 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Distilled Retrieval-Augmented Guarding Model for Online Malicious Intent Detection
Sep 18, 2025



With the deployment of Large Language Models (LLMs) in interactive applications, online malicious intent detection has become increasingly critical. However, existing approaches fall short of handling diverse and complex user queries in real time. To address these challenges, we introduce ADRAG (Adversarial Distilled Retrieval-Augmented Guard), a two-stage framework for robust and efficient online malicious intent detection. In the training stage, a high-capacity teacher model is trained on adversarially perturbed, retrieval-augmented inputs to learn robust decision boundaries over diverse and complex user queries. In the inference stage, a distillation scheduler transfers the teacher's knowledge into a compact student model, with a continually updated knowledge base collected online. At deployment, the compact student model leverages top-K similar safety exemplars retrieved from the online-updated knowledge base to enable both online and real-time malicious query detection. Evaluations across ten safety benchmarks demonstrate that ADRAG, with a 149M-parameter model, achieves 98.5% of WildGuard-7B's performance, surpasses GPT-4 by 3.3% and Llama-Guard-3-8B by 9.5% on out-of-distribution detection, while simultaneously delivering up to 5.6x lower latency at 300 queries per second (QPS) in real-time applications.
Stochastic Sampling from Deterministic Flow Models
Oct 03, 2024
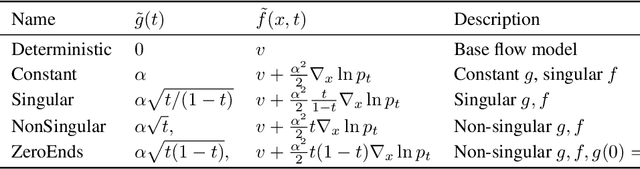

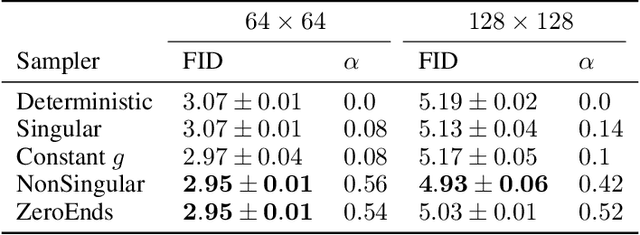
Deterministic flow models, such as rectified flows, offer a general framework for learning a deterministic transport map between two distributions, realized as the vector field for an ordinary differential equation (ODE). However, they are sensitive to model estimation and discretization errors and do not permit different samples conditioned on an intermediate state, limiting their application. We present a general method to turn the underlying ODE of such flow models into a family of stochastic differential equations (SDEs) that have the same marginal distributions. This method permits us to derive families of \emph{stochastic samplers}, for fixed (e.g., previously trained) \emph{deterministic} flow models, that continuously span the spectrum of deterministic and stochastic sampling, given access to the flow field and the score function. Our method provides additional degrees of freedom that help alleviate the issues with the deterministic samplers and empirically outperforms them. We empirically demonstrate advantages of our method on a toy Gaussian setup and on the large scale ImageNet generation task. Further, our family of stochastic samplers provide an additional knob for controlling the diversity of generation, which we qualitatively demonstrate in our experiments.
A Human-Inspired Reading Agent with Gist Memory of Very Long Contexts
Feb 23, 2024Current Large Language Models (LLMs) are not only limited to some maximum context length, but also are not able to robustly consume long inputs. To address these limitations, we propose ReadAgent, an LLM agent system that increases effective context length up to 20x in our experiments. Inspired by how humans interactively read long documents, we implement ReadAgent as a simple prompting system that uses the advanced language capabilities of LLMs to (1) decide what content to store together in a memory episode, (2) compress those memory episodes into short episodic memories called gist memories, and (3) take actions to look up passages in the original text if ReadAgent needs to remind itself of relevant details to complete a task. We evaluate ReadAgent against baselines using retrieval methods, using the original long contexts, and using the gist memories. These evaluations are performed on three long-document reading comprehension tasks: QuALITY, NarrativeQA, and QMSum. ReadAgent outperforms the baselines on all three tasks while extending the effective context window by 3-20x.
Weighted Ensemble Self-Supervised Learning
Nov 18, 2022


