 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA2Perf: Real-World Autonomous Agents Benchmark
Mar 04, 2025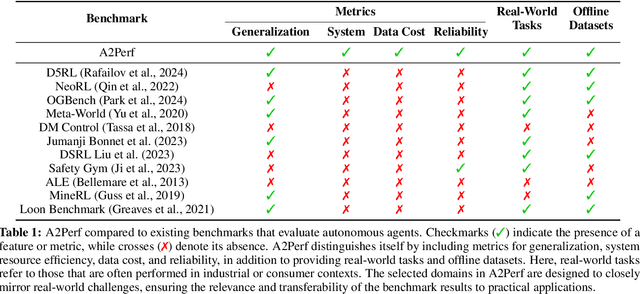

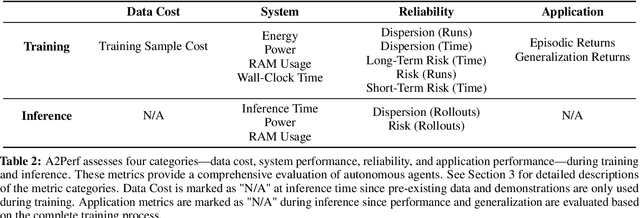

Autonomous agents and systems cover a number of application areas, from robotics and digital assistants to combinatorial optimization, all sharing common, unresolved research challenges. It is not sufficient for agents to merely solve a given task; they must generalize to out-of-distribution tasks, perform reliably, and use hardware resources efficiently during training and inference, among other requirements. Several methods, such as reinforcement learning and imitation learning, are commonly used to tackle these problems, each with different trade-offs. However, there is a lack of benchmarking suites that define the environments, datasets, and metrics which can be used to provide a meaningful way for the community to compare progress on applying these methods to real-world problems. We introduce A2Perf--a benchmark with three environments that closely resemble real-world domains: computer chip floorplanning, web navigation, and quadruped locomotion. A2Perf provides metrics that track task performance, generalization, system resource efficiency, and reliability, which are all critical to real-world applications. Using A2Perf, we demonstrate that web navigation agents can achieve latencies comparable to human reaction times on consumer hardware, reveal reliability trade-offs between algorithms for quadruped locomotion, and quantify the energy costs of different learning approaches for computer chip-design. In addition, we propose a data cost metric to account for the cost incurred acquiring offline data for imitation learning and hybrid algorithms, which allows us to better compare these approaches. A2Perf also contains several standard baselines, enabling apples-to-apples comparisons across methods and facilitating progress in real-world autonomy. As an open-source benchmark, A2Perf is designed to remain accessible, up-to-date, and useful to the research community over the long term.
PI-ARS: Accelerating Evolution-Learned Visual-Locomotion with Predictive Information Representations
Jul 27, 2022



Evolution Strategy (ES) algorithms have shown promising results in training complex robotic control policies due to their massive parallelism capability, simple implementation, effective parameter-space exploration, and fast training time. However, a key limitation of ES is its scalability to large capacity models, including modern neural network architectures. In this work, we develop Predictive Information Augmented Random Search (PI-ARS) to mitigate this limitation by leveraging recent advancements in representation learning to reduce the parameter search space for ES. Namely, PI-ARS combines a gradient-based representation learning technique, Predictive Information (PI), with a gradient-free ES algorithm, Augmented Random Search (ARS), to train policies that can process complex robot sensory inputs and handle highly nonlinear robot dynamics. We evaluate PI-ARS on a set of challenging visual-locomotion tasks where a quadruped robot needs to walk on uneven stepping stones, quincuncial piles, and moving platforms, as well as to complete an indoor navigation task. Across all tasks, PI-ARS demonstrates significantly better learning efficiency and performance compared to the ARS baseline. We further validate our algorithm by demonstrating that the learned policies can successfully transfer to a real quadruped robot, for example, achieving a 100% success rate on the real-world stepping stone environment, dramatically improving prior results achieving 40% success.
Multi-Game Decision Transformers
May 30, 2022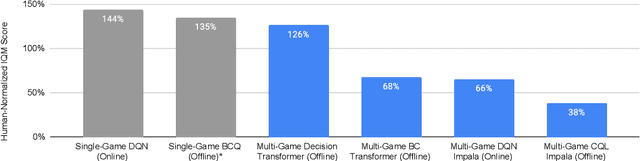

