 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProvable Sim-to-Real Transfer via Offline Domain Randomization
Jun 11, 2025


Reinforcement-learning agents often struggle when deployed from simulation to the real-world. A dominant strategy for reducing the sim-to-real gap is domain randomization (DR) which trains the policy across many simulators produced by sampling dynamics parameters, but standard DR ignores offline data already available from the real system. We study offline domain randomization (ODR), which first fits a distribution over simulator parameters to an offline dataset. While a growing body of empirical work reports substantial gains with algorithms such as DROPO, the theoretical foundations of ODR remain largely unexplored. In this work, we (i) formalize ODR as a maximum-likelihood estimation over a parametric simulator family, (ii) prove consistency of this estimator under mild regularity and identifiability conditions, showing it converges to the true dynamics as the dataset grows, (iii) derive gap bounds demonstrating ODRs sim-to-real error is up to an O(M) factor tighter than uniform DR in the finite-simulator case (and analogous gains in the continuous setting), and (iv) introduce E-DROPO, a new version of DROPO which adds an entropy bonus to prevent variance collapse, yielding broader randomization and more robust zero-shot transfer in practice.
Cross-Domain Imitation Learning via Optimal Transport
Oct 14, 2021
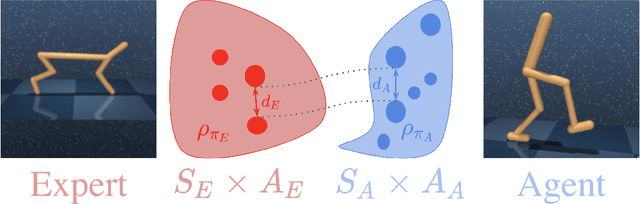
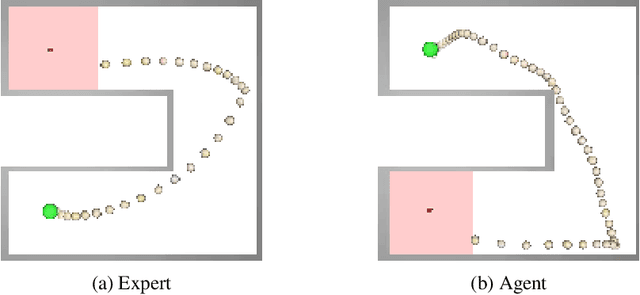

Cross-domain imitation learning studies how to leverage expert demonstrations of one agent to train an imitation agent with a different embodiment or morphology. Comparing trajectories and stationary distributions between the expert and imitation agents is challenging because they live on different systems that may not even have the same dimensionality. We propose Gromov-Wasserstein Imitation Learning (GWIL), a method for cross-domain imitation that uses the Gromov-Wasserstein distance to align and compare states between the different spaces of the agents. Our theory formally characterizes the scenarios where GWIL preserves optimality, revealing its possibilities and limitations. We demonstrate the effectiveness of GWIL in non-trivial continuous control domains ranging from simple rigid transformation of the expert domain to arbitrary transformation of the state-action space.
Scalable Online Planning via Reinforcement Learning Fine-Tuning
Sep 30, 2021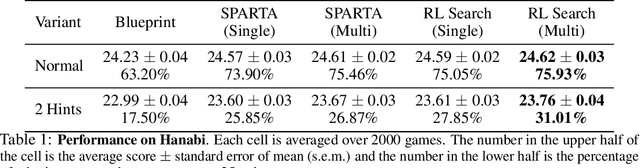
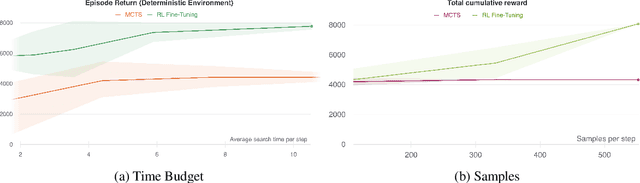


