 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning for Rheumatoid Arthritis: Joint Detection and Damage Scoring in X-rays
Apr 28, 2021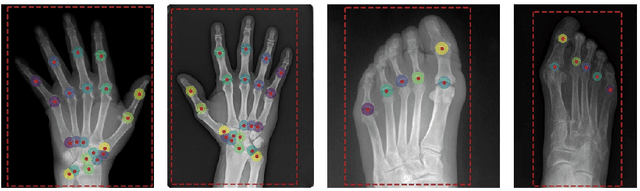
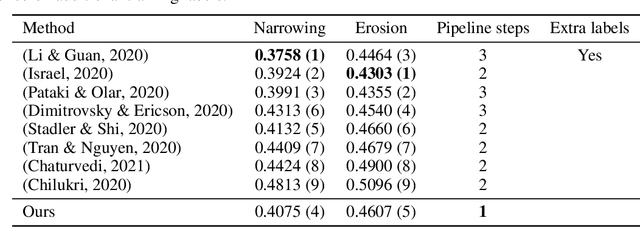
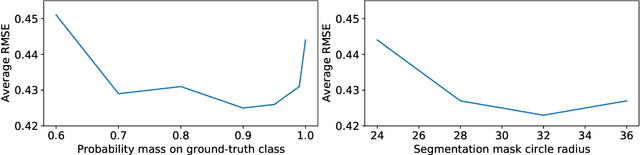
Recent advancements in computer vision promise to automate medical image analysis. Rheumatoid arthritis is an autoimmune disease that would profit from computer-based diagnosis, as there are no direct markers known, and doctors have to rely on manual inspection of X-ray images. In this work, we present a multi-task deep learning model that simultaneously learns to localize joints on X-ray images and diagnose two kinds of joint damage: narrowing and erosion. Additionally, we propose a modification of label smoothing, which combines classification and regression cues into a single loss and achieves 5% relative error reduction compared to standard loss functions. Our final model obtained 4th place in joint space narrowing and 5th place in joint erosion in the global RA2 DREAM challenge.
Training DNNs in O memory with MEM-DFA using Random Matrices
Dec 21, 2020
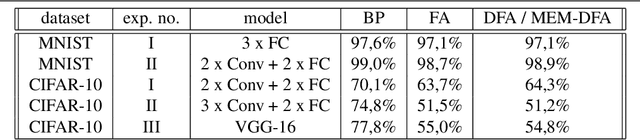

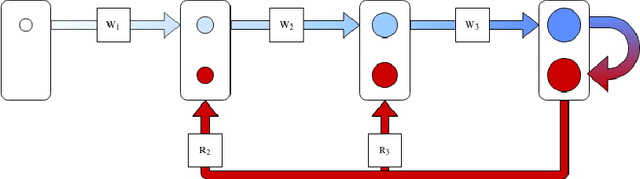
This work presents a method for reducing memory consumption to a constant complexity when training deep neural networks. The algorithm is based on the more biologically plausible alternatives of the backpropagation (BP): direct feedback alignment (DFA) and feedback alignment (FA), which use random matrices to propagate error. The proposed method, memory-efficient direct feedback alignment (MEM-DFA), uses higher independence of layers in DFA and allows avoiding storing at once all activation vectors, unlike standard BP, FA, and DFA. Thus, our algorithm's memory usage is constant regardless of the number of layers in a neural network. The method increases the computational cost only by a constant factor of one extra forward pass. The MEM-DFA, BP, FA, and DFA were evaluated along with their memory profiles on MNIST and CIFAR-10 datasets on various neural network models. Our experiments agree with our theoretical results and show a significant decrease in the memory cost of MEM-DFA compared to the other algorithms.
