 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Agents as Digital Representatives in Collective Decision-Making
Feb 13, 2025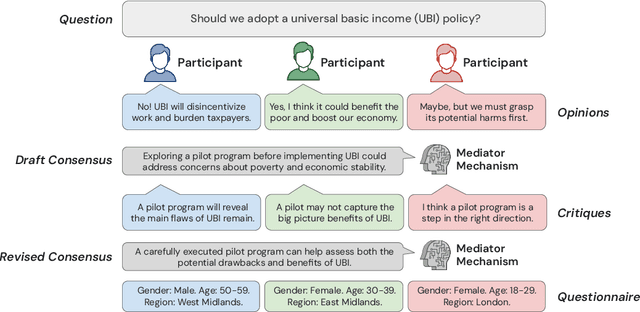

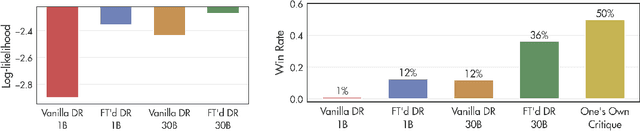
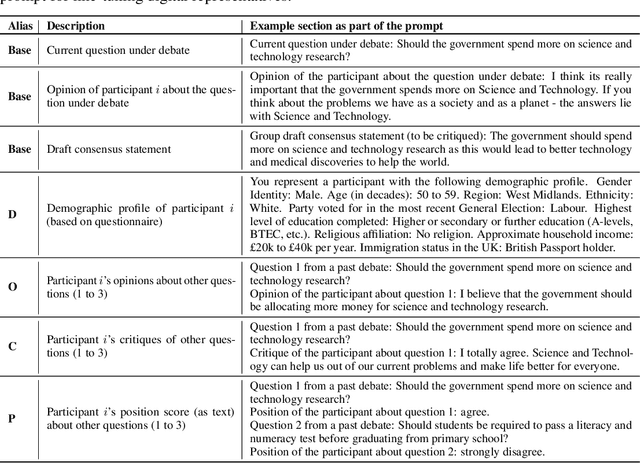
Consider the process of collective decision-making, in which a group of individuals interactively select a preferred outcome from among a universe of alternatives. In this context, "representation" is the activity of making an individual's preferences present in the process via participation by a proxy agent -- i.e. their "representative". To this end, learned models of human behavior have the potential to fill this role, with practical implications for multi-agent scenario studies and mechanism design. In this work, we investigate the possibility of training \textit{language agents} to behave in the capacity of representatives of human agents, appropriately expressing the preferences of those individuals whom they stand for. First, we formalize the setting of \textit{collective decision-making} -- as the episodic process of interaction between a group of agents and a decision mechanism. On this basis, we then formalize the problem of \textit{digital representation} -- as the simulation of an agent's behavior to yield equivalent outcomes from the mechanism. Finally, we conduct an empirical case study in the setting of \textit{consensus-finding} among diverse humans, and demonstrate the feasibility of fine-tuning large language models to act as digital representatives.
Using deep reinforcement learning to promote sustainable human behaviour on a common pool resource problem
Apr 23, 2024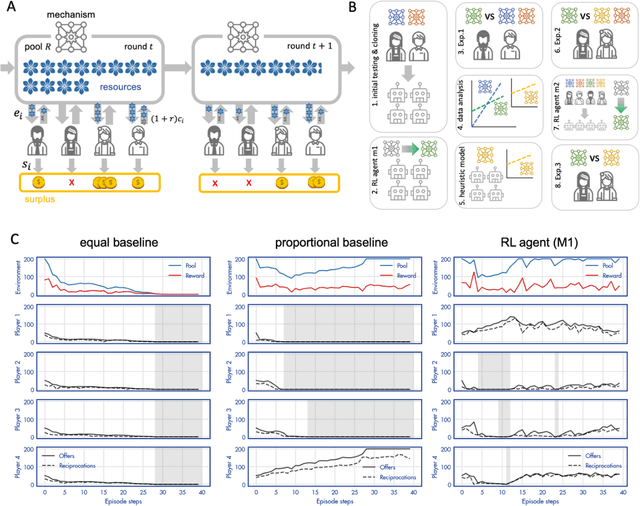
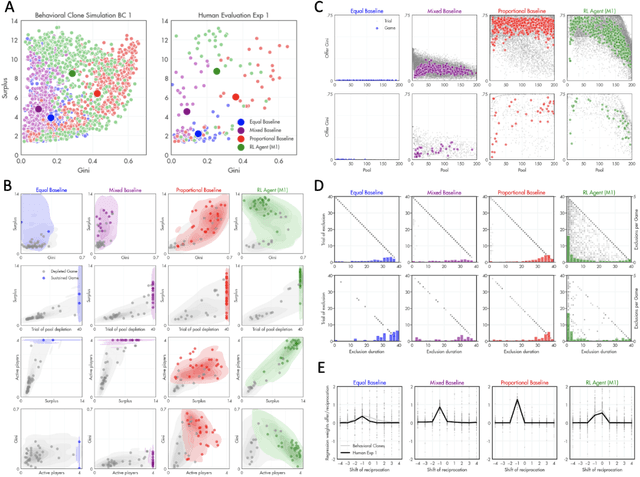
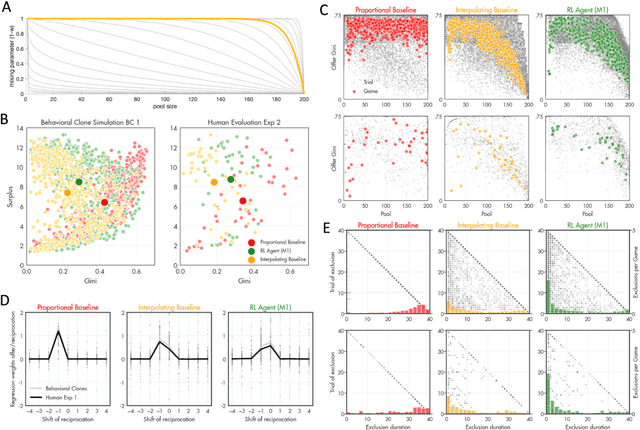
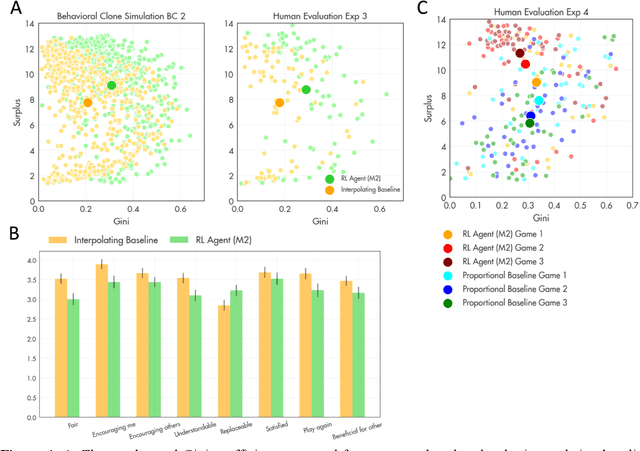
A canonical social dilemma arises when finite resources are allocated to a group of people, who can choose to either reciprocate with interest, or keep the proceeds for themselves. What resource allocation mechanisms will encourage levels of reciprocation that sustain the commons? Here, in an iterated multiplayer trust game, we use deep reinforcement learning (RL) to design an allocation mechanism that endogenously promotes