 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeINCLUDE: Evaluating Multilingual Language Understanding with Regional Knowledge
Nov 29, 2024



The performance differential of large language models (LLM) between languages hinders their effective deployment in many regions, inhibiting the potential economic and societal value of generative AI tools in many communities. However, the development of functional LLMs in many languages (\ie, multilingual LLMs) is bottlenecked by the lack of high-quality evaluation resources in languages other than English. Moreover, current practices in multilingual benchmark construction often translate English resources, ignoring the regional and cultural knowledge of the environments in which multilingual systems would be used. In this work, we construct an evaluation suite of 197,243 QA pairs from local exam sources to measure the capabilities of multilingual LLMs in a variety of regional contexts. Our novel resource, INCLUDE, is a comprehensive knowledge- and reasoning-centric benchmark across 44 written languages that evaluates multilingual LLMs for performance in the actual language environments where they would be deployed.
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Im-Promptu: In-Context Composition from Image Prompts
May 26, 2023



Large language models are few-shot learners that can solve diverse tasks from a handful of demonstrations. This implicit understanding of tasks suggests that the attention mechanisms over word tokens may play a role in analogical reasoning. In this work, we investigate whether analogical reasoning can enable in-context composition over composable elements of visual stimuli. First, we introduce a suite of three benchmarks to test the generalization properties of a visual in-context learner. We formalize the notion of an analogy-based in-context learner and use it to design a meta-learning framework called Im-Promptu. Whereas the requisite token granularity for language is well established, the appropriate compositional granularity for enabling in-context generalization in visual stimuli is usually unspecified. To this end, we use Im-Promptu to train multiple agents with different levels of compositionality, including vector representations, patch representations, and object slots. Our experiments reveal tradeoffs between extrapolation abilities and the degree of compositionality, with non-compositional representations extending learned composition rules to unseen domains but performing poorly on combinatorial tasks. Patch-based representations require patches to contain entire objects for robust extrapolation. At the same time, object-centric tokenizers coupled with a cross-attention module generate consistent and high-fidelity solutions, with these inductive biases being particularly crucial for compositional generalization. Lastly, we demonstrate a use case of Im-Promptu as an intuitive programming interface for image generation.
Neural Constraint Satisfaction: Hierarchical Abstraction for Combinatorial Generalization in Object Rearrangement
Mar 20, 2023



Object rearrangement is a challenge for embodied agents because solving these tasks requires generalizing across a combinatorially large set of configurations of entities and their locations. Worse, the representations of these entities are unknown and must be inferred from sensory percepts. We present a hierarchical abstraction approach to uncover these underlying entities and achieve combinatorial generalization from unstructured visual inputs. By constructing a factorized transition graph over clusters of entity representations inferred from pixels, we show how to learn a correspondence between intervening on states of entities in the agent's model and acting on objects in the environment. We use this correspondence to develop a method for control that generalizes to different numbers and configurations of objects, which outperforms current offline deep RL methods when evaluated on simulated rearrangement tasks.
