 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing deep reinforcement learning to promote sustainable human behaviour on a common pool resource problem
Apr 23, 2024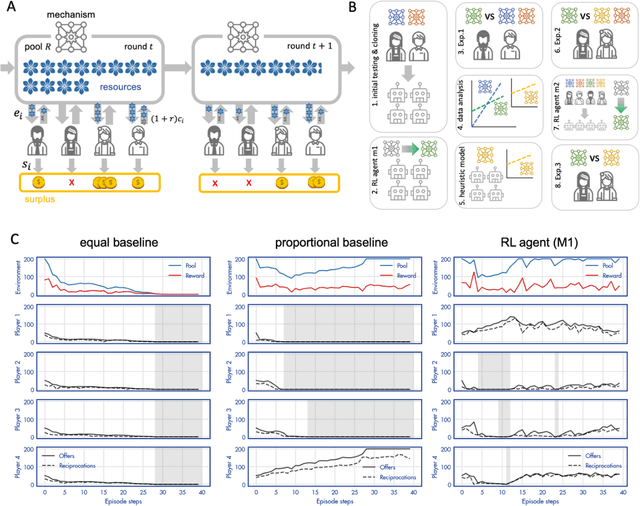
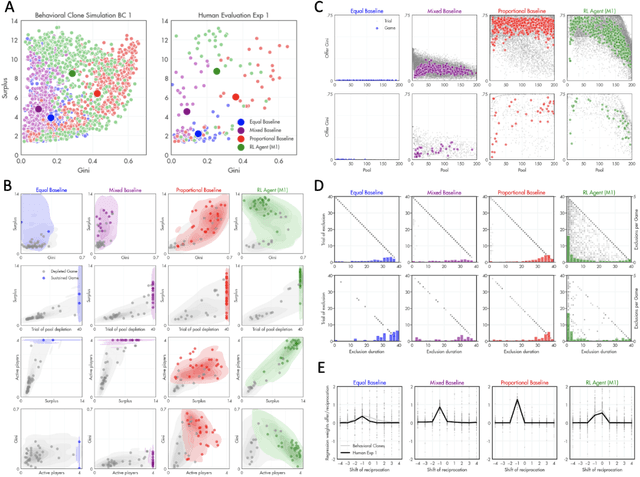
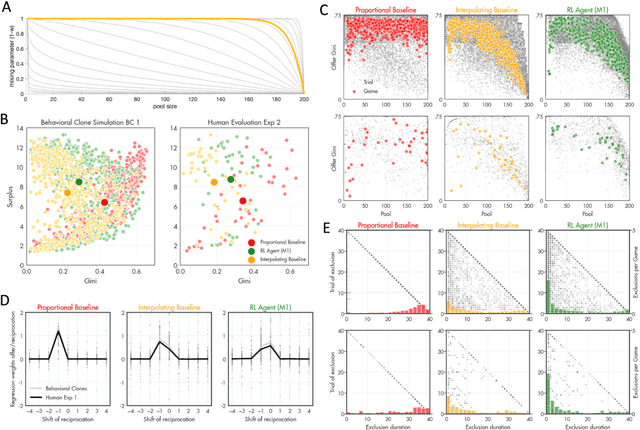
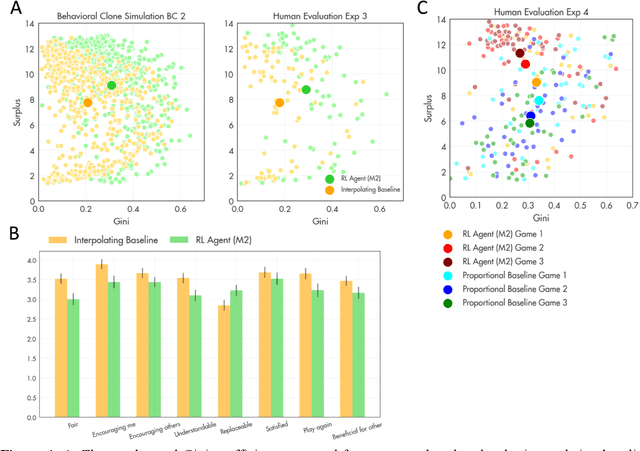
A canonical social dilemma arises when finite resources are allocated to a group of people, who can choose to either reciprocate with interest, or keep the proceeds for themselves. What resource allocation mechanisms will encourage levels of reciprocation that sustain the commons? Here, in an iterated multiplayer trust game, we use deep reinforcement learning (RL) to design an allocation mechanism that endogenously promotes sustainable contributions from human participants to a common pool resource. We first trained neural networks to behave like human players, creating a stimulated economy that allowed us to study how different mechanisms influenced the dynamics of receipt and reciprocation. We then used RL to train a social planner to maximise aggregate return to players. The social planner discovered a redistributive policy that led to a large surplus and an inclusive economy, in which players made roughly equal gains. The RL agent increased human surplus over baseline mechanisms based on unrestricted welfare or conditional cooperation, by conditioning its generosity on available resources and temporarily sanctioning defectors by allocating fewer resources to them. Examining the AI policy allowed us to develop an explainable mechanism that performed similarly and was more popular among players. Deep reinforcement learning can be used to discover mechanisms that promote sustainable human behaviour.
