 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the generalization of language models from in-context learning and finetuning: a controlled study
May 01, 2025Large language models exhibit exciting capabilities, yet can show surprisingly narrow generalization from finetuning -- from failing to generalize to simple reversals of relations they are trained on, to missing logical deductions that can be made from trained information. These failures to generalize from fine-tuning can hinder practical application of these models. However, language models' in-context learning shows different inductive biases, and can generalize better in some of these cases. Here, we explore these differences in generalization between in-context- and fine-tuning-based learning. To do so, we constructed several novel datasets to evaluate and improve models' ability to generalize from finetuning data. The datasets are constructed to isolate the knowledge in the dataset from that in pretraining, to create clean tests of generalization. We expose pretrained large models to controlled subsets of the information in these datasets -- either in context, or through fine-tuning -- and evaluate their performance on test sets that require various types of generalization. We find overall that in data-matched settings, in-context learning can generalize more flexibly than fine-tuning (though we also find some qualifications of prior findings, such as cases when fine-tuning can generalize to reversals embedded in a larger structure of knowledge). We build on these findings to propose a method to enable improved generalization from fine-tuning: adding in-context inferences to finetuning data. We show that this method improves generalization across various splits of our datasets and other benchmarks. Our results have implications for understanding the inductive biases of different modes of learning in language models, and practically improving their performance.
Uncovering Layer-Dependent Activation Sparsity Patterns in ReLU Transformers
Jul 10, 2024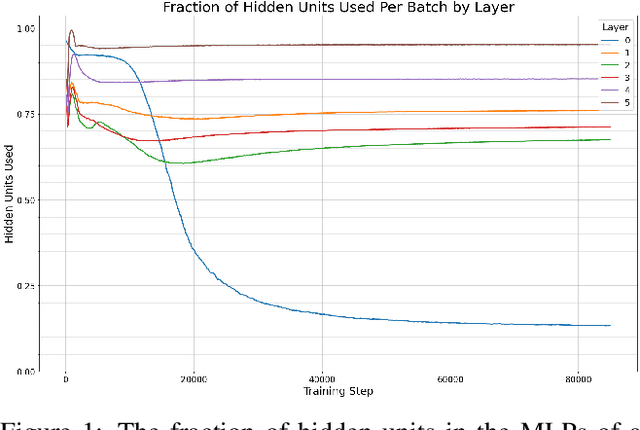
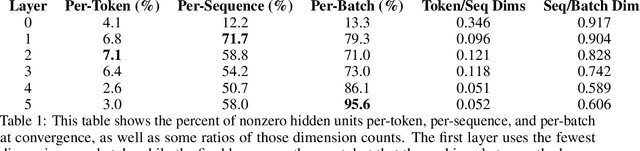

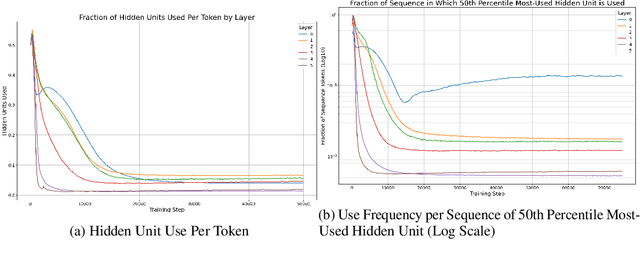
Previous work has demonstrated that MLPs within ReLU Transformers exhibit high levels of sparsity, with many of their activations equal to zero for any given token. We build on that work to more deeply explore how token-level sparsity evolves over the course of training, and how it connects to broader sparsity patterns over the course of a sequence or batch, demonstrating that the different layers within small transformers exhibit distinctly layer-specific patterns on both of these fronts. In particular, we demonstrate that the first and last layer of the network have distinctive and in many ways inverted relationships to sparsity, and explore implications for the structure of feature representations being learned at different depths of the model. We additionally explore the phenomenon of ReLU dimensions "turning off", and show evidence suggesting that "neuron death" is being primarily driven by the dynamics of training, rather than simply occurring randomly or accidentally as a result of outliers.