Human-Timescale Adaptation in an Open-Ended Task Space
Jan 18, 2023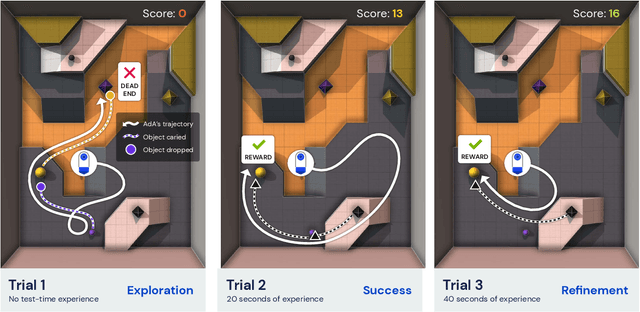
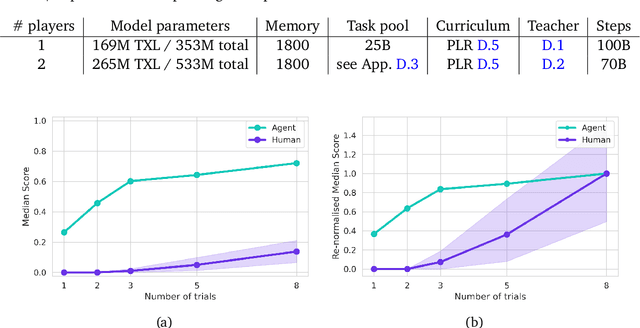
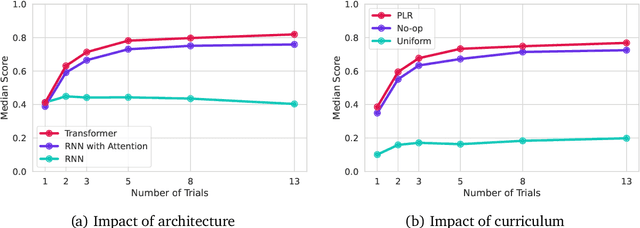
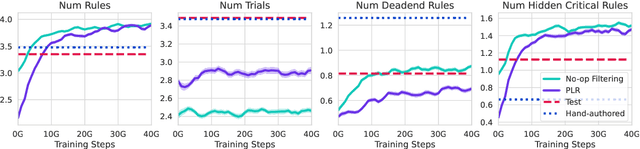
Foundation models have shown impressive adaptation and scalability in supervised and self-supervised learning problems, but so far these successes have not fully translated to reinforcement learning (RL). In this work, we demonstrate that training an RL agent at scale leads to a general in-context learning algorithm that can adapt to open-ended novel embodied 3D problems as quickly as humans. In a vast space of held-out environment dynamics, our adaptive agent (AdA) displays on-the-fly hypothesis-driven exploration, efficient exploitation of acquired knowledge, and can successfully be prompted with first-person demonstrations. Adaptation emerges from three ingredients: (1) meta-reinforcement learning across a vast, smooth and diverse task distribution, (2) a policy parameterised as a large-scale attention-based memory architecture, and (3) an effective automated curriculum that prioritises tasks at the frontier of an agent's capabilities. We demonstrate characteristic scaling laws with respect to network size, memory length, and richness of the training task distribution. We believe our results lay the foundation for increasingly general and adaptive RL agents that perform well across ever-larger open-ended domains.
DMODE: Differential Monocular Object Distance Estimation Module without Class Specific Information
Oct 23, 2022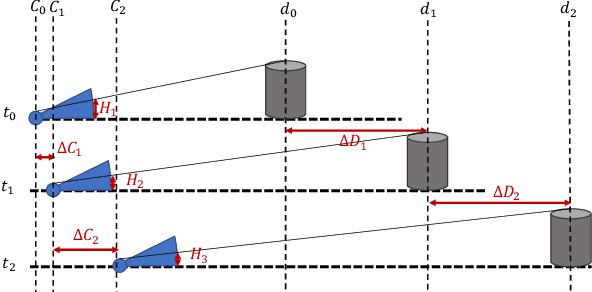
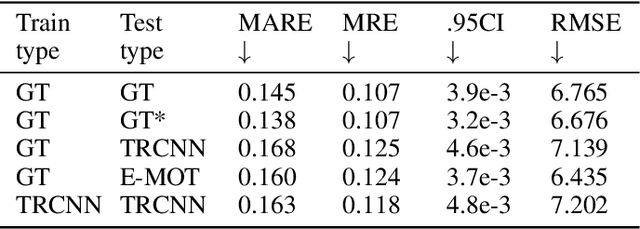
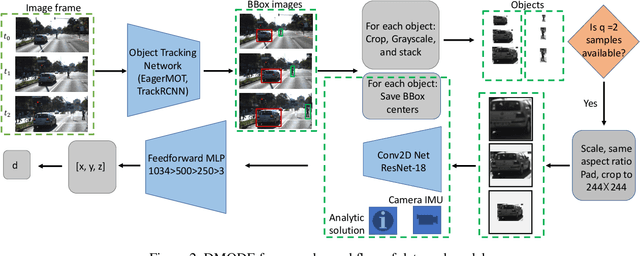
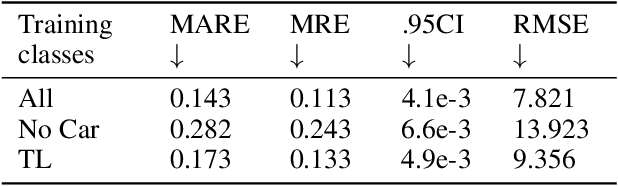
Using a single camera to estimate the distances of objects reduces costs compared to stereo-vision and LiDAR. Although monocular distance estimation has been studied in the literature, previous methods mostly rely on knowing an object's class in some way. This can result in deteriorated performance for dataset with multi-class objects and objects with an undefined class. In this paper, we aim to overcome the potential downsides of class-specific approaches, and provide an alternative technique called DMODE that does not require any information relating to its class. Using differential approaches, we combine the changes in an object's size over time together with the camera's motion to estimate the object's distance. Since DMODE is class agnostic method, it is easily adaptable to new environments. Therefore, it is able to maintain performance across different object detectors, and be easily adapted to new object classes. We tested our model across different scenarios of training and testing on the KITTI MOTS dataset's ground-truth bounding box annotations, and bounding box outputs of TrackRCNN and EagerMOT. The instantaneous change of bounding box sizes and camera position are then used to obtain an object's position in 3D without measuring its detection source or class properties. Our results show that we are able to outperform traditional alternatives methods e.g. IPM \cite{TuohyIPM}, SVR \cite{svr}, and \cite{zhu2019learning} in test environments with multi-class object distance detections.
