 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRL Zero: Zero-Shot Language to Behaviors without any Supervision
Dec 07, 2024Rewards remain an uninterpretable way to specify tasks for Reinforcement Learning, as humans are often unable to predict the optimal behavior of any given reward function, leading to poor reward design and reward hacking. Language presents an appealing way to communicate intent to agents and bypass reward design, but prior efforts to do so have been limited by costly and unscalable labeling efforts. In this work, we propose a method for a completely unsupervised alternative to grounding language instructions in a zero-shot manner to obtain policies. We present a solution that takes the form of imagine, project, and imitate: The agent imagines the observation sequence corresponding to the language description of a task, projects the imagined sequence to our target domain, and grounds it to a policy. Video-language models allow us to imagine task descriptions that leverage knowledge of tasks learned from internet-scale video-text mappings. The challenge remains to ground these generations to a policy. In this work, we show that we can achieve a zero-shot language-to-behavior policy by first grounding the imagined sequences in real observations of an unsupervised RL agent and using a closed-form solution to imitation learning that allows the RL agent to mimic the grounded observations. Our method, RLZero, is the first to our knowledge to show zero-shot language to behavior generation abilities without any supervision on a variety of tasks on simulated domains. We further show that RLZero can also generate policies zero-shot from cross-embodied videos such as those scraped from YouTube.
AMAGO-2: Breaking the Multi-Task Barrier in Meta-Reinforcement Learning with Transformers
Nov 17, 2024



Language models trained on diverse datasets unlock generalization by in-context learning. Reinforcement Learning (RL) policies can achieve a similar effect by meta-learning within the memory of a sequence model. However, meta-RL research primarily focuses on adapting to minor variations of a single task. It is difficult to scale towards more general behavior without confronting challenges in multi-task optimization, and few solutions are compatible with meta-RL's goal of learning from large training sets of unlabeled tasks. To address this challenge, we revisit the idea that multi-task RL is bottlenecked by imbalanced training losses created by uneven return scales across different tasks. We build upon recent advancements in Transformer-based (in-context) meta-RL and evaluate a simple yet scalable solution where both an agent's actor and critic objectives are converted to classification terms that decouple optimization from the current scale of returns. Large-scale comparisons in Meta-World ML45, Multi-Game Procgen, Multi-Task POPGym, Multi-Game Atari, and BabyAI find that this design unlocks significant progress in online multi-task adaptation and memory problems without explicit task labels.
DreamGarden: A Designer Assistant for Growing Games from a Single Prompt
Oct 02, 2024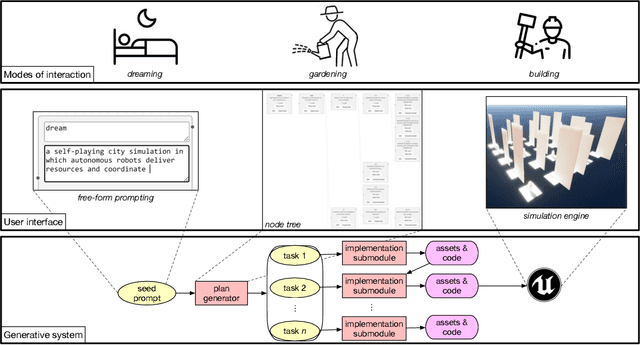

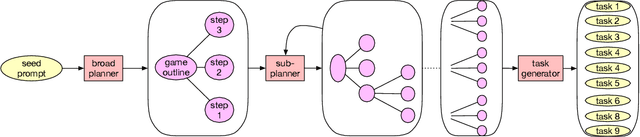
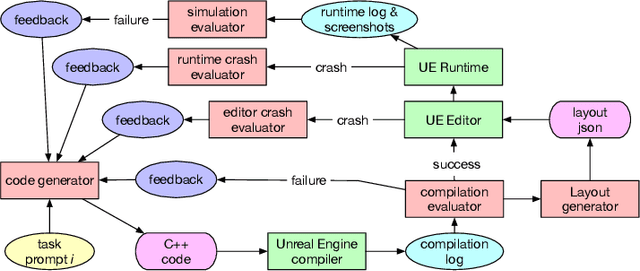
Coding assistants are increasingly leveraged in game design, both generating code and making high-level plans. To what degree can these tools align with developer workflows, and what new modes of human-computer interaction can emerge from their use? We present DreamGarden, an AI system capable of assisting with the development of diverse game environments in Unreal Engine. At the core of our method is an LLM-driven planner, capable of breaking down a single, high-level prompt -- a dream, memory, or imagined scenario provided by a human user -- into a hierarchical action plan, which is then distributed across specialized submodules facilitating concrete implementation. This system is presented to the user as a garden of plans and actions, both growing independently and responding to user intervention via seed prompts, pruning, and feedback. Through a user study, we explore design implications of this system, charting courses for future work in semi-autonomous assistants and open-ended simulation design.