sustainable contributions from human participants to a common pool resource. We first trained neural networks to behave like human players, creating a stimulated economy that allowed us to study how different mechanisms influenced the dynamics of receipt and reciprocation. We then used RL to train a social planner to maximise aggregate return to players. The social planner discovered a redistributive policy that led to a large surplus and an inclusive economy, in which players made roughly equal gains. The RL agent increased human surplus over baseline mechanisms based on unrestricted welfare or conditional cooperation, by conditioning its generosity on available resources and temporarily sanctioning defectors by allocating fewer resources to them. Examining the AI policy allowed us to develop an explainable mechanism that performed similarly and was more popular among players. Deep reinforcement learning can be used to discover mechanisms that promote sustainable human behaviour.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Fine-tuning language models to find agreement among humans with diverse preferences
Nov 28, 2022
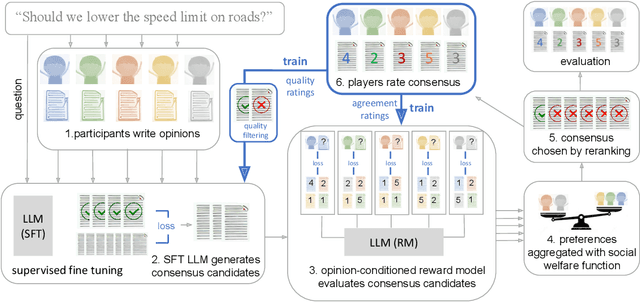
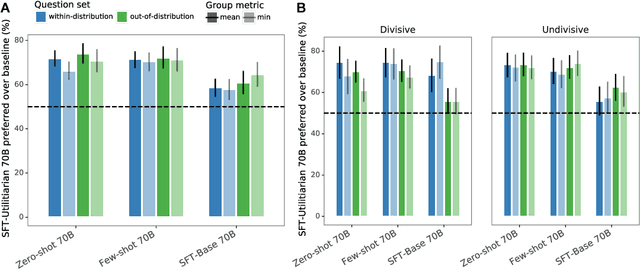
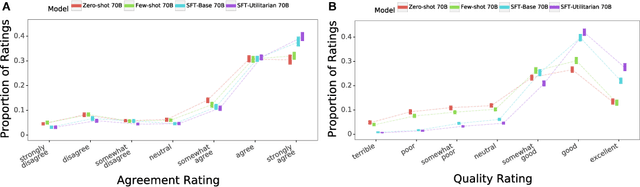
Recent work in large language modeling (LLMs) has used fine-tuning to align outputs with the preferences of a prototypical user. This work assumes that human preferences are static and homogeneous across individuals, so that aligning to a a single "generic" user will confer more general alignment. Here, we embrace the heterogeneity of human preferences to consider a different challenge: how might a machine help people with diverse views find agreement? We fine-tune a 70 billion parameter LLM to generate statements that maximize the expected approval for a group of people with potentially diverse opinions. Human participants provide written opinions on thousands of questions touching on moral and political issues (e.g., "should we raise taxes on the rich?"), and rate the LLM's generated candidate consensus statements for agreement and quality. A reward model is then trained to predict individual preferences, enabling it to quantify and rank consensus statements in terms