Object Representations as Fixed Points: Training Iterative Refinement Algorithms with Implicit Differentiation
Jul 02, 2022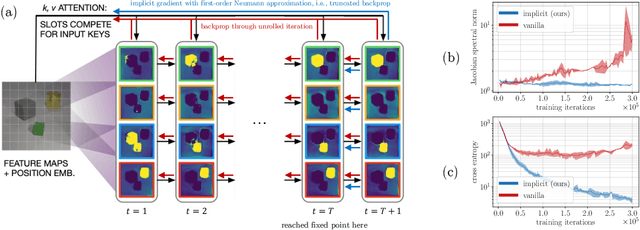

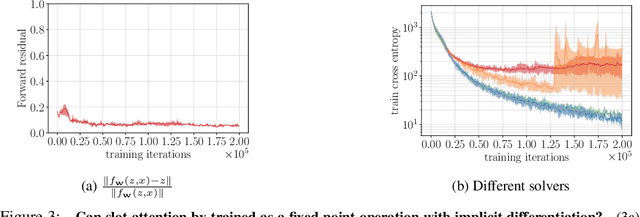
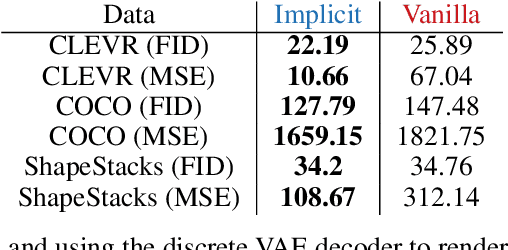
Iterative refinement -- start with a random guess, then iteratively improve the guess -- is a useful paradigm for representation learning because it offers a way to break symmetries among equally plausible explanations for the data. This property enables the application of such methods to infer representations of sets of entities, such as objects in physical scenes, structurally resembling clustering algorithms in latent space. However, most prior works differentiate through the unrolled refinement process, which can make optimization challenging. We observe that such methods can be made differentiable by means of the implicit function theorem, and develop an implicit differentiation approach that improves the stability and tractability of training by decoupling the forward and backward passes. This connection enables us to apply advances in optimizing implicit layers to not only improve the optimization of the slot attention module in SLATE, a state-of-the-art method for learning entity representations, but do so with constant space and time complexity in backpropagation and only one additional line of code.