An Empirical Investigation of Representation Learning for Imitation
May 16, 2022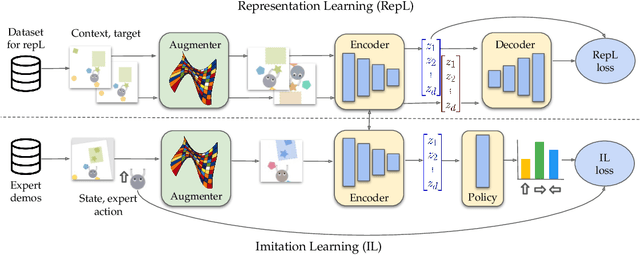
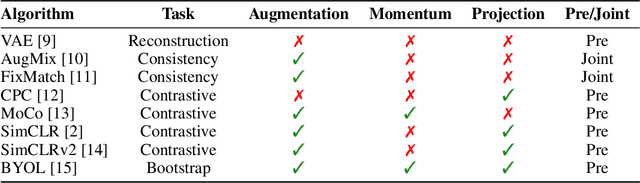

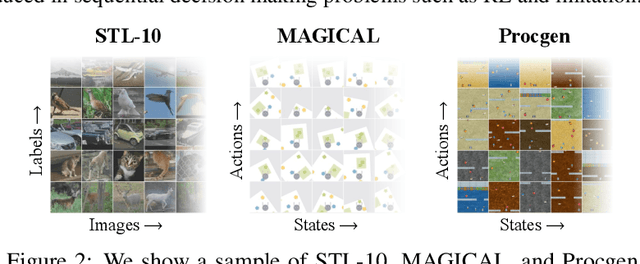
Imitation learning often needs a large demonstration set in order to handle the full range of situations that an agent might find itself in during deployment. However, collecting expert demonstrations can be expensive. Recent work in vision, reinforcement learning, and NLP has shown that auxiliary representation learning objectives can reduce the need for large amounts of expensive, task-specific data. Our Empirical Investigation of Representation Learning for Imitation (EIRLI) investigates whether similar benefits apply to imitation learning. We propose a modular framework for constructing representation learning algorithms, then use our framework to evaluate the utility of representation learning for imitation across several environment suites. In the settings we evaluate, we find that existing algorithms for image-based representation learning provide limited value relative to a well-tuned baseline with image augmentations. To explain this result, we investigate differences between imitation learning and other settings where representation learning has provided significant benefit, such as image classification. Finally, we release a well-documented codebase which both replicates our findings and provides a modular framework for creating new representation learning algorithms out of reusable components.
Retrospective on the 2021 BASALT Competition on Learning from Human Feedback
Apr 14, 2022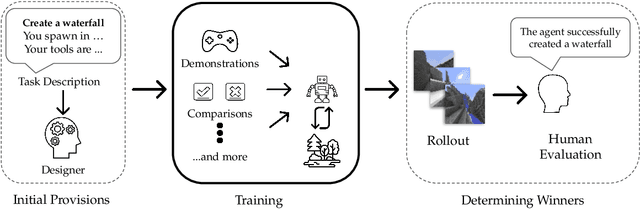
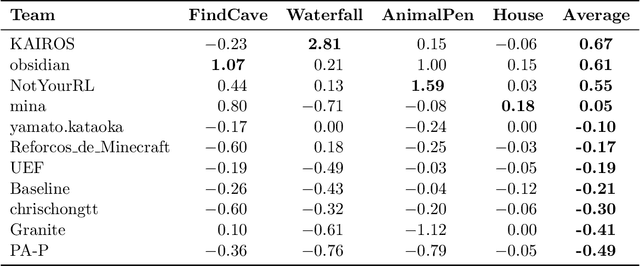
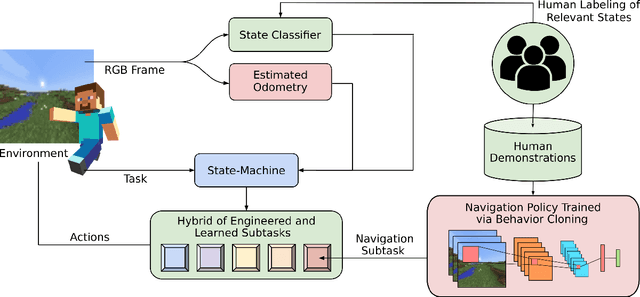
We held the first-ever MineRL Benchmark for Agents that Solve Almost-Lifelike Tasks (MineRL BASALT) Competition at the Thirty-fifth Conference on Neural Information Processing Systems (NeurIPS 2021). The goal of the competition was to promote research towards agents that use learning from human feedback (LfHF) techniques to solve open-world tasks. Rather than mandating the use of LfHF techniques, we described four tasks in natural language to be accomplished in the video game Minecraft, and allowed participants to use any approach they wanted to build agents that could accomplish the tasks. Teams developed a diverse range of LfHF algorithms across a variety of possible human feedback types. The three winning teams implemented significantly different approaches while achieving similar performance. Interestingly, their approaches performed well on different tasks, validating our choice of tasks to include in the competition. While the outcomes validated the design of our competition, we did not get as many participants and submissions as our sister competition, MineRL Diamond. We speculate about the causes of this problem and suggest improvements for future iterations of the competition.