Augmentation Inside the Network
Dec 19, 2020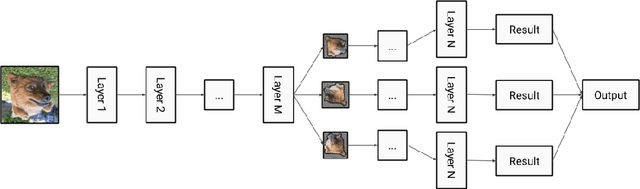
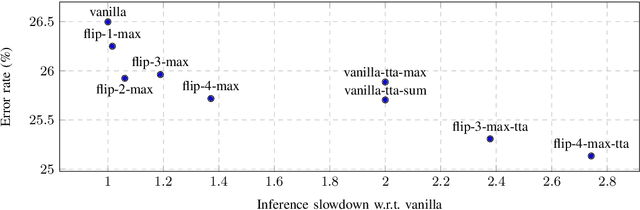
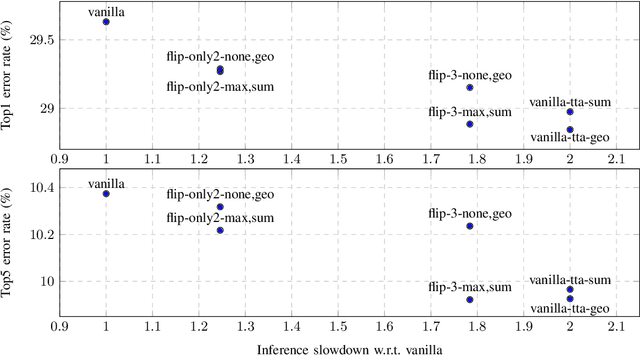
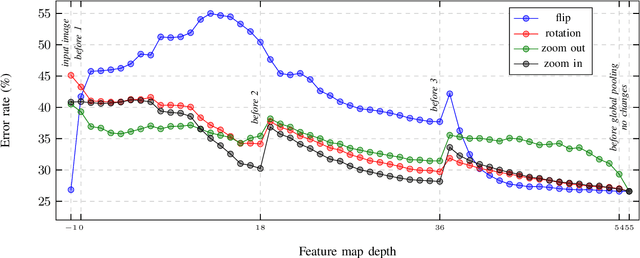
In this paper, we present augmentation inside the network, a method that simulates data augmentation techniques for computer vision problems on intermediate features of a convolutional neural network. We perform these transformations, changing the data flow through the network, and sharing common computations when it is possible. Our method allows us to obtain smoother speed-accuracy trade-off adjustment and achieves better results than using standard test-time augmentation (TTA) techniques. Additionally, our approach can improve model performance even further when coupled with test-time augmentation. We validate our method on the ImageNet-2012 and CIFAR-100 datasets for image classification. We propose a modification that is 30% faster than the flip test-time augmentation and achieves the same results for CIFAR-100.
Holistic Multi-View Building Analysis in the Wild with Projection Pooling
Sep 25, 2020
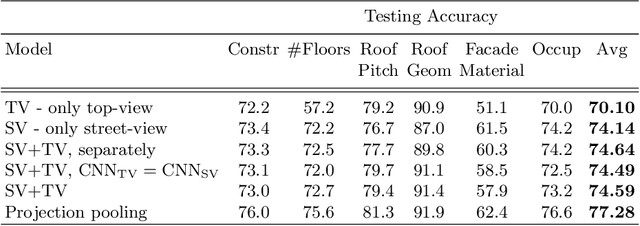
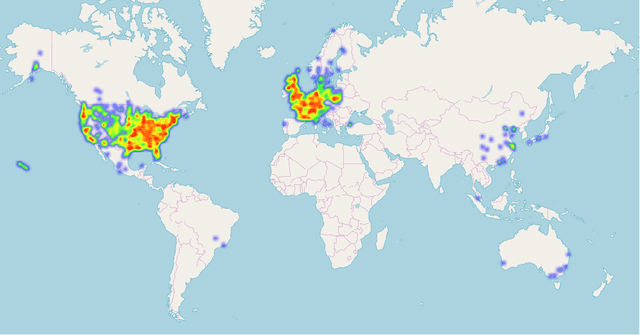
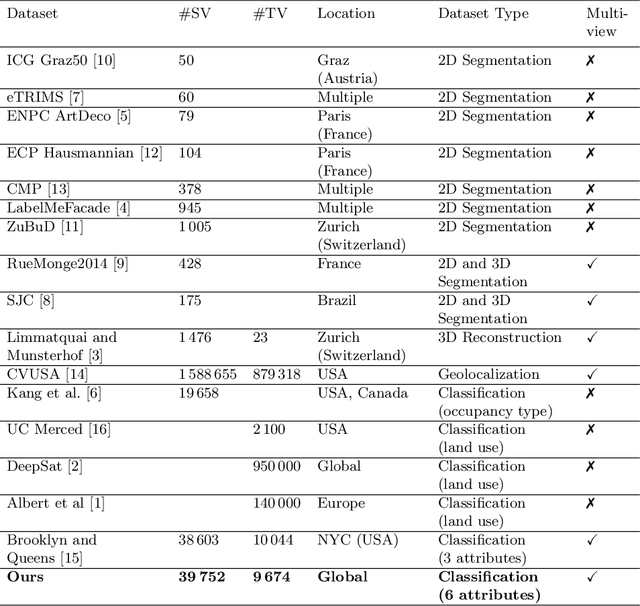
We address six different classification tasks related to fine-grained building attributes: construction type, number of floors, pitch and geometry of the roof, facade material, and occupancy class. Tackling such a problem of remote building analysis became possible only recently due to growing large scale datasets of urban scenes. To this end, we introduce a new benchmarking dataset, consisting of 49426 top-view and street-view images of 9674 buildings. These photos are further assembled, together with the geometric metadata. The dataset showcases a variety of real-world challenges, such as occlusions, blur, partially visible objects, and a broad spectrum of buildings. We propose a new projection pooling layer, creating a unified, top-view representation of the top-view and the side views in a high-dimensional space. It allows us to utilize the building and imagery metadata seamlessly. Introducing this layer improves classification accuracy - compared to highly tuned baseline models - indicating its suitability for building analysis.