Modularity in Reinforcement Learning via Algorithmic Independence in Credit Assignment
Jul 21, 2021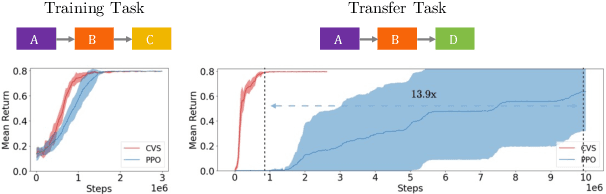
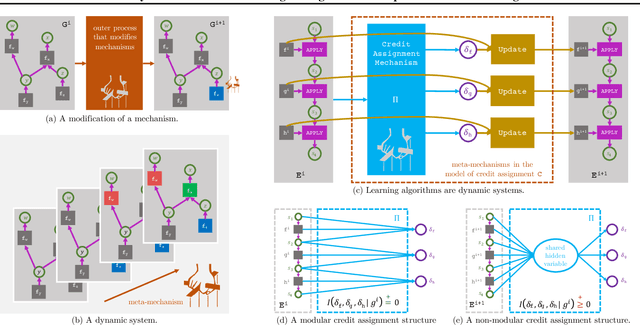
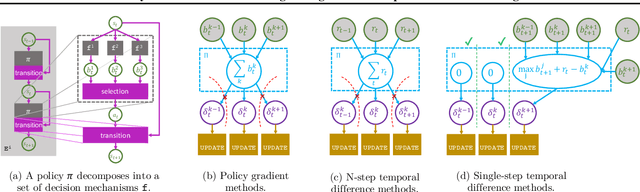
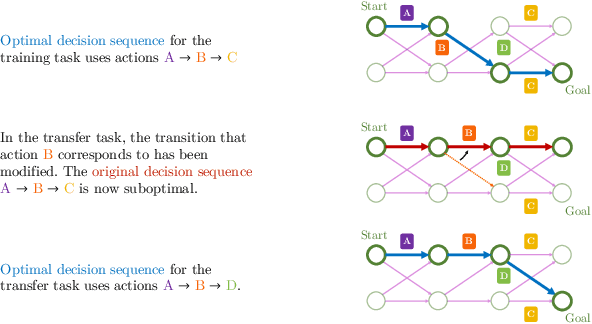
Many transfer problems require re-using previously optimal decisions for solving new tasks, which suggests the need for learning algorithms that can modify the mechanisms for choosing certain actions independently of those for choosing others. However, there is currently no formalism nor theory for how to achieve this kind of modular credit assignment. To answer this question, we define modular credit assignment as a constraint on minimizing the algorithmic mutual information among feedback signals for different decisions. We introduce what we call the modularity criterion for testing whether a learning algorithm satisfies this constraint by performing causal analysis on the algorithm itself. We generalize the recently proposed societal decision-making framework as a more granular formalism than the Markov decision process to prove that for decision sequences that do not contain cycles, certain single-step temporal difference action-value methods meet this criterion while all policy-gradient methods do not. Empirical evidence suggests that such action-value methods are more sample efficient than policy-gradient methods on transfer problems that require only sparse changes to a sequence of previously optimal decisions.
Explore and Control with Adversarial Surprise
Jul 12, 2021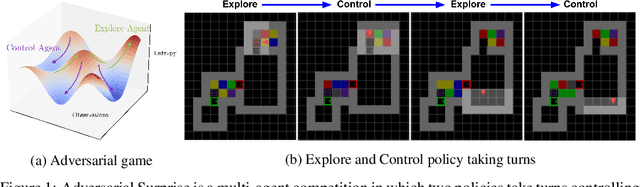
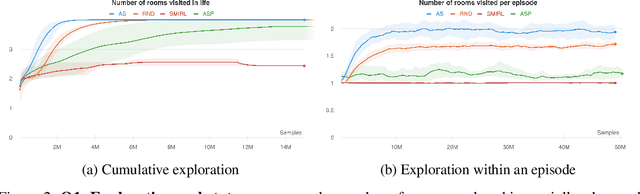
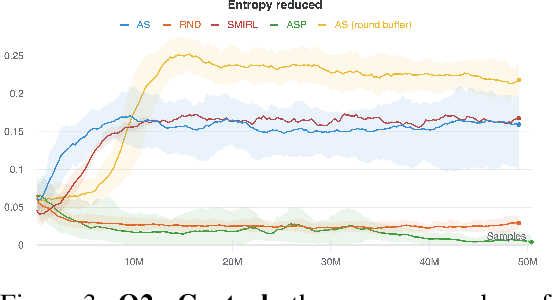
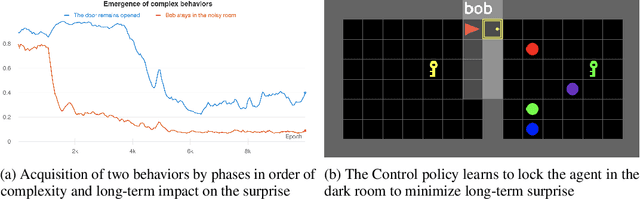
Reinforcement learning (RL) provides a framework for learning goal-directed policies given user-specified rewards. However, since designing rewards often requires substantial engineering effort, we are interested in the problem of learning without rewards, where agents must discover useful behaviors in the absence of task-specific incentives. Intrinsic motivation is a family of unsupervised RL techniques which develop general objectives for an RL agent to optimize that lead to better exploration or the discovery of skills. In this paper, we propose a new unsupervised RL technique based on an adversarial game which pits two policies against each other to compete over the amount of surprise an RL agent experiences. The policies each take turns controlling the agent. The Explore policy maximizes entropy, putting the agent into surprising or unfamiliar situations. Then, the Control policy takes over and seeks to recover from those situations by minimizing entropy. The game harnesses the power of multi-agent competition to drive the agent to seek out increasingly surprising parts of the environment while learning to gain mastery over them. We show empirically that our method leads to the emergence of complex skills by exhibiting clear phase transitions. Furthermore, we show both theoretically (via a latent state space coverage argument) and empirically that our method has the potential to be applied to the exploration of stochastic, partially-observed environments. We show that Adversarial Surprise learns more complex behaviors, and explores more effectively than competitive baselines, outperforming intrinsic motivation methods based on active inference, novelty-seeking (Random Network Distillation (RND)), and multi-agent unsupervised RL (Asymmetric Self-Play (ASP)) in MiniGrid, Atari and VizDoom environments.