States as Strings as Strategies: Steering Language Models with Game-Theoretic Solvers
Feb 06, 2024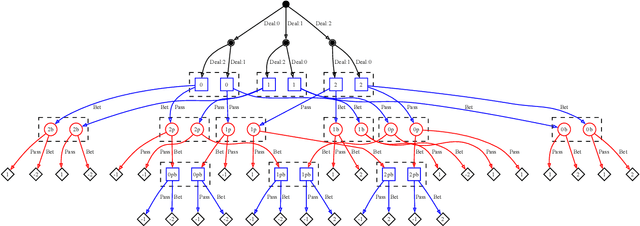

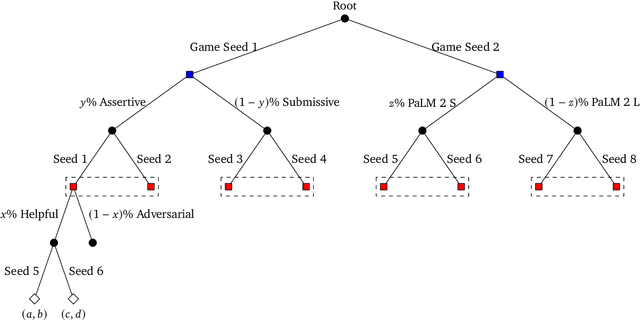
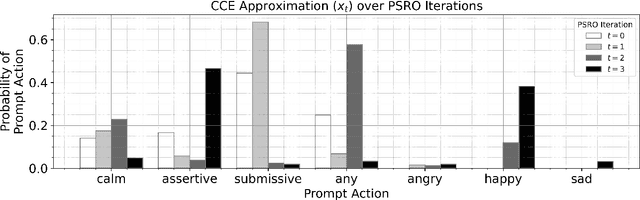
Game theory is the study of mathematical models of strategic interactions among rational agents. Language is a key medium of interaction for humans, though it has historically proven difficult to model dialogue and its strategic motivations mathematically. A suitable model of the players, strategies, and payoffs associated with linguistic interactions (i.e., a binding to the conventional symbolic logic of game theory) would enable existing game-theoretic algorithms to provide strategic solutions in the space of language. In other words, a binding could provide a route to computing stable, rational conversational strategies in dialogue. Large language models (LLMs) have arguably reached a point where their generative capabilities can enable realistic, human-like simulations of natural dialogue. By prompting them in various ways, we can steer their responses towards different output utterances. Leveraging the expressivity of natural language, LLMs can also help us quickly generate new dialogue scenarios, which are grounded in real world applications. In this work, we present one possible binding from dialogue to game theory as well as generalizations of existing equilibrium finding algorithms to this setting. In addition, by exploiting LLMs generation capabilities along with our proposed binding, we can synthesize a large repository of formally-defined games in which one can study and test game-theoretic solution concepts. We also demonstrate how one can combine LLM-driven game generation, game-theoretic solvers, and imitation learning to construct a process for improving the strategic capabilities of LLMs.
Towards Zero Shot Learning in Restless Multi-armed Bandits
Oct 23, 2023



Restless multi-arm bandits (RMABs), a class of resource allocation problems with broad application in areas such as healthcare, online advertising, and anti-poaching, have recently been studied from a multi-agent reinforcement learning perspective. Prior RMAB research suffers from several limitations, e.g., it fails to adequately address continuous states, and requires retraining from scratch when arms opt-in and opt-out over time, a common challenge in many real world applications. We address these limitations by developing a neural network-based pre-trained model (PreFeRMAB) that has general zero-shot ability on a wide range of previously unseen RMABs, and which can be fine-tuned on specific instances in a more sample-efficient way than retraining from scratch. Our model also accommodates general multi-action settings and discrete or continuous state spaces. To enable fast generalization, we learn a novel single policy network model that utilizes feature information and employs a training procedure in which arms opt-in and out over time. We derive a new update rule for a crucial $\lambda$-network with theoretical convergence guarantees and empirically demonstrate the advantages of our approach on several challenging, real-world inspired problems.