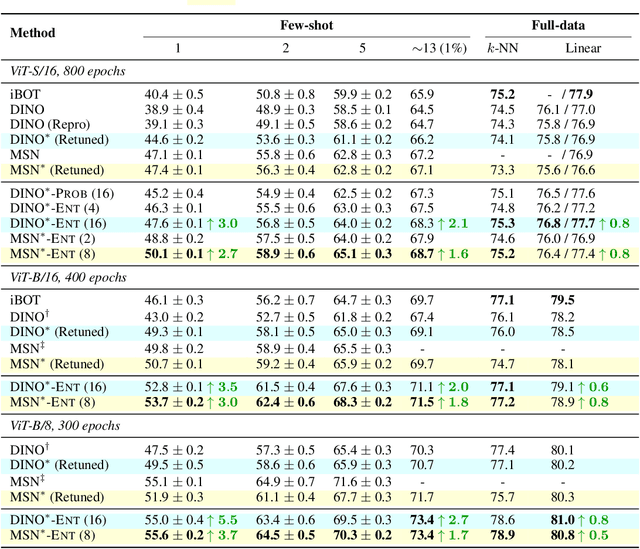
Ensembling has proven to be a powerful technique for boosting model performance, uncertainty estimation, and robustness in supervised learning. Advances in self-supervised learning (SSL) enable leveraging large unlabeled corpora for state-of-the-art few-shot and supervised learning performance. In this paper, we explore how ensemble methods can improve recent SSL techniques by developing a framework that permits data-dependent weighted cross-entropy losses. We refrain from ensembling the representation backbone; this choice yields an efficient ensemble method that incurs a small training cost and requires no architectural changes or computational overhead to downstream evaluation. The effectiveness of our method is demonstrated with two state-of-the-art SSL methods, DINO (Caron et al., 2021) and MSN (Assran et al., 2022). Our method outperforms both in multiple evaluation metrics on ImageNet-1K, particularly in the few-shot setting. We explore several weighting schemes and find that those which increase the diversity of ensemble heads lead to better downstream evaluation results. Thorough experiments yield improved prior art baselines which our method still surpasses; e.g., our overall improvement with MSN ViT-B/16 is 3.9 p.p. for 1-shot learning.
PI-QT-Opt: Predictive Information Improves Multi-Task Robotic Reinforcement Learning at Scale
Oct 15, 2022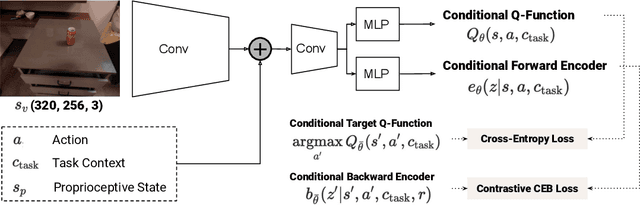



The predictive information, the mutual information between the past and future, has been shown to be a useful representation learning auxiliary loss for training reinforcement learning agents, as the ability to model what will happen next is critical to success on many control tasks. While existing studies are largely restricted to training specialist agents on single-task settings in simulation, in this work, we study modeling the predictive information for robotic agents and its importance for general-purpose agents that are trained to master a large repertoire of diverse skills from large amounts of data. Specifically, we introduce Predictive Information QT-Opt (PI-QT-Opt), a QT-Opt agent augmented with an auxiliary loss that learns representations of the predictive information to solve up to 297 vision-based robot manipulation tasks in simulation and the real world with a single set of parameters. We demonstrate that modeling the predictive information significantly improves success rates on the training tasks and leads to better zero-shot transfer to unseen novel tasks. Finally, we evaluate PI-QT-Opt on real robots, achieving substantial and consistent improvement over QT-Opt in multiple experimental settings of varying environments, skills, and multi-task configurations.
Deep Hierarchical Planning from Pixels
Jun 08, 2022
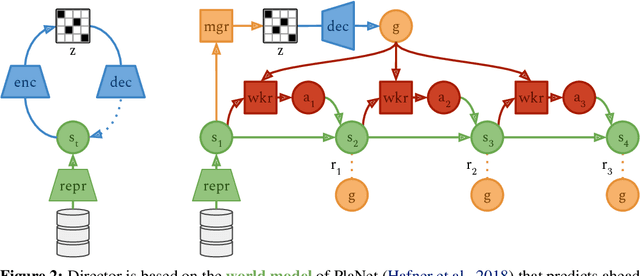