Decentralized Reinforcement Learning: Global Decision-Making via Local Economic Transactions
Jul 05, 2020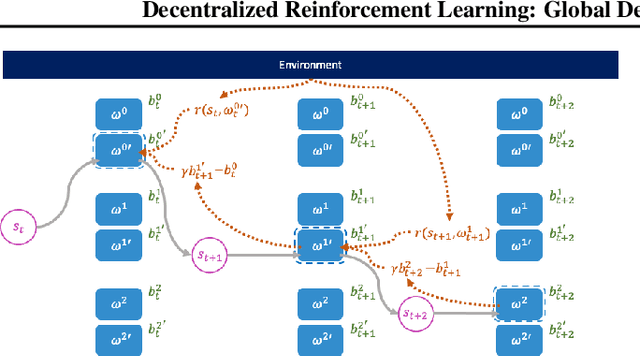
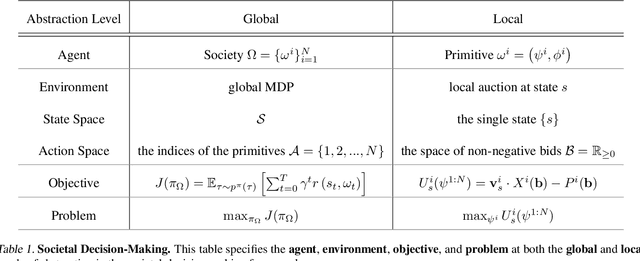
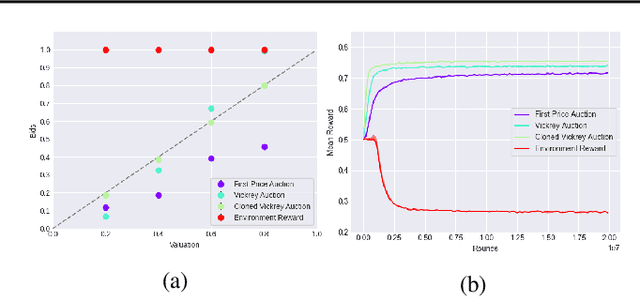
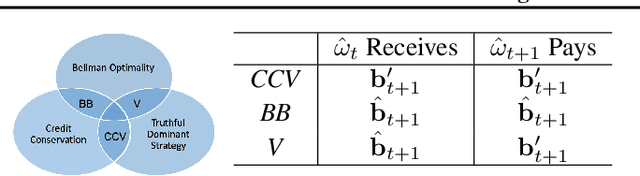
This paper seeks to establish a framework for directing a society of simple, specialized, self-interested agents to solve what traditionally are posed as monolithic single-agent sequential decision problems. What makes it challenging to use a decentralized approach to collectively optimize a central objective is the difficulty in characterizing the equilibrium strategy profile of non-cooperative games. To overcome this challenge, we design a mechanism for defining the learning environment of each agent for which we know that the optimal solution for the global objective coincides with a Nash equilibrium strategy profile of the agents optimizing their own local objectives. The society functions as an economy of agents that learn the credit assignment process itself by buying and selling to each other the right to operate on the environment state. We derive a class of decentralized reinforcement learning algorithms that are broadly applicable not only to standard reinforcement learning but also for selecting options in semi-MDPs and dynamically composing computation graphs. Lastly, we demonstrate the potential advantages of a society's inherent modular structure for more efficient transfer learning.