Let's Go Shopping -- Web-Scale Image-Text Dataset for Visual Concept Understanding
Jan 09, 2024Vision and vision-language applications of neural networks, such as image classification and captioning, rely on large-scale annotated datasets that require non-trivial data-collecting processes. This time-consuming endeavor hinders the emergence of large-scale datasets, limiting researchers and practitioners to a small number of choices. Therefore, we seek more efficient ways to collect and annotate images. Previous initiatives have gathered captions from HTML alt-texts and crawled social media postings, but these data sources suffer from noise, sparsity, or subjectivity. For this reason, we turn to commercial shopping websites whose data meet three criteria: cleanliness, informativeness, and fluency. We introduce the Let's Go Shopping (LGS) dataset, a large-scale public dataset with 15 million image-caption pairs from publicly available e-commerce websites. When compared with existing general-domain datasets, the LGS images focus on the foreground object and have less complex backgrounds. Our experiments on LGS show that the classifiers trained on existing benchmark datasets do not readily generalize to e-commerce data, while specific self-supervised visual feature extractors can better generalize. Furthermore, LGS's high-quality e-commerce-focused images and bimodal nature make it advantageous for vision-language bi-modal tasks: LGS enables image-captioning models to generate richer captions and helps text-to-image generation models achieve e-commerce style transfer.
Explore and Control with Adversarial Surprise
Jul 12, 2021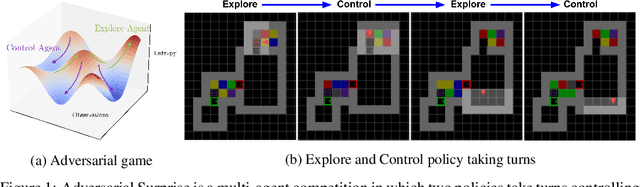
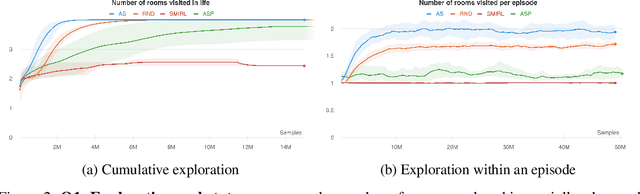
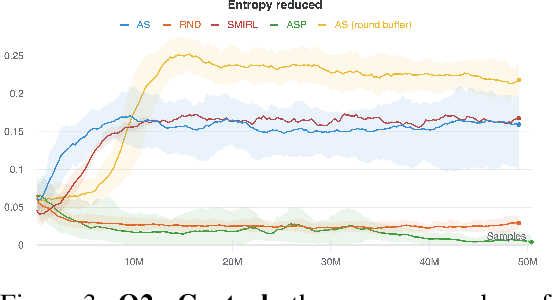
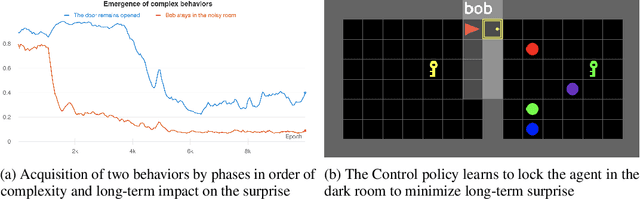
Reinforcement learning (RL) provides a framework for learning goal-directed policies given user-specified rewards. However, since designing rewards often requires substantial engineering effort, we are interested in the problem of learning without rewards, where agents must discover useful behaviors in the absence of task-specific incentives. Intrinsic motivation is a family of unsupervised RL techniques which develop general objectives for an RL agent to optimize that lead to better exploration or the discovery of skills. In this paper, we propose a new unsupervised RL technique based on an adversarial game which pits two policies against each other to compete over the amount of surprise an RL agent experiences. The policies each take turns controlling the agent. The Explore policy maximizes entropy, putting the agent into surprising or unfamiliar situations. Then, the Control policy takes over and seeks to recover from those situations by minimizing entropy. The game harnesses the power of multi-agent competition to drive the agent to seek out increasingly surprising parts of the environment while learning to gain mastery over them. We show empirically that our method leads to the emergence of complex skills by exhibiting clear phase transitions. Furthermore, we show both theoretically (via a latent state space coverage argument) and empirically that our method has the potential to be applied to the exploration of stochastic, partially-observed environments. We show that Adversarial Surprise learns more complex behaviors, and explores more effectively than competitive baselines, outperforming intrinsic motivation methods based on active inference, novelty-seeking (Random Network Distillation (RND)), and multi-agent unsupervised RL (Asymmetric Self-Play (ASP)) in MiniGrid, Atari and VizDoom environments.
