 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTASRA: a Taxonomy and Analysis of Societal-Scale Risks from AI
Jun 14, 2023


While several recent works have identified societal-scale and extinction-level risks to humanity arising from artificial intelligence, few have attempted an {\em exhaustive taxonomy} of such risks. Many exhaustive taxonomies are possible, and some are useful -- particularly if they reveal new risks or practical approaches to safety. This paper explores a taxonomy based on accountability: whose actions lead to the risk, are the actors unified, and are they deliberate? We also provide stories to illustrate how the various risk types could each play out, including risks arising from unanticipated interactions of many AI systems, as well as risks from deliberate misuse, for which combined technical and policy solutions are indicated.
WordSig: QR streams enabling platform-independent self-identification that's impossible to deepfake
Jul 15, 2022

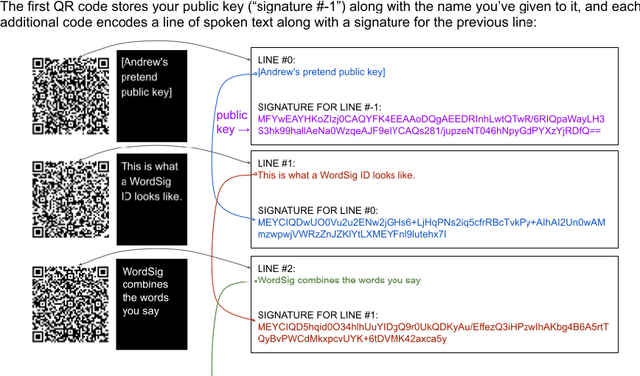
Deepfakes can degrade the fabric of society by limiting our ability to trust video content from leaders, authorities, and even friends. Cryptographically secure digital signatures may be used by video streaming platforms to endorse content, but these signatures are applied by the content distributor rather than the participants in the video. We introduce WordSig, a simple protocol allowing video participants to digitally sign the words they speak using a stream of QR codes, and allowing viewers to verify the consistency of signatures across videos. This allows establishing a trusted connection between the viewer and the participant that is not mediated by the content distributor. Given the widespread adoption of QR codes for distributing hyperlinks and vaccination records, and the increasing prevalence of celebrity deepfakes, 2022 or later may be a good time for public figures to begin using and promoting QR-based self-authentication tools.
For Learning in Symmetric Teams, Local Optima are Global Nash Equilibria
Jul 07, 2022

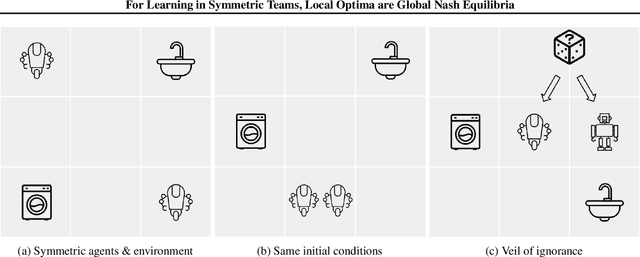
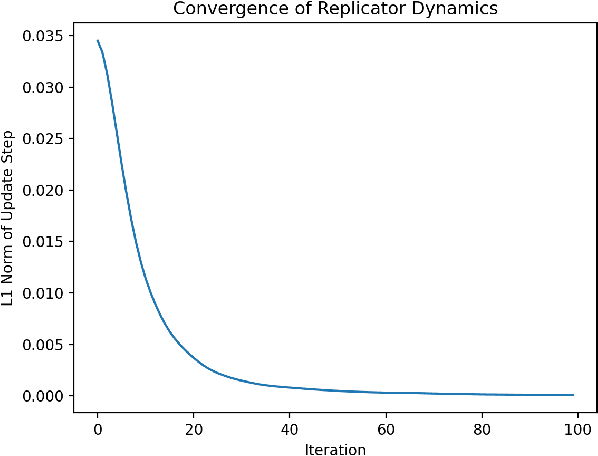
Although it has been known since the 1970s that a globally optimal strategy profile in a common-payoff game is a Nash equilibrium, global optimality is a strict requirement that limits the result's applicability. In this work, we show that any locally optimal symmetric strategy profile is also a (global) Nash equilibrium. Furthermore, we show that this result is robust to perturbations to the common payoff and to the local optimum. Applied to machine learning, our result provides a global guarantee for any gradient method that finds a local optimum in symmetric strategy space. While this result indicates stability to unilateral deviation, we nevertheless identify broad classes of games where mixed local optima are unstable under joint, asymmetric deviations. We analyze the prevalence of instability by running learning algorithms in a suite of symmetric games, and we conclude by discussing the applicability of our results to multi-agent RL, cooperative inverse RL, and decentralized POMDPs.