Large-scale mammography CAD with Deformable Conv-Nets
Feb 19, 2019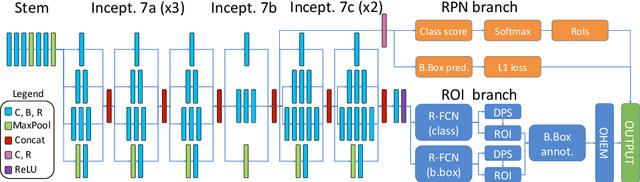

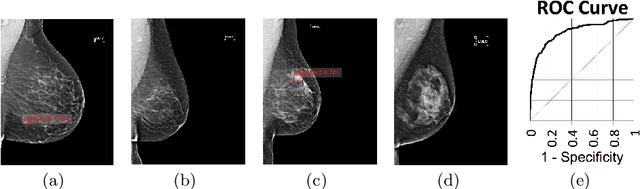
State-of-the-art deep learning methods for image processing are evolving into increasingly complex meta-architectures with a growing number of modules. Among them, region-based fully convolutional networks (R-FCN) and deformable convolutional nets (DCN) can improve CAD for mammography: R-FCN optimizes for speed and low consumption of memory, which is crucial for processing the high resolutions of to 50 micrometers used by radiologists. Deformable convolution and pooling can model a wide range of mammographic findings of different morphology and scales, thanks to their versatility. In this study, we present a neural net architecture based on R-FCN / DCN, that we have adapted from the natural image domain to suit mammograms -- particularly their larger image size -- without compromising resolution. We trained the network on a large, recently released dataset (Optimam) including 6,500 cancerous mammograms. By combining our modern architecture with such a rich dataset, we achieved an area under the ROC curve of 0.879 for breast-wise detection in the DREAMS challenge (130,000 withheld images), which surpassed all other submissions in the competitive phase.
Augmentation for small object detection
Feb 19, 2019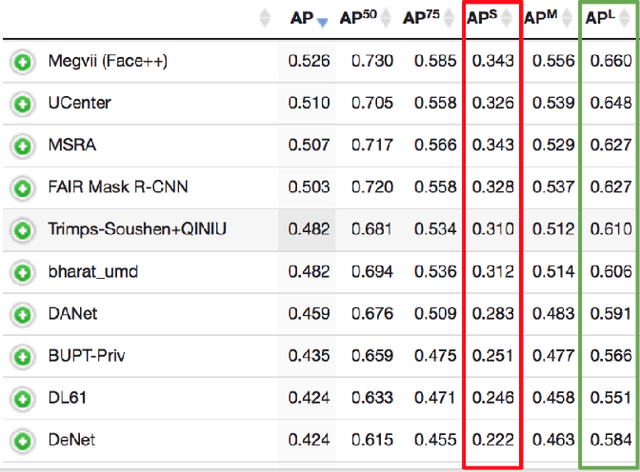
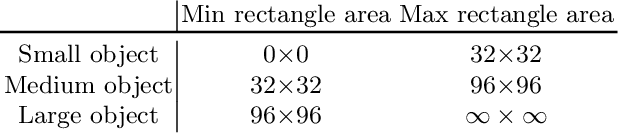

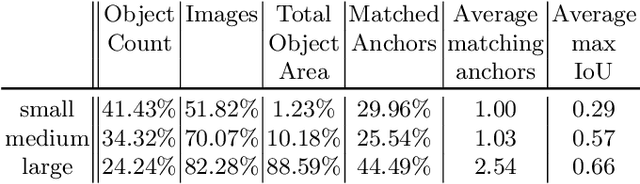
In recent years, object detection has experienced impressive progress. Despite these improvements, there is still a significant gap in the performance between the detection of small and large objects. We analyze the current state-of-the-art model, Mask-RCNN, on a challenging dataset, MS COCO. We show that the overlap between small ground-truth objects and the predicted anchors is much lower than the expected IoU threshold. We conjecture this is due to two factors; (1) only a few images are containing small objects, and (2) small objects do not appear enough even within each image containing them. We thus propose to oversample those images with small objects and augment each of those images by copy-pasting small objects many times. It allows us to trade off the quality of the detector on large objects with that on small objects. We evaluate different pasting augmentation strategies, and ultimately, we achieve 9.7\% relative improvement on the instance segmentation and 7.1\% on the object detection of small objects, compared to the current state of the art method on MS COCO.