Lookahead search has been a critical component of recent AI successes, such as in the games of chess, go, and poker. However, the search methods used in these games, and in many other settings, are tabular. Tabular search methods do not scale well with the size of the search space, and this problem is exacerbated by stochasticity and partial observability. In this work we replace tabular search with online model-based fine-tuning of a policy neural network via reinforcement learning, and show that this approach outperforms state-of-the-art search algorithms in benchmark settings. In particular, we use our search algorithm to achieve a new state-of-the-art result in self-play Hanabi, and show the generality of our algorithm by also showing that it outperforms tabular search in the Atari game Ms. Pacman.
Explore and Control with Adversarial Surprise
Jul 12, 2021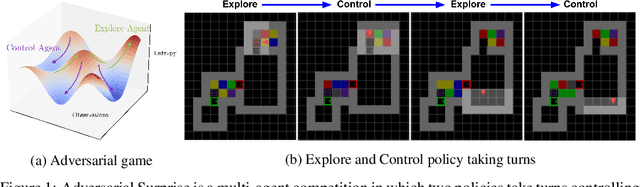
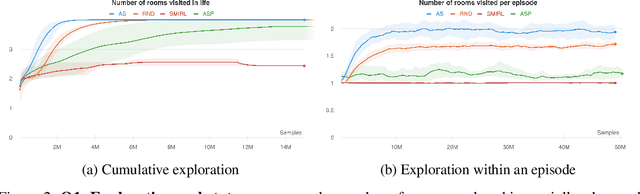
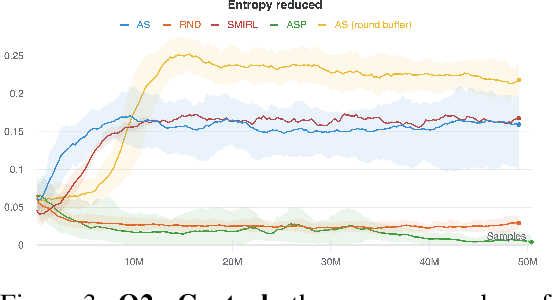
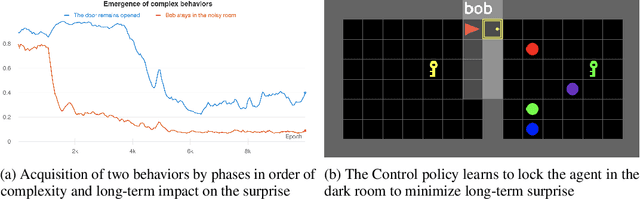
Reinforcement learning (RL) provides a framework for learning goal-directed policies given user-specified rewards. However, since designing rewards often requires substantial engineering effort, we are interested in the problem of learning without rewards, where agents must discover useful behaviors in the absence of task-specific incentives. Intrinsic motivation is a family of unsupervised RL techniques which develop general objectives for an RL agent to optimize that lead to better exploration or the discovery of skills. In this paper, we propose a new unsupervised RL technique based on an adversarial game which pits two policies against each other to compete over the amount of surprise an RL agent experiences. The policies each take turns controlling the agent. The Explore policy maximizes entropy, putting the agent into surprising or unfamiliar situations. Then, the Control policy takes over and seeks to recover from those situations by minimizing entropy. The game harnesses the power of multi-agent competition to drive the agent to seek out increasingly surprising parts of the environment while learning to gain mastery over them. We show empirically that our method leads to the emergence of complex skills by exhibiting clear phase transitions. Furthermore, we show both theoretically (via a latent state space coverage argument) and empirically that our method has the potential to be applied to the exploration of stochastic, partially-observed environments. We show that Adversarial Surprise learns more complex behaviors, and explores more effectively than competitive baselines, outperforming intrinsic motivation methods based on active inference, novelty-seeking (Random Network Distillation (RND)), and multi-agent unsupervised RL (Asymmetric Self-Play (ASP)) in MiniGrid, Atari and VizDoom environments.
Multi-Principal Assistance Games: Definition and Collegial Mechanisms
Dec 29, 2020We introduce the concept of a multi-principal assistance game (MPAG), and circumvent an obstacle in social choice theory, Gibbard's theorem, by using a sufficiently collegial preference inference mechanism. In an MPAG, a single agent assists N human principals who may have widely different preferences. MPAGs generalize assistance games, also known as cooperative inverse reinforcement learning games. We analyze in particular a generalization of apprenticeship learning in which the humans first perform some work to obtain utility and demonstrate their preferences, and then the robot acts to further maximize the sum of human payoffs. We show in this setting that if the game is sufficiently collegial, i.e. if the humans are responsible for obtaining a sufficient fraction of the rewards through their own actions, then their preferences are straightforwardly revealed through their work. This revelation mechanism is non-dictatorial, does not limit the possible outcomes to two alternatives, and is dominant-strategy incentive-compatible.
Multi-Principal Assistance Games
Jul 19, 2020
Assistance games (also known as cooperative inverse reinforcement learning games) have been proposed as a model for beneficial AI, wherein a robotic agent must act on behalf of a human principal but is initially uncertain about the humans payoff function. This paper studies multi-principal assistance games, which cover the more general case in which the robot acts on behalf of N humans who may have widely differing payoffs. Impossibility theorems in social choice theory and voting theory can be applied to such games, suggesting that strategic behavior by the human principals may complicate the robots task in learning their payoffs. We analyze in particular a bandit apprentice game in which the humans act first to demonstrate their individual preferences for the arms and then the robot acts to maximize the sum of human payoffs. We explore the extent to which the cost of choosing suboptimal arms reduces the incentive to mislead, a form of natural mechanism design. In this context we propose a social choice method that uses shared control of a system to combine preference inference with social welfare optimization.
Biadversarial Variational Autoencoder
Feb 12, 2019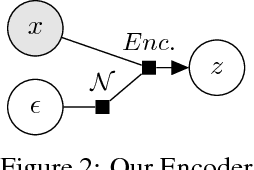
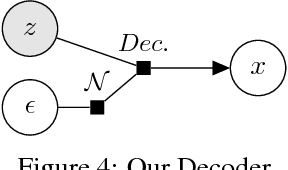
In the original version of the Variational Autoencoder, Kingma et al. assume Gaussian distributions for the approximate posterior during the inference and for the output during the generative process. This assumptions are good for computational reasons, e.g. we can easily optimize the parameters of a neural network using the reparametrization trick and the KL divergence between two Gaussians can be computed in closed form. However it results in blurry images due to its difficulty to represent multimodal distributions. We show that using two adversarial networks, we can optimize the parameters without any Gaussian assumptions.