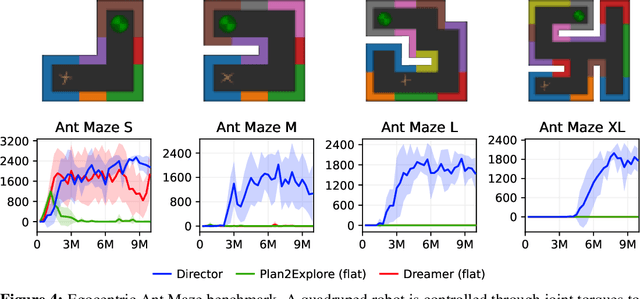
Intelligent agents need to select long sequences of actions to solve complex tasks. While humans easily break down tasks into subgoals and reach them through millions of muscle commands, current artificial intelligence is limited to tasks with horizons of a few hundred decisions, despite large compute budgets. Research on hierarchical reinforcement learning aims to overcome this limitation but has proven to be challenging, current methods rely on manually specified goal spaces or subtasks, and no general solution exists. We introduce Director, a practical method for learning hierarchical behaviors directly from pixels by planning inside the latent space of a learned world model. The high-level policy maximizes task and exploration rewards by selecting latent goals and the low-level policy learns to achieve the goals. Despite operating in latent space, the decisions are interpretable because the world model can decode goals into images for visualization. Director outperforms exploration methods on tasks with sparse rewards, including 3D maze traversal with a quadruped robot from an egocentric camera and proprioception, without access to the global position or top-down view that was used by prior work. Director also learns successful behaviors across a wide range of environments, including visual control, Atari games, and DMLab levels.
Multi-Game Decision Transformers
May 30, 2022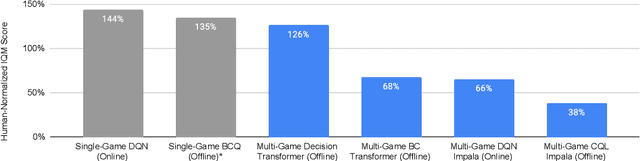

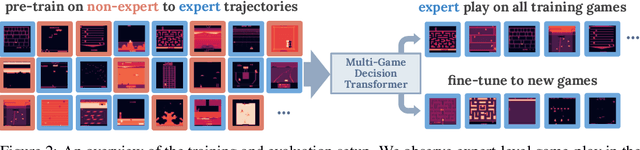
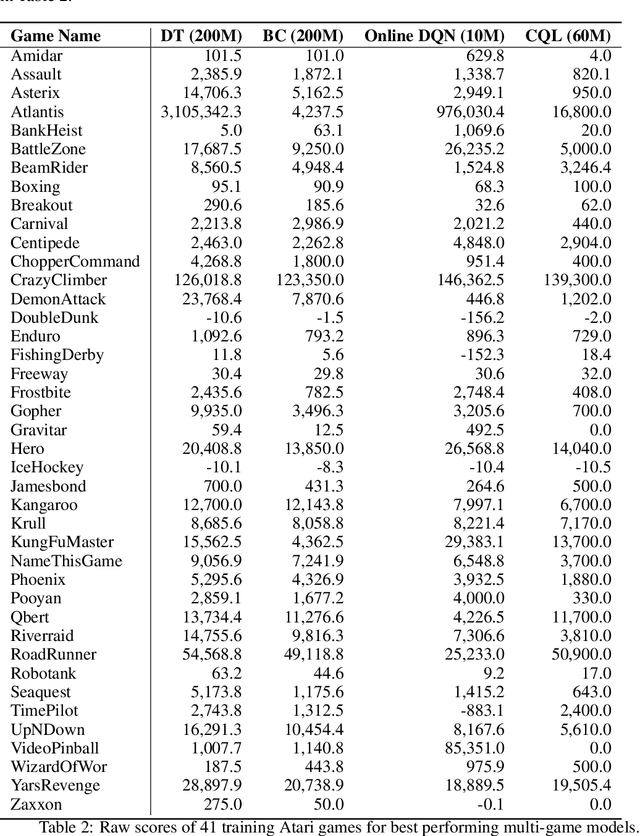
A longstanding goal of the field of AI is a strategy for compiling diverse experience into a highly capable, generalist agent. In the subfields of vision and language, this was largely achieved by scaling up transformer-based models and training them on large, diverse datasets. Motivated by this progress, we investigate whether the same strategy can be used to produce generalist reinforcement learning agents. Specifically, we show that a single transformer-based model - with a single set of weights - trained purely offline can play a suite of up to 46 Atari games simultaneously at close-to-human performance. When trained and evaluated appropriately, we find that the same trends observed in language and vision hold, including scaling of performance with model size and rapid adaptation to new games via fine-tuning. We compare several approaches in this multi-game setting, such as online and offline RL methods and behavioral cloning, and find that our Multi-Game Decision Transformer models offer the best scalability and performance. We release the pre-trained models and code to encourage further research in this direction. Additional information, videos and code can be seen at: sites.google.com/view/multi-game-transformers
An Empirical Investigation of Representation Learning for Imitation
May 16, 2022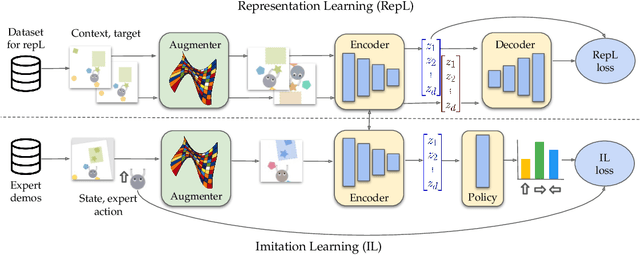
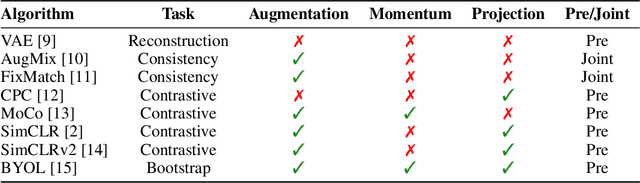