Attention-based Extraction of Structured Information from Street View Imagery
Aug 20, 2017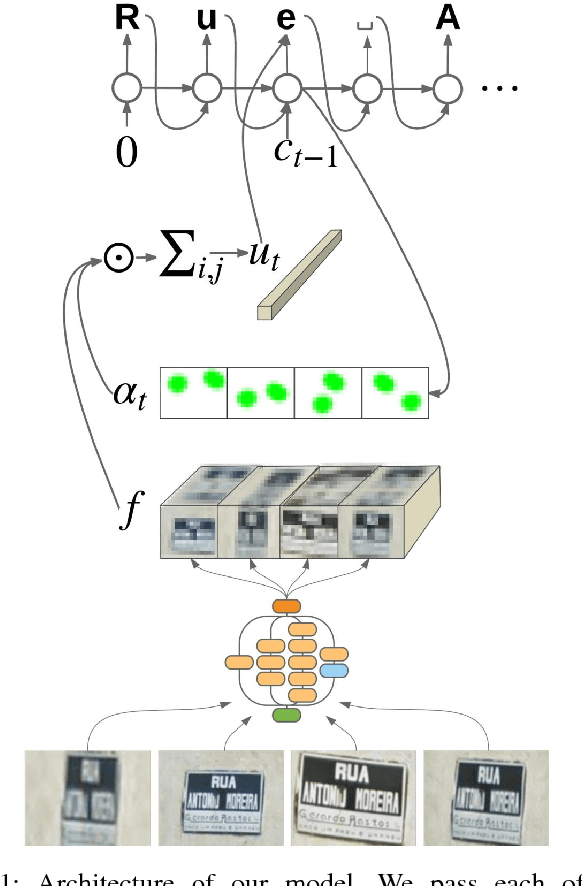
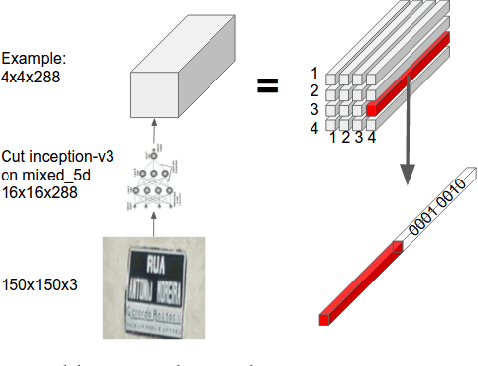


We present a neural network model - based on CNNs, RNNs and a novel attention mechanism - which achieves 84.2% accuracy on the challenging French Street Name Signs (FSNS) dataset, significantly outperforming the previous state of the art (Smith'16), which achieved 72.46%. Furthermore, our new method is much simpler and more general than the previous approach. To demonstrate the generality of our model, we show that it also performs well on an even more challenging dataset derived from Google Street View, in which the goal is to extract business names from store fronts. Finally, we study the speed/accuracy tradeoff that results from using CNN feature extractors of different depths. Surprisingly, we find that deeper is not always better (in terms of accuracy, as well as speed). Our resulting model is simple, accurate and fast, allowing it to be used at scale on a variety of challenging real-world text extraction problems.