of their appeal to the overall group, defined according to different aggregation (social welfare) functions. The model produces consensus statements that are preferred by human users over those from prompted LLMs (>70%) and significantly outperforms a tight fine-tuned baseline that lacks the final ranking step. Further, our best model's consensus statements are preferred over the best human-generated opinions (>65%). We find that when we silently constructed consensus statements from only a subset of group members, those who were excluded were more likely to dissent, revealing the sensitivity of the consensus to individual contributions. These results highlight the potential to use LLMs to help groups of humans align their values with one another.
The Good Shepherd: An Oracle Agent for Mechanism Design
Feb 21, 2022

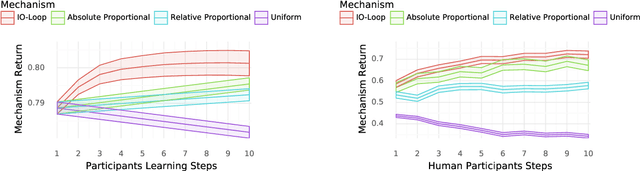
From social networks to traffic routing, artificial learning agents are playing a central role in modern institutions. We must therefore understand how to leverage these systems to foster outcomes and behaviors that align with our own values and aspirations. While multiagent learning has received considerable attention in recent years, artificial agents have been primarily evaluated when interacting with fixed, non-learning co-players. While this evaluation scheme has merit, it fails to capture the dynamics faced by institutions that must deal with adaptive and continually learning constituents. Here we address this limitation, and construct agents ("mechanisms") that perform well when evaluated over the learning trajectory of their adaptive co-players ("participants"). The algorithm we propose consists of two nested learning loops: an inner loop where participants learn to best respond to fixed mechanisms; and an outer loop where the mechanism agent updates its policy based on experience. We report the performance of our mechanism agents when paired with both artificial learning agents and humans as co-players. Our results show that our mechanisms are able to shepherd the participants strategies towards favorable outcomes, indicating a path for modern institutions to effectively and automatically influence the strategies and behaviors of their constituents.