Detecting Modularity in Deep Neural Networks
Oct 13, 2021
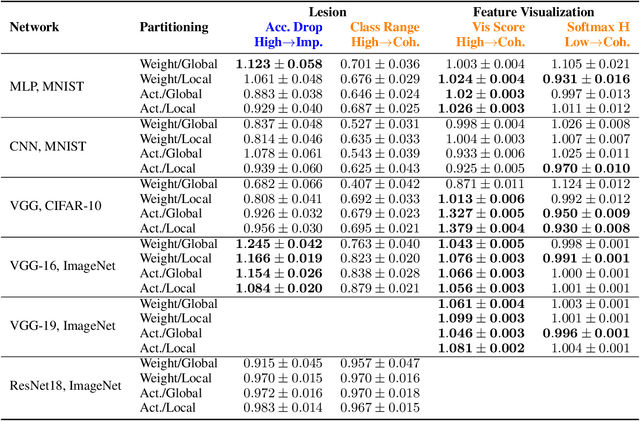
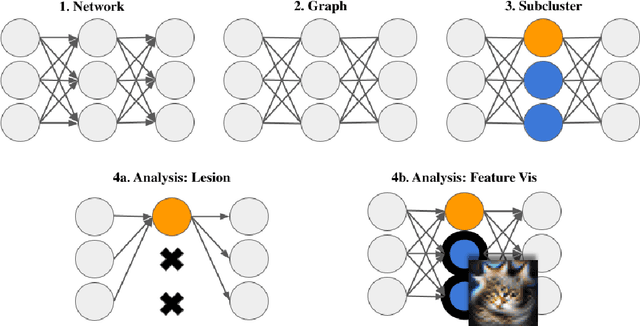
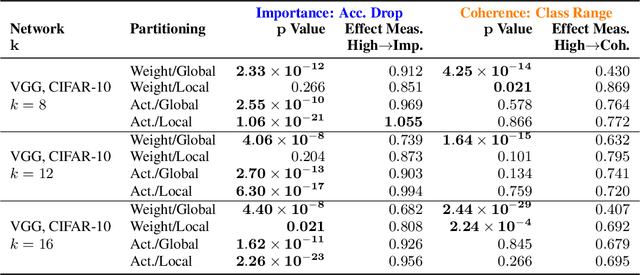
A neural network is modular to the extent that parts of its computational graph (i.e. structure) can be represented as performing some comprehensible subtask relevant to the overall task (i.e. functionality). Are modern deep neural networks modular? How can this be quantified? In this paper, we consider the problem of assessing the modularity exhibited by a partitioning of a network's neurons. We propose two proxies for this: importance, which reflects how crucial sets of neurons are to network performance; and coherence, which reflects how consistently their neurons associate with features of the inputs. To measure these proxies, we develop a set of statistical methods based on techniques conventionally used to interpret individual neurons. We apply the proxies to partitionings generated by spectrally clustering a graph representation of the network's neurons with edges determined either by network weights or correlations of activations. We show that these partitionings, even ones based only on weights (i.e. strictly from non-runtime analysis), reveal groups of neurons that are important and coherent. These results suggest that graph-based partitioning can reveal modularity and help us understand how deep neural networks function.
