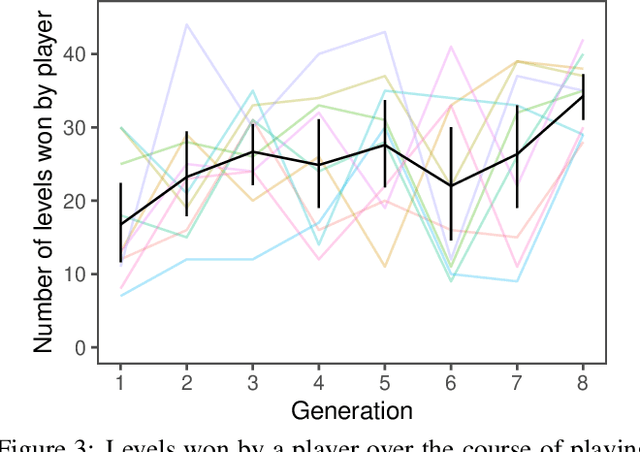
Knowledge built culturally across generations allows humans to learn far more than an individual could glean from their own experience in a lifetime. Cultural knowledge in turn rests on language: language is the richest record of what previous generations believed, valued, and practiced. The power and mechanisms of language as a means of cultural learning, however, are not well understood. We take a first step towards reverse-engineering cultural learning through language. We developed a suite of complex high-stakes tasks in the form of minimalist-style video games, which we deployed in an iterated learning paradigm. Game participants were limited to only two attempts (two lives) to beat each game and were allowed to write a message to a future participant who read the message before playing. Knowledge accumulated gradually across generations, allowing later generations to advance further in the games and perform more efficient actions. Multigenerational learning followed a strikingly similar trajectory to individuals learning alone with an unlimited number of lives. These results suggest that language provides a sufficient medium to express and accumulate the knowledge people acquire in these diverse tasks: the dynamics of the environment, valuable goals, dangerous risks, and strategies for success. The video game paradigm we pioneer here is thus a rich test bed for theories of cultural transmission and learning from language.
Improving Coherence and Consistency in Neural Sequence Models with Dual-System, Neuro-Symbolic Reasoning
Jul 06, 2021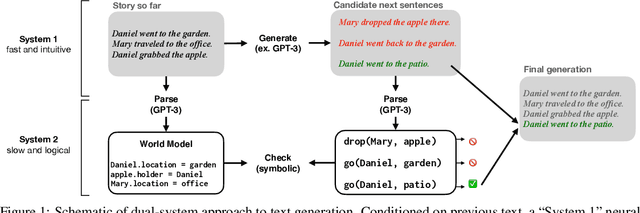


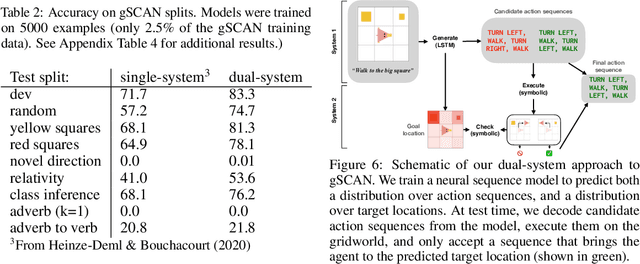
Human reasoning can often be understood as an interplay between two systems: the intuitive and associative ("System 1") and the deliberative and logical ("System 2"). Neural sequence models -- which have been increasingly successful at performing complex, structured tasks -- exhibit the advantages and failure modes of System 1: they are fast and learn patterns from data, but are often inconsistent and incoherent. In this work, we seek a lightweight, training-free means of improving existing System 1-like sequence models by adding System 2-inspired logical reasoning. We explore several variations on this theme in which candidate generations from a neural sequence model are examined for logical consistency by a symbolic reasoning module, which can either accept or reject the generations. Our approach uses neural inference to mediate between the neural System 1 and the logical System 2. Results in robust story generation and grounded instruction-following show that this approach can increase the coherence and accuracy of neurally-based generations.