HCMD-zero: Learning Value Aligned Mechanisms from Data
Feb 21, 2022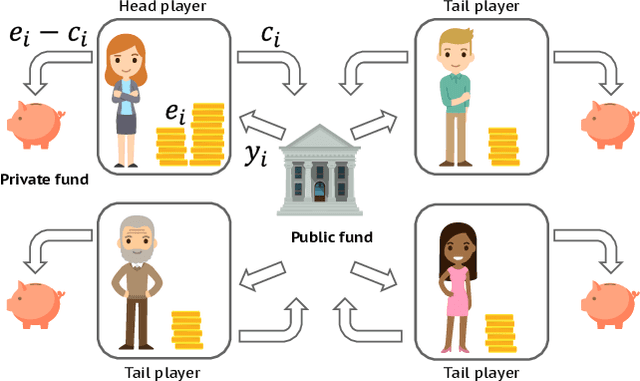

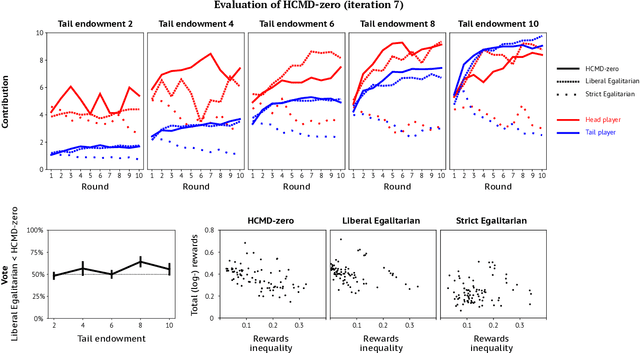
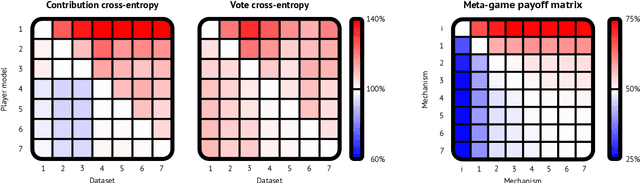
Artificial learning agents are mediating a larger and larger number of interactions among humans, firms, and organizations, and the intersection between mechanism design and machine learning has been heavily investigated in recent years. However, mechanism design methods make strong assumptions on how participants behave (e.g. rationality), or on the kind of knowledge designers have access to a priori (e.g. access to strong baseline mechanisms). Here we introduce HCMD-zero, a general purpose method to construct mechanism agents. HCMD-zero learns by mediating interactions among participants, while remaining engaged in an electoral contest with copies of itself, thereby accessing direct feedback from participants. Our results on the Public Investment Game, a stylized resource allocation game that highlights the tension between productivity, equality and the temptation to free-ride, show that HCMD-zero produces competitive mechanism agents that are consistently preferred by human participants over baseline alternatives, and does so automatically, without requiring human knowledge, and by using human data sparingly and effectively Our detailed analysis shows HCMD-zero elicits consistent improvements over the course of training, and that it results in a mechanism with an interpretable and intuitive policy.
Human-centered mechanism design with Democratic AI
Jan 27, 2022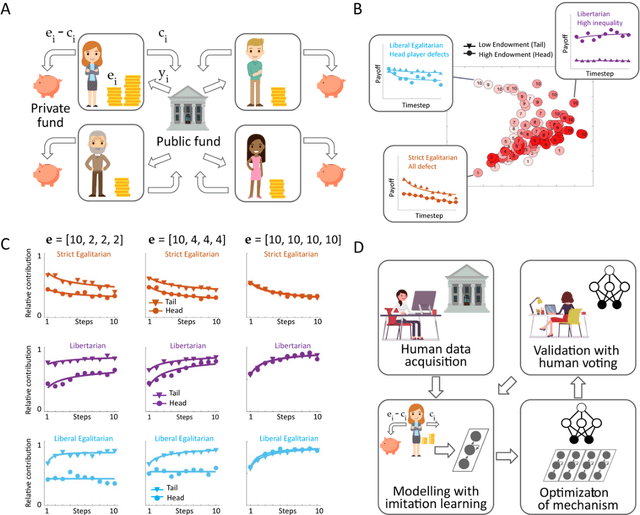
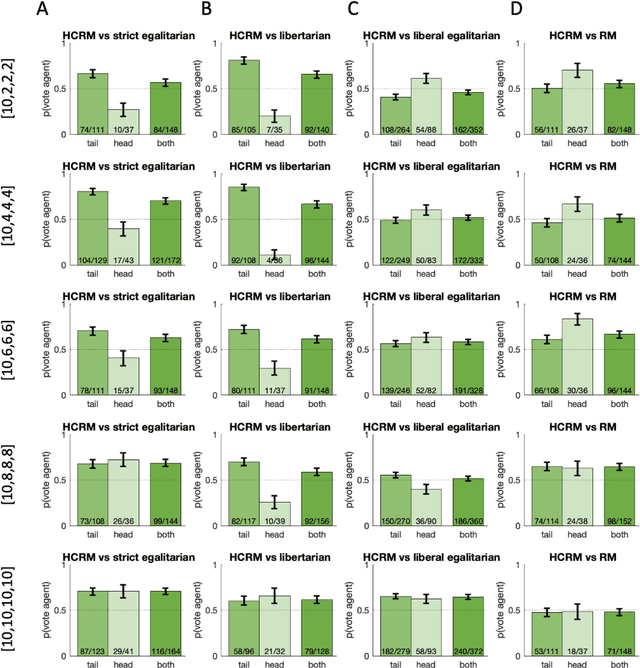
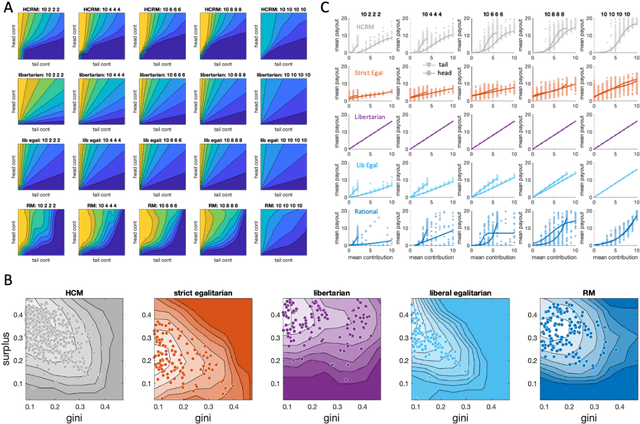
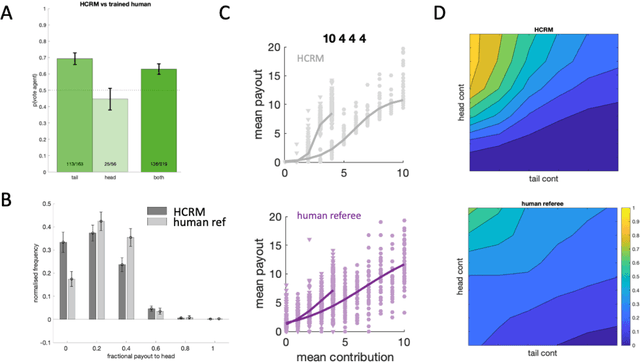