The MineRL BASALT Competition on Learning from Human Feedback
Jul 05, 2021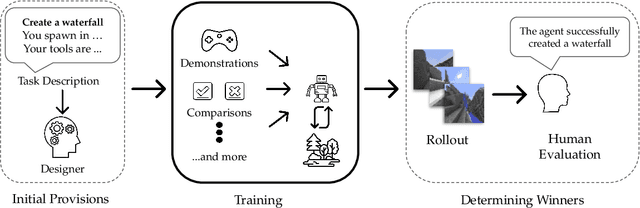

The last decade has seen a significant increase of interest in deep learning research, with many public successes that have demonstrated its potential. As such, these systems are now being incorporated into commercial products. With this comes an additional challenge: how can we build AI systems that solve tasks where there is not a crisp, well-defined specification? While multiple solutions have been proposed, in this competition we focus on one in particular: learning from human feedback. Rather than training AI systems using a predefined reward function or using a labeled dataset with a predefined set of categories, we instead train the AI system using a learning signal derived from some form of human feedback, which can evolve over time as the understanding of the task changes, or as the capabilities of the AI system improve. The MineRL BASALT competition aims to spur forward research on this important class of techniques. We design a suite of four tasks in Minecraft for which we expect it will be hard to write down hardcoded reward functions. These tasks are defined by a paragraph of natural language: for example, "create a waterfall and take a scenic picture of it", with additional clarifying details. Participants must train a separate agent for each task, using any method they want. Agents are then evaluated by humans who have read the task description. To help participants get started, we provide a dataset of human demonstrations on each of the four tasks, as well as an imitation learning baseline that leverages these demonstrations. Our hope is that this competition will improve our ability to build AI systems that do what their designers intend them to do, even when the intent cannot be easily formalized. Besides allowing AI to solve more tasks, this can also enable more effective regulation of AI systems, as well as making progress on the value alignment problem.
Clusterability in Neural Networks
Mar 04, 2021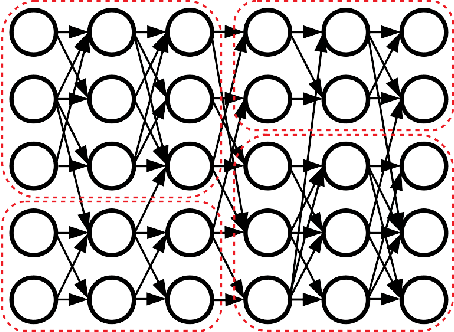

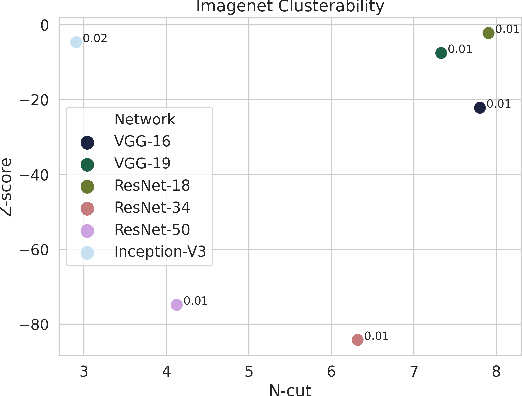

The learned weights of a neural network have often been considered devoid of scrutable internal structure. In this paper, however, we look for structure in the form of clusterability: how well a network can be divided into groups of neurons with strong internal connectivity but weak external connectivity. We find that a trained neural network is typically more clusterable than randomly initialized networks, and often clusterable relative to random networks with the same distribution of weights. We also exhibit novel methods to promote clusterability in neural network training, and find that in multi-layer perceptrons they lead to more clusterable networks with little reduction in accuracy. Understanding and controlling the clusterability of neural networks will hopefully render their inner workings more interpretable to engineers by facilitating partitioning into meaningful clusters.