Human irrationality: both bad and good for reward inference
Nov 12, 2021
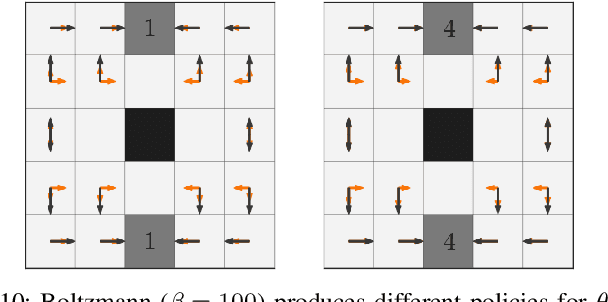

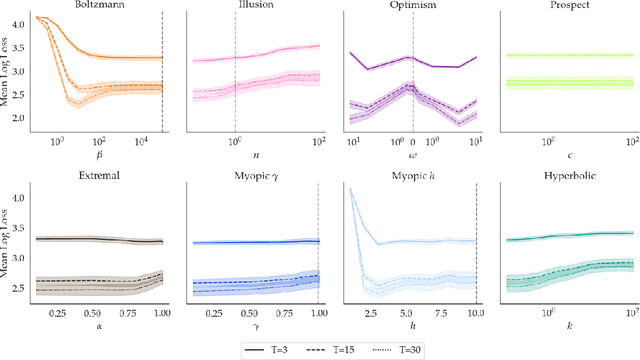
Assuming humans are (approximately) rational enables robots to infer reward functions by observing human behavior. But people exhibit a wide array of irrationalities, and our goal with this work is to better understand the effect they can have on reward inference. The challenge with studying this effect is that there are many types of irrationality, with varying degrees of mathematical formalization. We thus operationalize irrationality in the language of MDPs, by altering the Bellman optimality equation, and use this framework to study how these alterations would affect inference. We find that wrongly modeling a systematically irrational human as noisy-rational performs a lot worse than correctly capturing these biases -- so much so that it can be better to skip inference altogether and stick to the prior! More importantly, we show that an irrational human, when correctly modelled, can communicate more information about the reward than a perfectly rational human can. That is, if a robot has the correct model of a human's irrationality, it can make an even stronger inference than it ever could if the human were rational. Irrationality fundamentally helps rather than hinder reward inference, but it needs to be correctly accounted for.