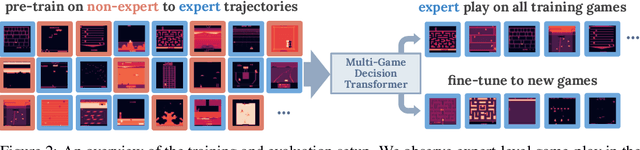
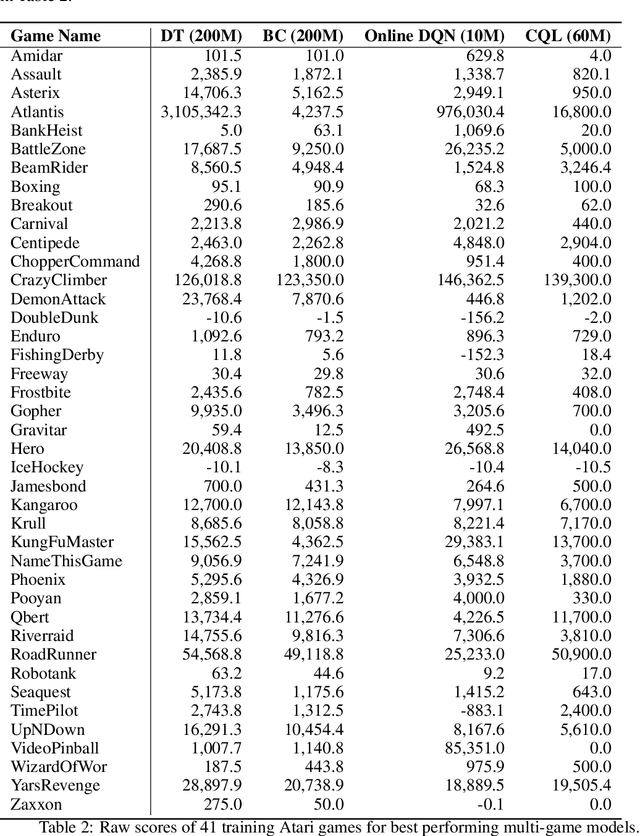
A longstanding goal of the field of AI is a strategy for compiling diverse experience into a highly capable, generalist agent. In the subfields of vision and language, this was largely achieved by scaling up transformer-based models and training them on large, diverse datasets. Motivated by this progress, we investigate whether the same strategy can be used to produce generalist reinforcement learning agents. Specifically, we show that a single transformer-based model - with a single set of weights - trained purely offline can play a suite of up to 46 Atari games simultaneously at close-to-human performance. When trained and evaluated appropriately, we find that the same trends observed in language and vision hold, including scaling of performance with model size and rapid adaptation to new games via fine-tuning. We compare several approaches in this multi-game setting, such as online and offline RL methods and behavioral cloning, and find that our Multi-Game Decision Transformer models offer the best scalability and performance. We release the pre-trained models and code to encourage further research in this direction. Additional information, videos and code can be seen at: sites.google.com/view/multi-game-transformers
Compressive Visual Representations
Sep 29, 2021


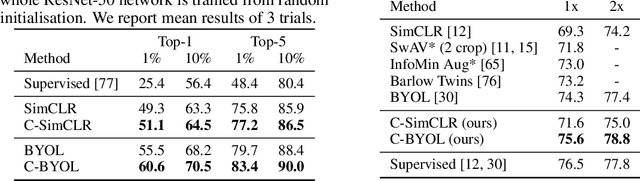
Learning effective visual representations that generalize well without human supervision is a fundamental problem in order to apply Machine Learning to a wide variety of tasks. Recently, two families of self-supervised methods, contrastive learning and latent bootstrapping, exemplified by SimCLR and BYOL respectively, have made significant progress. In this work, we hypothesize that adding explicit information compression to these algorithms yields better and more robust representations. We verify this by developing SimCLR and BYOL formulations compatible with the Conditional Entropy Bottleneck (CEB) objective, allowing us to both measure and control the amount of compression in the learned representation, and observe their impact on downstream tasks. Furthermore, we explore the relationship between Lipschitz continuity and compression, showing a tractable lower bound on the Lipschitz constant of the encoders we learn. As Lipschitz continuity is closely related to robustness, this provides a new explanation for why compressed models are more robust. Our experiments confirm that adding compression to SimCLR and BYOL significantly improves linear evaluation accuracies and model robustness across a wide range of domain shifts. In particular, the compressed version of BYOL achieves 76.0% Top-1 linear evaluation accuracy on ImageNet with ResNet-50, and 78.8% with ResNet-50 2x.
Predictive Information Accelerates Learning in RL
Jul 24, 2020