TacticAI: an AI assistant for football tactics
Oct 17, 2023Identifying key patterns of tactics implemented by rival teams, and developing effective responses, lies at the heart of modern football. However, doing so algorithmically remains an open research challenge. To address this unmet need, we propose TacticAI, an AI football tactics assistant developed and evaluated in close collaboration with domain experts from Liverpool FC. We focus on analysing corner kicks, as they offer coaches the most direct opportunities for interventions and improvements. TacticAI incorporates both a predictive and a generative component, allowing the coaches to effectively sample and explore alternative player setups for each corner kick routine and to select those with the highest predicted likelihood of success. We validate TacticAI on a number of relevant benchmark tasks: predicting receivers and shot attempts and recommending player position adjustments. The utility of TacticAI is validated by a qualitative study conducted with football domain experts at Liverpool FC. We show that TacticAI's model suggestions are not only indistinguishable from real tactics, but also favoured over existing tactics 90% of the time, and that TacticAI offers an effective corner kick retrieval system. TacticAI achieves these results despite the limited availability of gold-standard data, achieving data efficiency through geometric deep learning.
Heterogeneous Social Value Orientation Leads to Meaningful Diversity in Sequential Social Dilemmas
May 01, 2023



In social psychology, Social Value Orientation (SVO) describes an individual's propensity to allocate resources between themself and others. In reinforcement learning, SVO has been instantiated as an intrinsic motivation that remaps an agent's rewards based on particular target distributions of group reward. Prior studies show that groups of agents endowed with heterogeneous SVO learn diverse policies in settings that resemble the incentive structure of Prisoner's dilemma. Our work extends this body of results and demonstrates that (1) heterogeneous SVO leads to meaningfully diverse policies across a range of incentive structures in sequential social dilemmas, as measured by task-specific diversity metrics; and (2) learning a best response to such policy diversity leads to better zero-shot generalization in some situations. We show that these best-response agents learn policies that are conditioned on their co-players, which we posit is the reason for improved zero-shot generalization results.
Human-Timescale Adaptation in an Open-Ended Task Space
Jan 18, 2023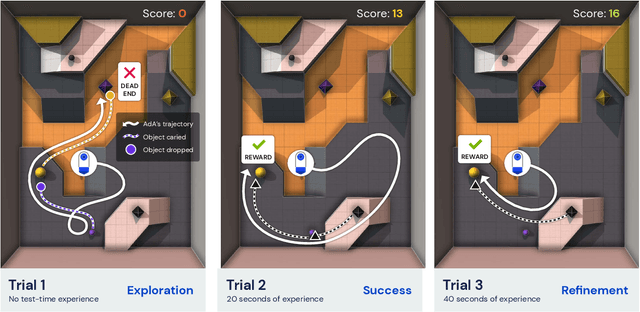
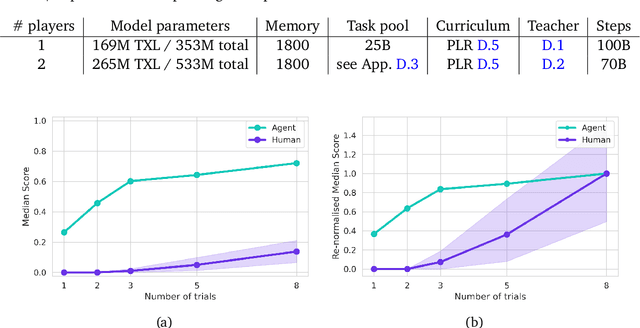
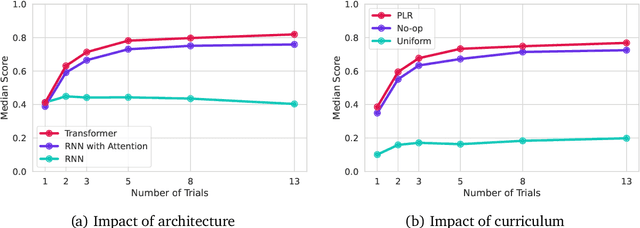
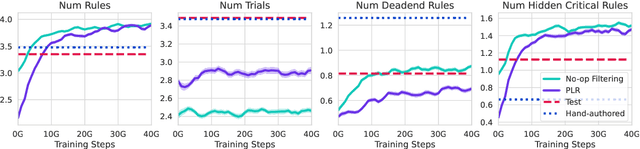
Foundation models have shown impressive adaptation and scalability in supervised and self-supervised learning problems, but so far these successes have not fully translated to reinforcement learning (RL). In this work, we demonstrate that training an RL agent at scale leads to a general in-context learning algorithm that can adapt to open-ended novel embodied 3D problems as quickly as humans. In a vast space of held-out environment dynamics, our adaptive agent (AdA) displays on-the-fly hypothesis-driven exploration, efficient exploitation of acquired knowledge, and can successfully be prompted with first-person demonstrations. Adaptation emerges from three ingredients: (1) meta-reinforcement learning across a vast, smooth and diverse task distribution, (2) a policy parameterised as a large-scale attention-based memory architecture, and (3) an effective automated curriculum that prioritises tasks at the frontier of an agent's capabilities. We demonstrate characteristic scaling laws with respect to network size, memory length, and richness of the training task distribution. We believe our results lay the foundation for increasingly general and adaptive RL agents that perform well across ever-larger open-ended domains.