Dynamically Throttleable Neural Networks (TNN)
Nov 01, 2020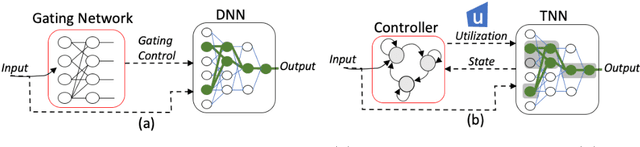


Conditional computation for Deep Neural Networks (DNNs) reduce overall computational load and improve model accuracy by running a subset of the network. In this work, we present a runtime throttleable neural network (TNN) that can adaptively self-regulate its own performance target and computing resources. We designed TNN with several properties that enable more flexibility for dynamic execution based on runtime context. TNNs are defined as throttleable modules gated with a separately trained controller that generates a single utilization control parameter. We validate our proposal on a number of experiments, including Convolution Neural Networks (CNNs such as VGG, ResNet, ResNeXt, DenseNet) using CiFAR-10 and ImageNet dataset, for object classification and recognition tasks. We also demonstrate the effectiveness of dynamic TNN execution on a 3D Convolustion Network (C3D) for a hand gesture task. Results show that TNN can maintain peak accuracy performance compared to vanilla solutions, while providing a graceful reduction in computational requirement, down to 74% reduction in latency and 52% energy savings.
The Many Faces of Robustness: A Critical Analysis of Out-of-Distribution Generalization
Jun 29, 2020
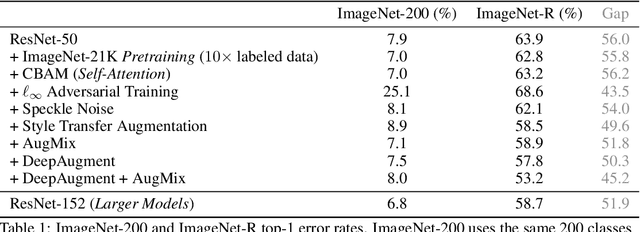

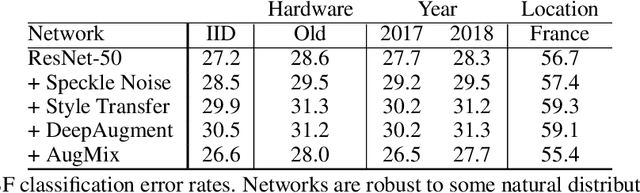
We introduce three new robustness benchmarks consisting of naturally occurring distribution changes in image style, geographic location, camera operation, and more. Using our benchmarks, we take stock of previously proposed hypotheses for out-of-distribution robustness and put them to the test. We find that using larger models and synthetic data augmentation can improve robustness on real-world distribution shifts, contrary to claims in prior work. Motivated by this, we introduce a new data augmentation method which advances the state-of-the-art and outperforms models pretrained with 1000x more labeled data. We find that some methods consistently help with distribution shifts in texture and local image statistics, but these methods do not help with some other distribution shifts like geographic changes. We conclude that future research must study multiple distribution shifts simultaneously.
Inter-Level Cooperation in Hierarchical Reinforcement Learning
Dec 05, 2019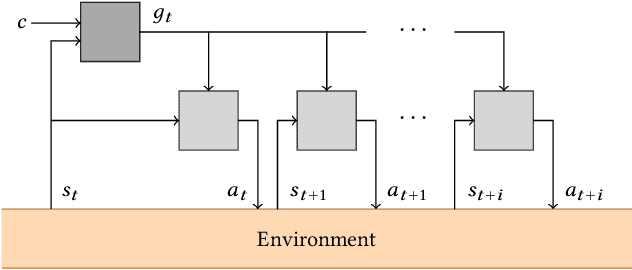


This article presents a novel algorithm for promoting cooperation between internal actors in a goal-conditioned hierarchical reinforcement learning (HRL) policy. Current techniques for HRL policy optimization treat the higher and lower level policies as separate entities which are trained to maximize different objective functions, rendering the HRL problem formulation more similar to a general sum game than a single-agent task. Within this setting, we hypothesize that improved cooperation between the internal agents of a hierarchy can simplify the credit assignment problem from the perspective of the high-level policies, thereby leading to significant improvements to training in situations where intricate sets of action primitives must be performed to yield improvements in performance. In order to promote cooperation within this setting, we propose the inclusion of a connected gradient term to the gradient computations of the higher level policies. Our method is demonstrated to achieve superior results to existing techniques in a set of difficult long time horizon tasks.