Neural Networks are Surprisingly Modular
Mar 11, 2020

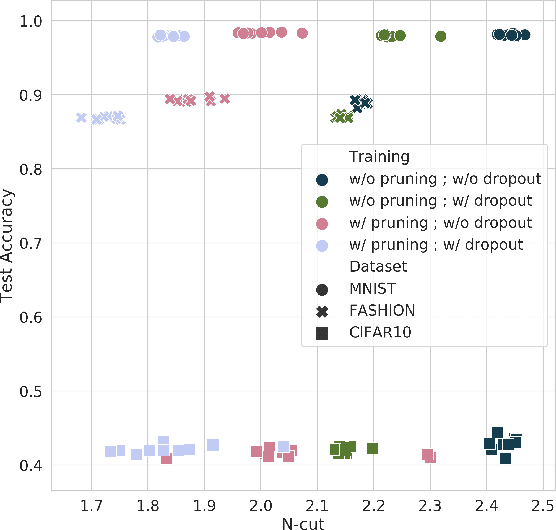

The learned weights of a neural network are often considered devoid of scrutable internal structure. In order to attempt to discern structure in these weights, we introduce a measurable notion of modularity for multi-layer perceptrons (MLPs), and investigate the modular structure of MLPs trained on datasets of small images. Our notion of modularity comes from the graph clustering literature: a "module" is a set of neurons with strong internal connectivity but weak external connectivity. We find that MLPs that undergo training and weight pruning are often significantly more modular than random networks with the same distribution of weights. Interestingly, they are much more modular when trained with dropout. Further analysis shows that this modularity seems to arise mostly for networks trained on learnable datasets. We also present exploratory analyses of the importance of different modules for performance and how modules depend on each other. Understanding the modular structure of neural networks, when such structure exists, will hopefully render their inner workings more interpretable to engineers.
Adversarial Policies: Attacking Deep Reinforcement Learning
May 25, 2019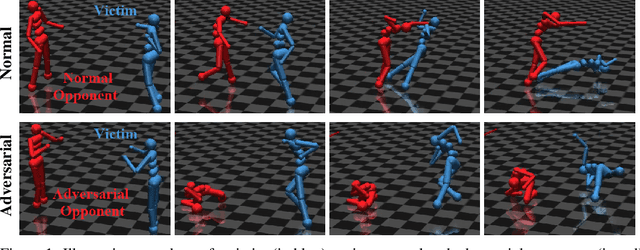

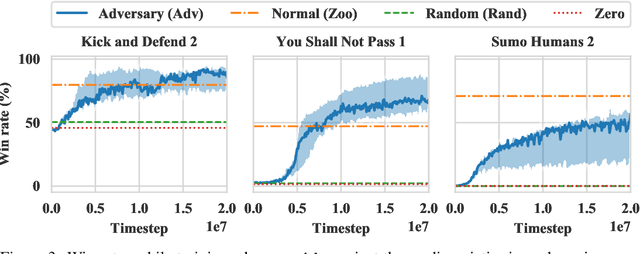
Deep reinforcement learning (RL) policies are known to be vulnerable to adversarial perturbations to their observations, similar to adversarial examples for classifiers. However, an attacker is not usually able to directly modify another agent's observations. This might lead one to wonder: is it possible to attack an RL agent simply by choosing an adversarial policy acting in a multi-agent environment so as to create natural observations that are adversarial? We demonstrate the existence of adversarial policies in zero-sum games between simulated humanoid robots with proprioceptive observations, against state-of-the-art victims trained via self-play to be robust to opponents. The adversarial policies reliably win against the victims but generate seemingly random and uncoordinated behavior. We find that these policies are more successful in high-dimensional environments, and induce substantially different activations in the victim policy network than when the victim plays against a normal opponent. Videos are available at http://adversarialpolicies.github.io.
