 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Learnable Wavelet Transformer for Long-Short Equity Trading and Risk-Adjusted Return Optimization
Jan 19, 2026Learning profitable intraday trading policies from financial time series is challenging due to heavy noise, non-stationarity, and strong cross-sectional dependence among related assets. We propose \emph{WaveLSFormer}, a learnable wavelet-based long-short Transformer that jointly performs multi-scale decomposition and return-oriented decision learning. Specifically, a learnable wavelet front-end generates low-/high-frequency components via an end-to-end trained filter bank, guided by spectral regularizers that encourage stable and well-separated frequency bands. To fuse multi-scale information, we introduce a low-guided high-frequency injection (LGHI) module that refines low-frequency representations with high-frequency cues while controlling training stability. The model outputs a portfolio of long/short positions that is rescaled to satisfy a fixed risk budget, and is optimized directly with a trading objective and risk-aware regularization. Extensive experiments on five years of hourly data across six industry groups, evaluated over ten random seeds, demonstrate that WaveLSFormer consistently outperforms MLP, LSTM and Transformer backbones, with and without fixed discrete wavelet front-ends. On average in all industries, WaveLSFormer achieves a cumulative overall strategy return of $0.607 \pm 0.045$ and a Sharpe ratio of $2.157 \pm 0.166$, substantially improving both profitability and risk-adjusted returns over the strongest baselines.
Using deep reinforcement learning to promote sustainable human behaviour on a common pool resource problem
Apr 23, 2024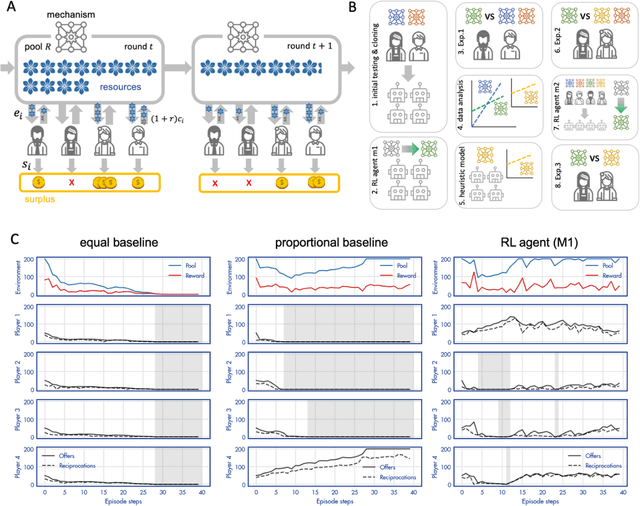
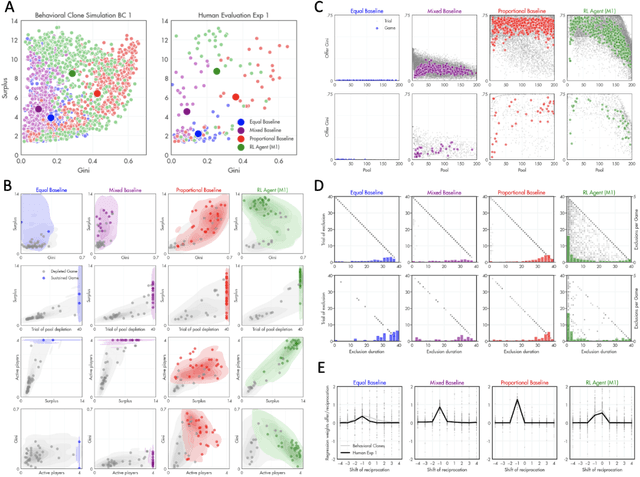
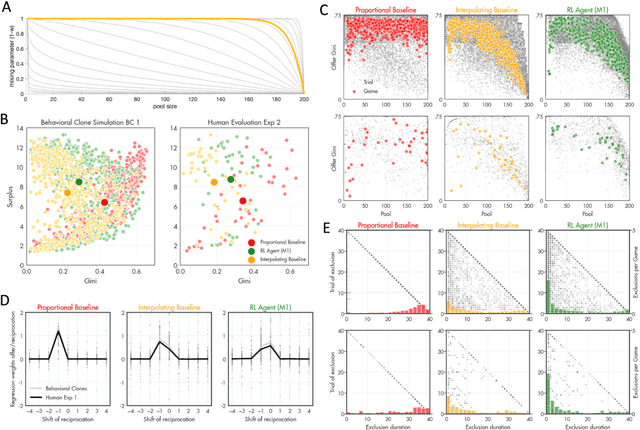
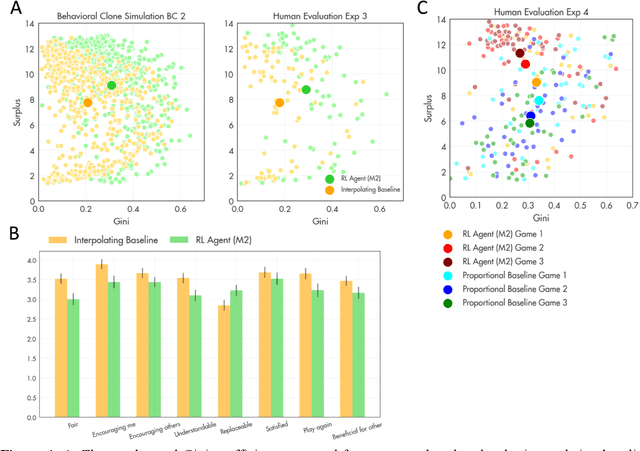
A canonical social dilemma arises when finite resources are allocated to a group of people, who can choose to either reciprocate with interest, or keep the proceeds for themselves. What resource allocation mechanisms will encourage levels of reciprocation that sustain the commons? Here, in an iterated multiplayer trust game, we use deep reinforcement learning (RL) to design an allocation mechanism that endogenously promotes sustainable contributions from human participants to a common pool resource. We first trained neural networks to behave like human players, creating a stimulated economy that allowed us to study how different mechanisms influenced the dynamics of receipt and reciprocation. We then used RL to train a social planner to maximise aggregate return to players. The social planner discovered a redistributive policy that led to a large surplus and an inclusive economy, in which players made roughly equal gains. The RL agent increased human surplus over baseline mechanisms based on unrestricted welfare or conditional cooperation, by conditioning its generosity on available resources and temporarily sanctioning defectors by allocating fewer resources to them. Examining the AI policy allowed us to develop an explainable mechanism that performed similarly and was more popular among players. Deep reinforcement learning can be used to discover mechanisms that promote sustainable human behaviour.