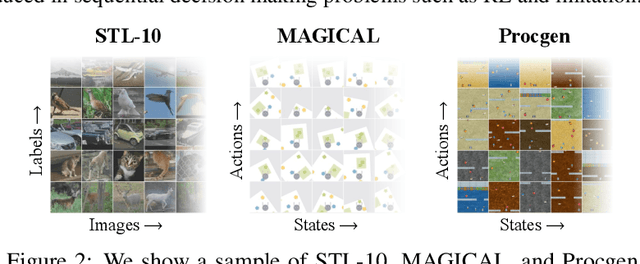
Imitation learning often needs a large demonstration set in order to handle the full range of situations that an agent might find itself in during deployment. However, collecting expert demonstrations can be expensive. Recent work in vision, reinforcement learning, and NLP has shown that auxiliary representation learning objectives can reduce the need for large amounts of expensive, task-specific data. Our Empirical Investigation of Representation Learning for Imitation (EIRLI) investigates whether similar benefits apply to imitation learning. We propose a modular framework for constructing representation learning algorithms, then use our framework to evaluate the utility of representation learning for imitation across several environment suites. In the settings we evaluate, we find that existing algorithms for image-based representation learning provide limited value relative to a well-tuned baseline with image augmentations. To explain this result, we investigate differences between imitation learning and other settings where representation learning has provided significant benefit, such as image classification. Finally, we release a well-documented codebase which both replicates our findings and provides a modular framework for creating new representation learning algorithms out of reusable components.
Compressive Visual Representations
Sep 29, 2021


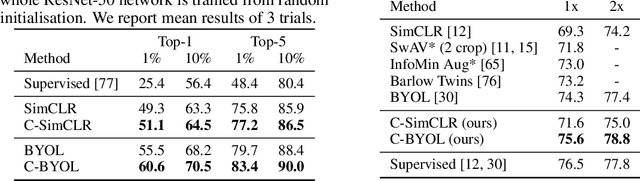
Learning effective visual representations that generalize well without human supervision is a fundamental problem in order to apply Machine Learning to a wide variety of tasks. Recently, two families of self-supervised methods, contrastive learning and latent bootstrapping, exemplified by SimCLR and BYOL respectively, have made significant progress. In this work, we hypothesize that adding explicit information compression to these algorithms yields better and more robust representations. We verify this by developing SimCLR and BYOL formulations compatible with the Conditional Entropy Bottleneck (CEB) objective, allowing us to both measure and control the amount of compression in the learned representation, and observe their impact on downstream tasks. Furthermore, we explore the relationship between Lipschitz continuity and compression, showing a tractable lower bound on the Lipschitz constant of the encoders we learn. As Lipschitz continuity is closely related to robustness, this provides a new explanation for why compressed models are more robust. Our experiments confirm that adding compression to SimCLR and BYOL significantly improves linear evaluation accuracies and model robustness across a wide range of domain shifts. In particular, the compressed version of BYOL achieves 76.0% Top-1 linear evaluation accuracy on ImageNet with ResNet-50, and 78.8% with ResNet-50 2x.
VIB is Half Bayes
Nov 17, 2020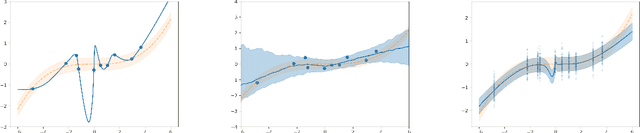
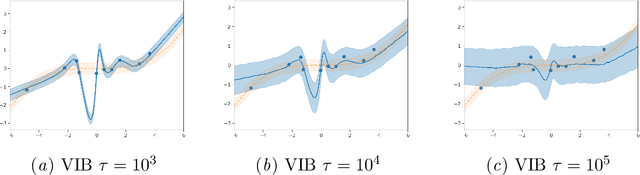

In discriminative settings such as regression and classification there are two random variables at play, the inputs X and the targets Y. Here, we demonstrate that the Variational Information Bottleneck can be viewed as a compromise between fully empirical and fully Bayesian objectives, attempting to minimize the risks due to finite sampling of Y only. We argue that this approach provides some of the benefits of Bayes while requiring only some of the work.