ALOHA: Auxiliary Loss Optimization for Hypothesis Augmentation
Mar 13, 2019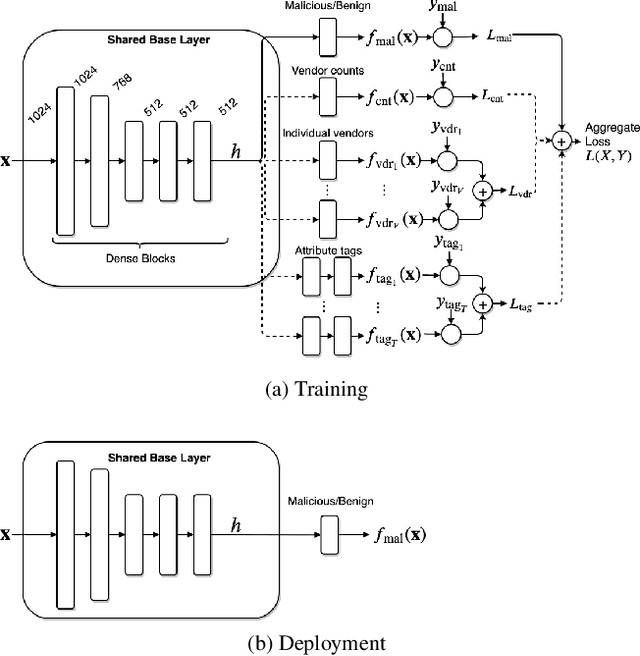
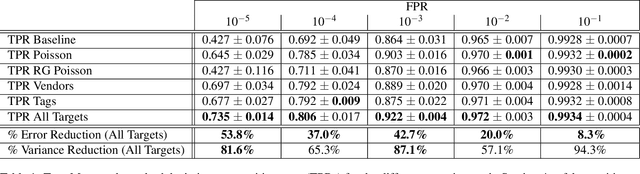
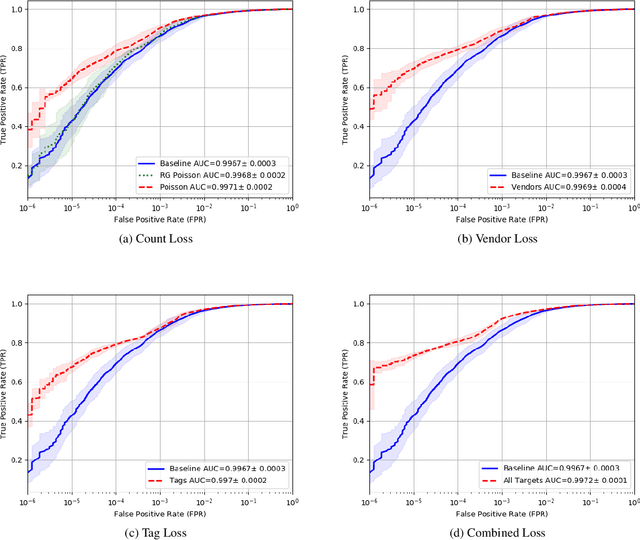
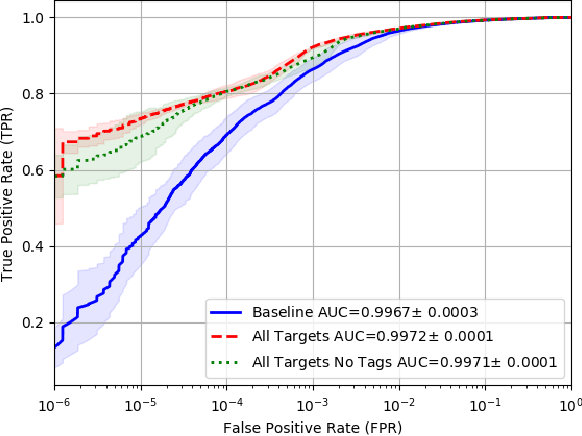
Malware detection is a popular application of Machine Learning for Information Security (ML-Sec), in which an ML classifier is trained to predict whether a given file is malware or benignware. Parameters of this classifier are typically optimized such that outputs from the model over a set of input samples most closely match the samples' true malicious/benign (1/0) target labels. However, there are often a number of other sources of contextual metadata for each malware sample, beyond an aggregate malicious/benign label, including multiple labeling sources and malware type information (e.g., ransomware, trojan, etc.), which we can feed to the classifier as auxiliary prediction targets. In this work, we fit deep neural networks to multiple additional targets derived from metadata in a threat intelligence feed for Portable Executable (PE) malware and benignware, including a multi-source malicious/benign loss, a count loss on multi-source detections, and a semantic malware attribute tag loss. We find that incorporating multiple auxiliary loss terms yields a marked improvement in performance on the main detection task. We also demonstrate that these gains likely stem from a more informed neural network representation and are not due to a regularization artifact of multi-target learning. Our auxiliary loss architecture yields a significant reduction in detection error rate (false negatives) of 42.6% at a false positive rate (FPR) of $10^{-3}$ when compared to a similar model with only one target, and a decrease of 53.8% at $10^{-5}$ FPR.