Detecting Modularity in Deep Neural Networks
Oct 13, 2021
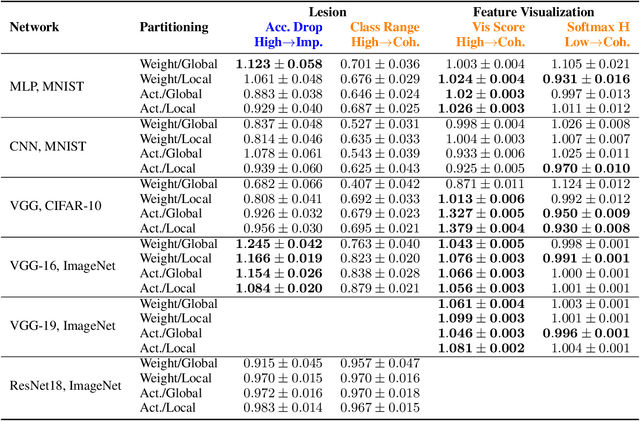
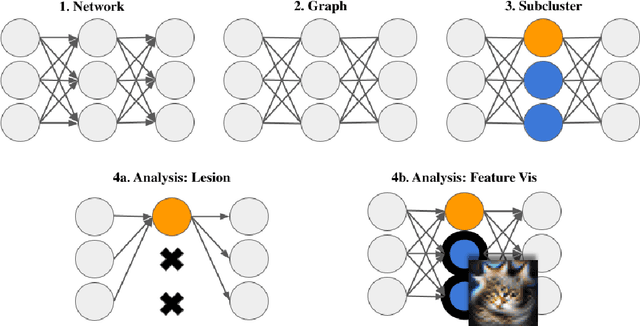
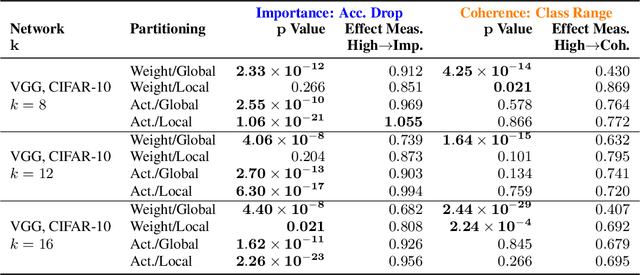
A neural network is modular to the extent that parts of its computational graph (i.e. structure) can be represented as performing some comprehensible subtask relevant to the overall task (i.e. functionality). Are modern deep neural networks modular? How can this be quantified? In this paper, we consider the problem of assessing the modularity exhibited by a partitioning of a network's neurons. We propose two proxies for this: importance, which reflects how crucial sets of neurons are to network performance; and coherence, which reflects how consistently their neurons associate with features of the inputs. To measure these proxies, we develop a set of statistical methods based on techniques conventionally used to interpret individual neurons. We apply the proxies to partitionings generated by spectrally clustering a graph representation of the network's neurons with edges determined either by network weights or correlations of activations. We show that these partitionings, even ones based only on weights (i.e. strictly from non-runtime analysis), reveal groups of neurons that are important and coherent. These results suggest that graph-based partitioning can reveal modularity and help us understand how deep neural networks function.
Clusterability in Neural Networks
Mar 04, 2021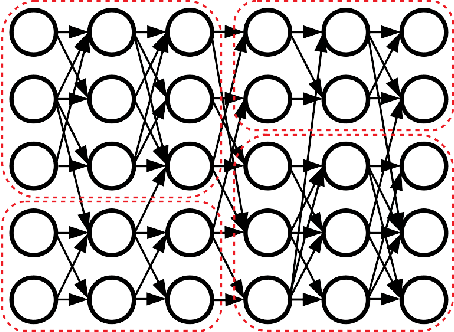

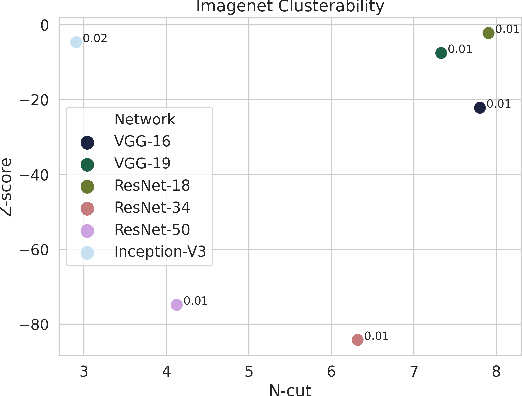

The learned weights of a neural network have often been considered devoid of scrutable internal structure. In this paper, however, we look for structure in the form of clusterability: how well a network can be divided into groups of neurons with strong internal connectivity but weak external connectivity. We find that a trained neural network is typically more clusterable than randomly initialized networks, and often clusterable relative to random networks with the same distribution of weights. We also exhibit novel methods to promote clusterability in neural network training, and find that in multi-layer perceptrons they lead to more clusterable networks with little reduction in accuracy. Understanding and controlling the clusterability of neural networks will hopefully render their inner workings more interpretable to engineers by facilitating partitioning into meaningful clusters.