The Predictive Information is the mutual information between the past and the future, I(X_past; X_future). We hypothesize that capturing the predictive information is useful in RL, since the ability to model what will happen next is necessary for success on many tasks. To test our hypothesis, we train Soft Actor-Critic (SAC) agents from pixels with an auxiliary task that learns a compressed representation of the predictive information of the RL environment dynamics using a contrastive version of the Conditional Entropy Bottleneck (CEB) objective. We refer to these as Predictive Information SAC (PI-SAC) agents. We show that PI-SAC agents can substantially improve sample efficiency over challenging baselines on tasks from the DM Control suite of continuous control environments. We evaluate PI-SAC agents by comparing against uncompressed PI-SAC agents, other compressed and uncompressed agents, and SAC agents directly trained from pixels.
Measuring the Reliability of Reinforcement Learning Algorithms
Dec 10, 2019

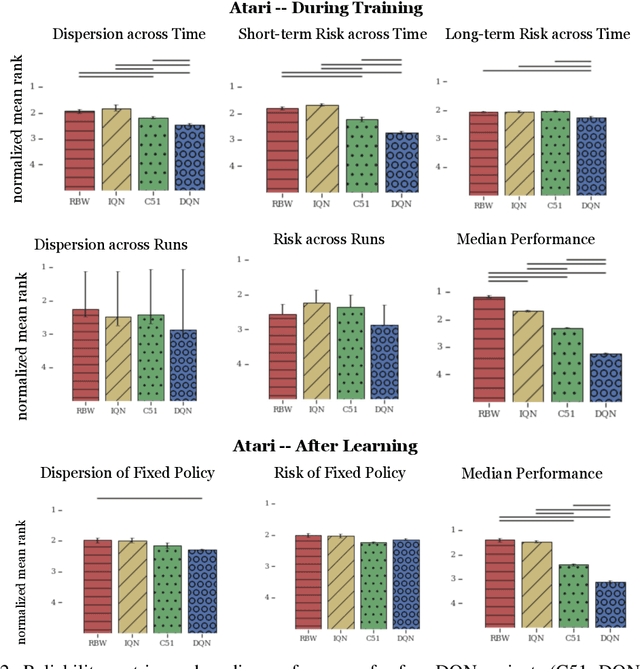

Lack of reliability is a well-known issue for reinforcement learning (RL) algorithms. This problem has gained increasing attention in recent years, and efforts to improve it have grown substantially. To aid RL researchers and production users with the evaluation and improvement of reliability, we propose a set of metrics that quantitatively measure different aspects of reliability. In this work, we focus on variability and risk, both during training and after learning (on a fixed policy). We designed these metrics to be general-purpose, and we also designed complementary statistical tests to enable rigorous comparisons on these metrics. In this paper, we first describe the desired properties of the metrics and their design, the aspects of reliability that they measure, and their applicability to different scenarios. We then describe the statistical tests and make additional practical recommendations for reporting results. The metrics and accompanying statistical tools have been made available as an open-source library, here: https://github.com/google-research/rl-reliability-metrics . We apply our metrics to a set of common RL algorithms and environments, compare them, and analyze the results.
From Language to Goals: Inverse Reinforcement Learning for Vision-Based Instruction Following
Feb 20, 2019



Reinforcement learning is a promising framework for solving control problems, but its use in practical situations is hampered by the fact that reward functions are often difficult to engineer. Specifying goals and tasks for autonomous machines, such as robots, is a significant challenge: conventionally, reward functions and goal states have been used to communicate objectives. But people can communicate objectives to each other simply by describing or demonstrating them. How can we build learning algorithms that will allow us to tell machines what we want them to do? In this work, we investigate the problem of grounding language commands as reward functions using inverse reinforcement learning, and argue that language-conditioned rewards are more transferable than language-conditioned policies to new environments. We propose language-conditioned reward learning (LC-RL), which grounds language commands as a reward function represented by a deep neural network. We demonstrate that our model learns rewards that transfer to novel tasks and environments on realistic, high-dimensional visual environments with natural language commands, whereas directly learning a language-conditioned policy leads to poor performance.
Tracking Emerges by Colorizing Videos
Jul 27, 2018
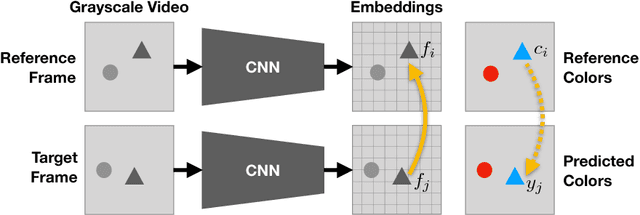