An Analysis of Quantile Temporal-Difference Learning
Jan 11, 2023



We analyse quantile temporal-difference learning (QTD), a distributional reinforcement learning algorithm that has proven to be a key component in several successful large-scale applications of reinforcement learning. Despite these empirical successes, a theoretical understanding of QTD has proven elusive until now. Unlike classical TD learning, which can be analysed with standard stochastic approximation tools, QTD updates do not approximate contraction mappings, are highly non-linear, and may have multiple fixed points. The core result of this paper is a proof of convergence to the fixed points of a related family of dynamic programming procedures with probability 1, putting QTD on firm theoretical footing. The proof establishes connections between QTD and non-linear differential inclusions through stochastic approximation theory and non-smooth analysis.
Turbocharging Solution Concepts: Solving NEs, CEs and CCEs with Neural Equilibrium Solvers
Oct 17, 2022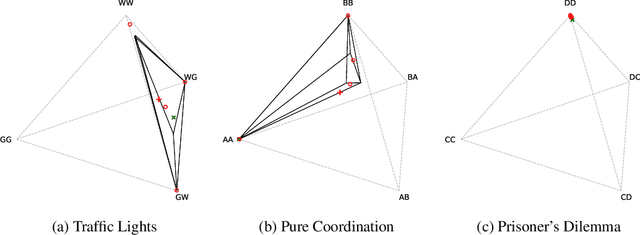
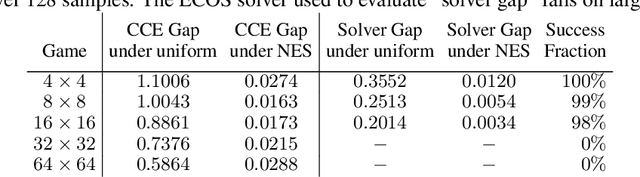

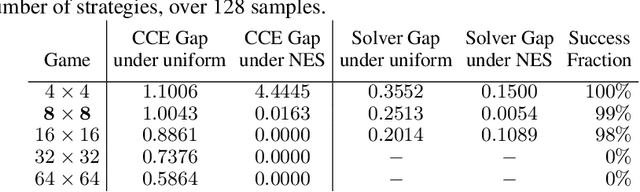
Solution concepts such as Nash Equilibria, Correlated Equilibria, and Coarse Correlated Equilibria are useful components for many multiagent machine learning algorithms. Unfortunately, solving a normal-form game could take prohibitive or non-deterministic time to converge, and could fail. We introduce the Neural Equilibrium Solver which utilizes a special equivariant neural network architecture to approximately solve the space of all games of fixed shape, buying speed and determinism. We define a flexible equilibrium selection framework, that is capable of uniquely selecting an equilibrium that minimizes relative entropy, or maximizes welfare. The network is trained without needing to generate any supervised training data. We show remarkable zero-shot generalization to larger games. We argue that such a network is a powerful component for many possible multiagent algorithms.
Game Theoretic Rating in N-player general-sum games with Equilibria
Oct 05, 2022



Rating strategies in a game is an important area of research in game theory and artificial intelligence, and can be applied to any real-world competitive or cooperative setting. Traditionally, only transitive dependencies between strategies have been used to rate strategies (e.g. Elo), however recent work has expanded ratings to utilize game theoretic solutions to better rate strategies in non-transitive games. This work generalizes these ideas and proposes novel algorithms suitable for N-player, general-sum rating of strategies in normal-form games according to the payoff rating system. This enables well-established solution concepts, such as equilibria, to be leveraged to efficiently rate strategies in games with complex strategic interactions, which arise in multiagent training and real-world interactions between many agents. We empirically validate our methods on real world normal-form data (Premier League) and multiagent reinforcement learning agent evaluation.
Developing, Evaluating and Scaling Learning Agents in Multi-Agent Environments
Sep 22, 2022The Game Theory & Multi-Agent team at DeepMind studies several aspects of multi-agent learning ranging from computing approximations to fundamental concepts in game theory to simulating social dilemmas in rich spatial environments and training 3-d humanoids in difficult team coordination tasks. A signature aim of our group is to use the resources and expertise made available to us at DeepMind in deep reinforcement learning to explore multi-agent systems in complex environments and use these benchmarks to advance our understanding. Here, we summarise the recent work of our team and present a taxonomy that we feel highlights many important open challenges in multi-agent research.