Building artificial intelligence (AI) that aligns with human values is an unsolved problem. Here, we developed a human-in-the-loop research pipeline called Democratic AI, in which reinforcement learning is used to design a social mechanism that humans prefer by majority. A large group of humans played an online investment game that involved deciding whether to keep a monetary endowment or to share it with others for collective benefit. Shared revenue was returned to players under two different redistribution mechanisms, one designed by the AI and the other by humans. The AI discovered a mechanism that redressed initial wealth imbalance, sanctioned free riders, and successfully won the majority vote. By optimizing for human preferences, Democratic AI may be a promising method for value-aligned policy innovation.
PonderNet: Learning to Ponder
Jul 12, 2021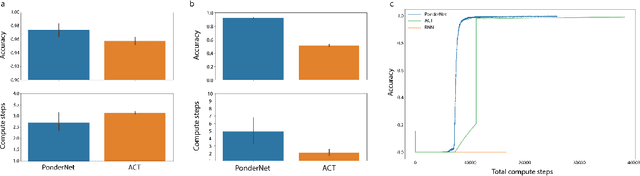

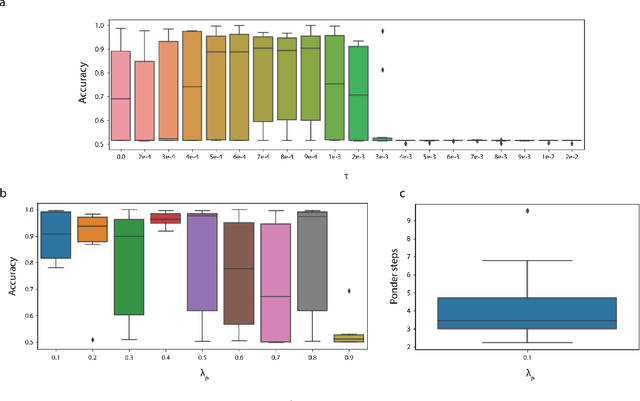

In standard neural networks the amount of computation used grows with the size of the inputs, but not with the complexity of the problem being learnt. To overcome this limitation we introduce PonderNet, a new algorithm that learns to adapt the amount of computation based on the complexity of the problem at hand. PonderNet learns end-to-end the number of computational steps to achieve an effective compromise between training prediction accuracy, computational cost and generalization. On a complex synthetic problem, PonderNet dramatically improves performance over previous adaptive computation methods and additionally succeeds at extrapolation tests where traditional neural networks fail. Also, our method matched the current state of the art results on a real world question and answering dataset, but using less compute. Finally, PonderNet reached state of the art results on a complex task designed to test the reasoning capabilities of neural networks.1