We use large amounts of unlabeled video to learn models for visual tracking without manual human supervision. We leverage the natural temporal coherency of color to create a model that learns to colorize gray-scale videos by copying colors from a reference frame. Quantitative and qualitative experiments suggest that this task causes the model to automatically learn to track visual regions. Although the model is trained without any ground-truth labels, our method learns to track well enough to outperform the latest methods based on optical flow. Moreover, our results suggest that failures to track are correlated with failures to colorize, indicating that advancing video colorization may further improve self-supervised visual tracking.
Improved Image Captioning via Policy Gradient optimization of SPIDEr
Mar 12, 2018
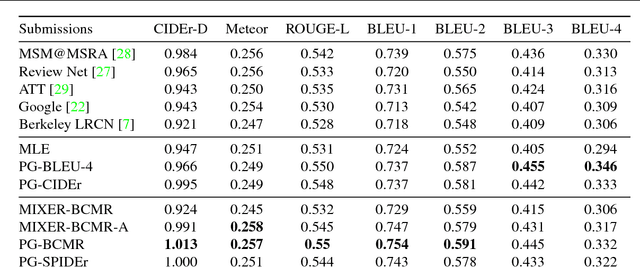
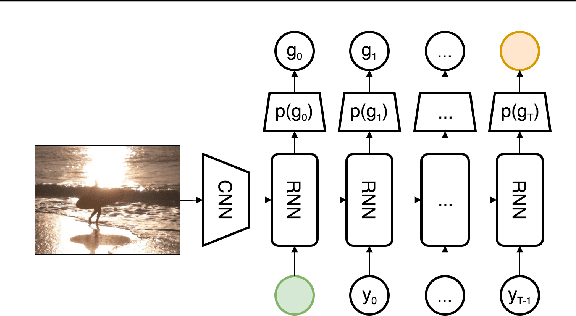

Current image captioning methods are usually trained via (penalized) maximum likelihood estimation. However, the log-likelihood score of a caption does not correlate well with human assessments of quality. Standard syntactic evaluation metrics, such as BLEU, METEOR and ROUGE, are also not well correlated. The newer SPICE and CIDEr metrics are better correlated, but have traditionally been hard to optimize for. In this paper, we show how to use a policy gradient (PG) method to directly optimize a linear combination of SPICE and CIDEr (a combination we call SPIDEr): the SPICE score ensures our captions are semantically faithful to the image, while CIDEr score ensures our captions are syntactically fluent. The PG method we propose improves on the prior MIXER approach, by using Monte Carlo rollouts instead of mixing MLE training with PG. We show empirically that our algorithm leads to easier optimization and improved results compared to MIXER. Finally, we show that using our PG method we can optimize any of the metrics, including the proposed SPIDEr metric which results in image captions that are strongly preferred by human raters compared to captions generated by the same model but trained to optimize MLE or the COCO metrics.
The Devil is in the Decoder
Aug 12, 2017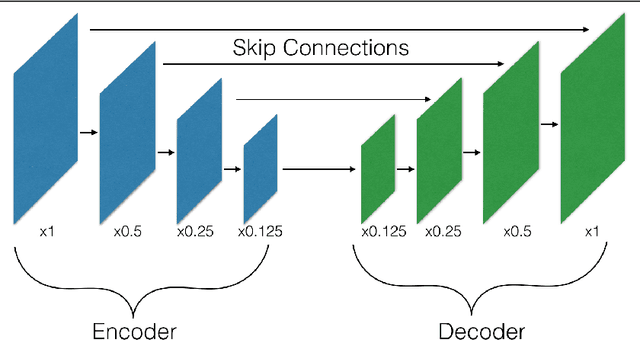

Many machine vision applications require predictions for every pixel of the input image (for example semantic segmentation, boundary detection). Models for such problems usually consist of encoders which decreases spatial resolution while learning a high-dimensional representation, followed by decoders who recover the original input resolution and result in low-dimensional predictions. While encoders have been studied rigorously, relatively few studies address the decoder side. Therefore this paper presents an extensive comparison of a variety of decoders for a variety of pixel-wise prediction tasks. Our contributions are: (1) Decoders matter: we observe significant variance in results between different types of decoders on various problems. (2) We introduce a novel decoder: bilinear additive upsampling. (3) We introduce new residual-like connections for decoders. (4) We identify two decoder types which give a consistently high performance.