Accumulating Risk Capital Through Investing in Cooperation
Jan 25, 2021
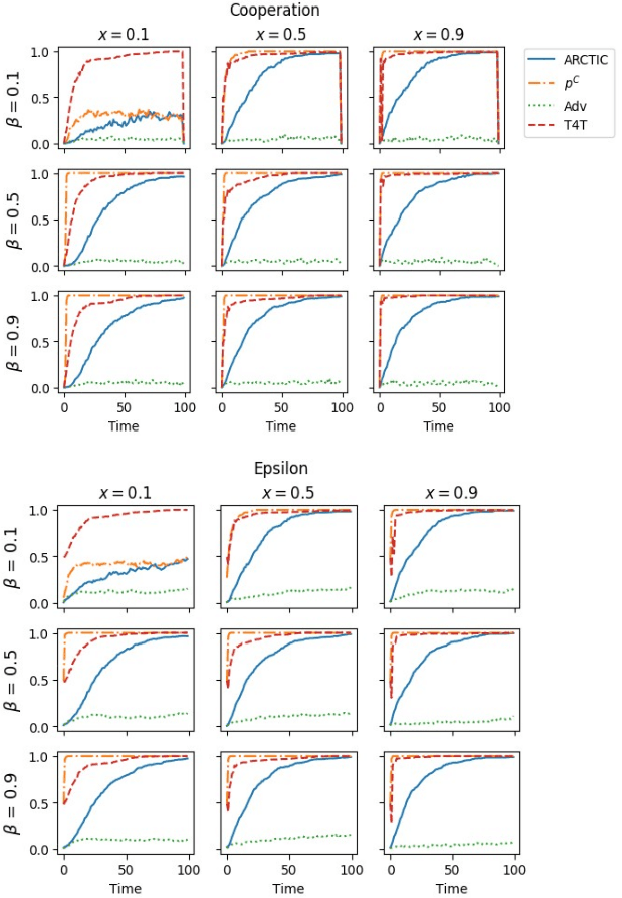
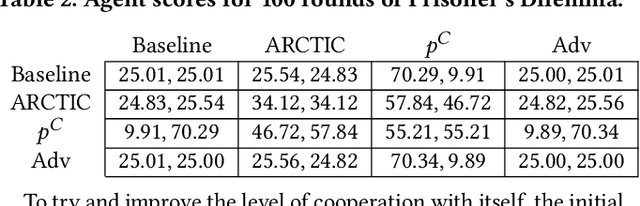
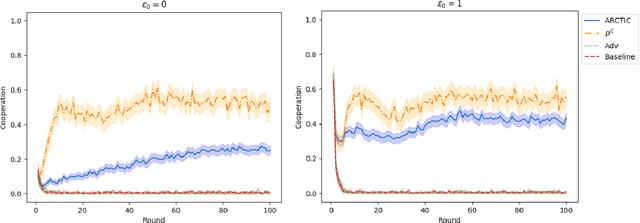
Recent work on promoting cooperation in multi-agent learning has resulted in many methods which successfully promote cooperation at the cost of becoming more vulnerable to exploitation by malicious actors. We show that this is an unavoidable trade-off and propose an objective which balances these concerns, promoting both safety and long-term cooperation. Moreover, the trade-off between safety and cooperation is not severe, and you can receive exponentially large returns through cooperation from a small amount of risk. We study both an exact solution method and propose a method for training policies that targets this objective, Accumulating Risk Capital Through Investing in Cooperation (ARCTIC), and evaluate them in iterated Prisoner's Dilemma and Stag Hunt.
Multi-Principal Assistance Games: Definition and Collegial Mechanisms
Dec 29, 2020We introduce the concept of a multi-principal assistance game (MPAG), and circumvent an obstacle in social choice theory, Gibbard's theorem, by using a sufficiently collegial preference inference mechanism. In an MPAG, a single agent assists N human principals who may have widely different preferences. MPAGs generalize assistance games, also known as cooperative inverse reinforcement learning games. We analyze in particular a generalization of apprenticeship learning in which the humans first perform some work to obtain utility and demonstrate their preferences, and then the robot acts to further maximize the sum of human payoffs. We show in this setting that if the game is sufficiently collegial, i.e. if the humans are responsible for obtaining a sufficient fraction of the rewards through their own actions, then their preferences are straightforwardly revealed through their work. This revelation mechanism is non-dictatorial, does not limit the possible outcomes to two alternatives, and is dominant-strategy incentive-compatible.