Generalized Ternary Connect: End-to-End Learning and Compression of Multiplication-Free Deep Neural Networks
Nov 12, 2018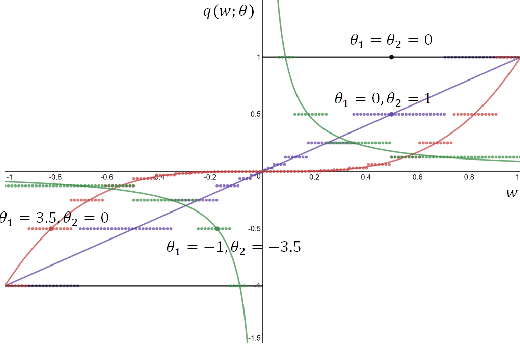
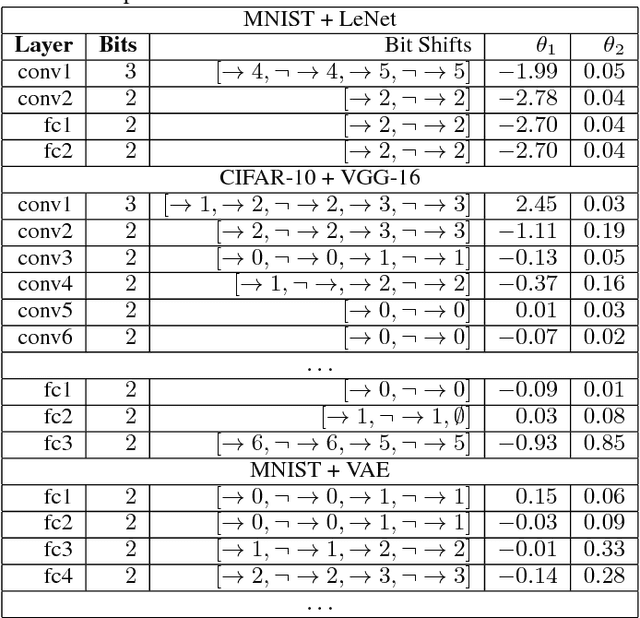
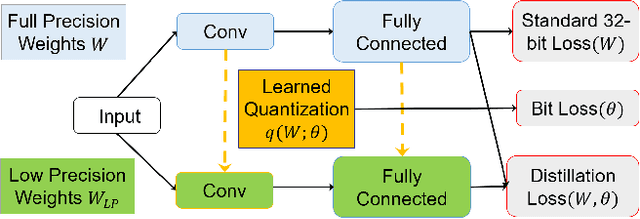
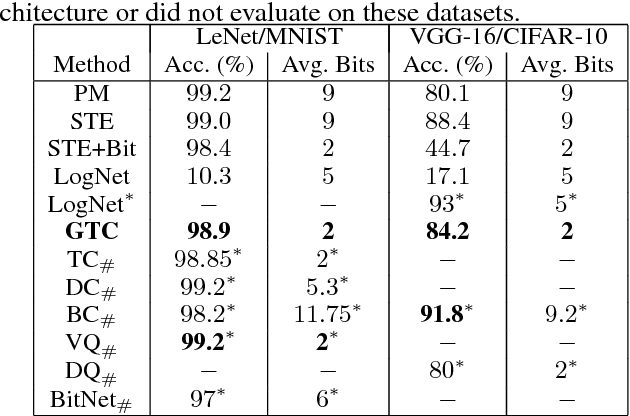
The use of deep neural networks in edge computing devices hinges on the balance between accuracy and complexity of computations. Ternary Connect (TC) \cite{lin2015neural} addresses this issue by restricting the parameters to three levels $-1, 0$, and $+1$, thus eliminating multiplications in the forward pass of the network during prediction. We propose Generalized Ternary Connect (GTC), which allows an arbitrary number of levels while at the same time eliminating multiplications by restricting the parameters to integer powers of two. The primary contribution is that GTC learns the number of levels and their values for each layer, jointly with the weights of the network in an end-to-end fashion. Experiments on MNIST and CIFAR-10 show that GTC naturally converges to an `almost binary' network for deep classification networks (e.g. VGG-16) and deep variational auto-encoders, with negligible loss of classification accuracy and comparable visual quality of generated samples respectively. We demonstrate superior compression and similar accuracy of GTC in comparison to several state-of-the-art methods for neural network compression. We conclude with simulations showing the potential benefits of GTC in hardware.