Emergent Complexity and Zero-shot Transfer via Unsupervised Environment Design
Dec 03, 2020

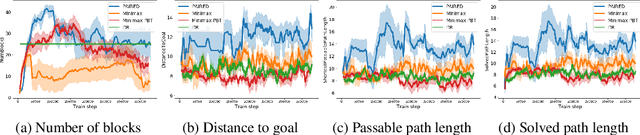
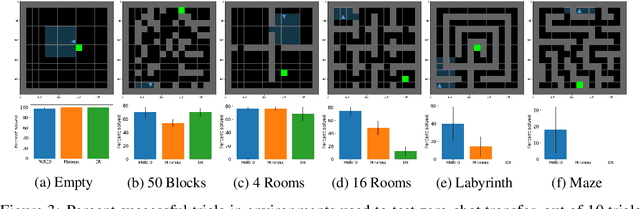
A wide range of reinforcement learning (RL) problems - including robustness, transfer learning, unsupervised RL, and emergent complexity - require specifying a distribution of tasks or environments in which a policy will be trained. However, creating a useful distribution of environments is error prone, and takes a significant amount of developer time and effort. We propose Unsupervised Environment Design (UED) as an alternative paradigm, where developers provide environments with unknown parameters, and these parameters are used to automatically produce a distribution over valid, solvable environments. Existing approaches to automatically generating environments suffer from common failure modes: domain randomization cannot generate structure or adapt the difficulty of the environment to the agent's learning progress, and minimax adversarial training leads to worst-case environments that are often unsolvable. To generate structured, solvable environments for our protagonist agent, we introduce a second, antagonist agent that is allied with the environment-generating adversary. The adversary is motivated to generate environments which maximize regret, defined as the difference between the protagonist and antagonist agent's return. We call our technique Protagonist Antagonist Induced Regret Environment Design (PAIRED). Our experiments demonstrate that PAIRED produces a natural curriculum of increasingly complex environments, and PAIRED agents achieve higher zero-shot transfer performance when tested in highly novel environments.
The MAGICAL Benchmark for Robust Imitation
Nov 01, 2020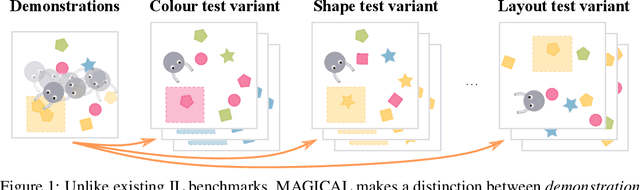
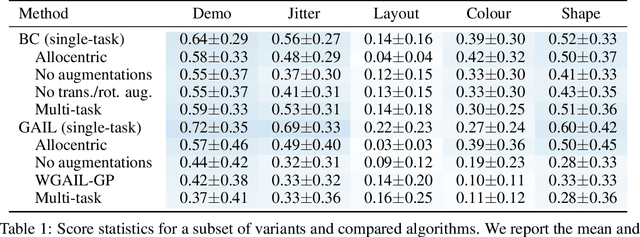


Imitation Learning (IL) algorithms are typically evaluated in the same environment that was used to create demonstrations. This rewards precise reproduction of demonstrations in one particular environment, but provides little information about how robustly an algorithm can generalise the demonstrator's intent to substantially different deployment settings. This paper presents the MAGICAL benchmark suite, which permits systematic evaluation of generalisation by quantifying robustness to different kinds of distribution shift that an IL algorithm is likely to encounter in practice. Using the MAGICAL suite, we confirm that existing IL algorithms overfit significantly to the context in which demonstrations are provided. We also show that standard methods for reducing overfitting are effective at creating narrow perceptual invariances, but are not sufficient to enable transfer to contexts that require substantially different behaviour, which suggests that new approaches will be needed in order to robustly generalise demonstrator intent. Code and data for the MAGICAL suite is available at https://github.com/qxcv/magical/.