The Devil is in the Decoder
Aug 12, 2017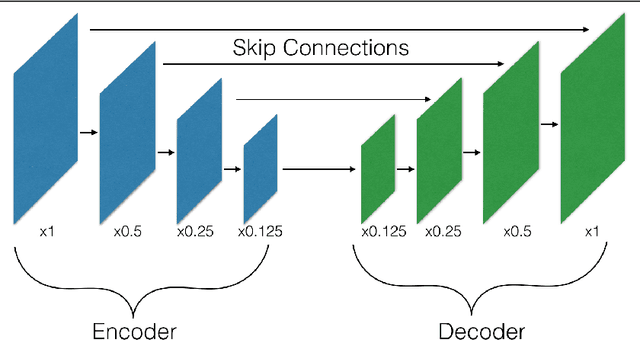

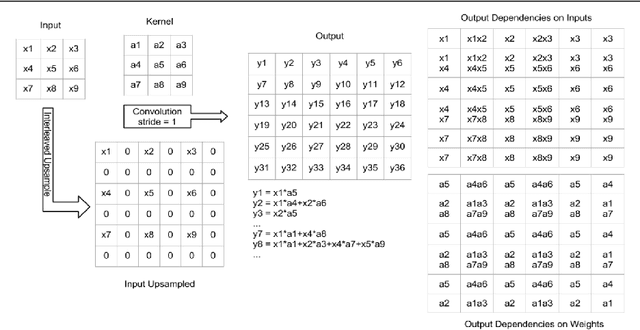
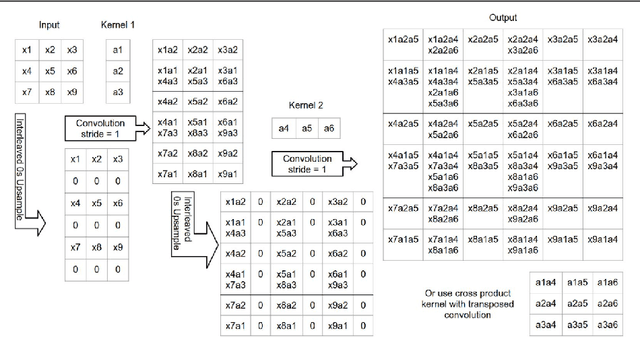
Many machine vision applications require predictions for every pixel of the input image (for example semantic segmentation, boundary detection). Models for such problems usually consist of encoders which decreases spatial resolution while learning a high-dimensional representation, followed by decoders who recover the original input resolution and result in low-dimensional predictions. While encoders have been studied rigorously, relatively few studies address the decoder side. Therefore this paper presents an extensive comparison of a variety of decoders for a variety of pixel-wise prediction tasks. Our contributions are: (1) Decoders matter: we observe significant variance in results between different types of decoders on various problems. (2) We introduce a novel decoder: bilinear additive upsampling. (3) We introduce new residual-like connections for decoders. (4) We identify two decoder types which give a consistently high performance.
Speed/accuracy trade-offs for modern convolutional object detectors
Apr 25, 2017
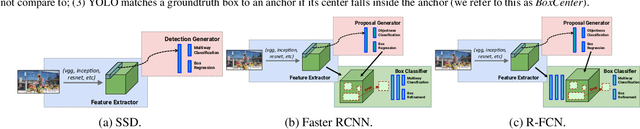

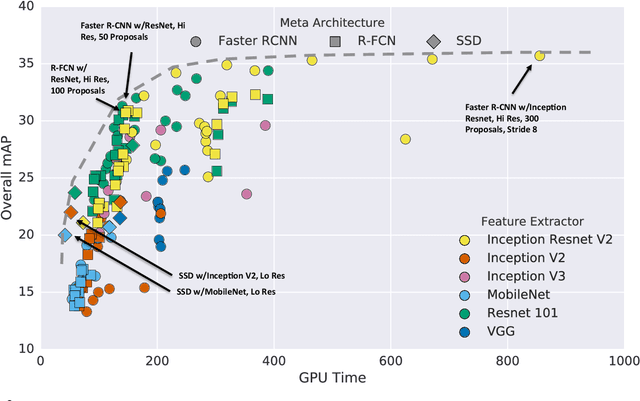
The goal of this paper is to serve as a guide for selecting a detection architecture that achieves the right speed/memory/accuracy balance for a given application and platform. To this end, we investigate various ways to trade accuracy for speed and memory usage in modern convolutional object detection systems. A number of successful systems have been proposed in recent years, but apples-to-apples comparisons are difficult due to different base feature extractors (e.g., VGG, Residual Networks), different default image resolutions, as well as different hardware and software platforms. We present a unified implementation of the Faster R-CNN [Ren et al., 2015], R-FCN [Dai et al., 2016] and SSD [Liu et al., 2015] systems, which we view as "meta-architectures" and trace out the speed/accuracy trade-off curve created by using alternative feature extractors and varying other critical parameters such as image size within each of these meta-architectures. On one extreme end of this spectrum where speed and memory are critical, we present a detector that achieves real time speeds and can be deployed on a mobile device. On the opposite end in which accuracy is critical, we present a detector that achieves state-of-the-art performance measured on the COCO detection task.
Semantic Instance Segmentation via Deep Metric Learning
Mar 30, 2017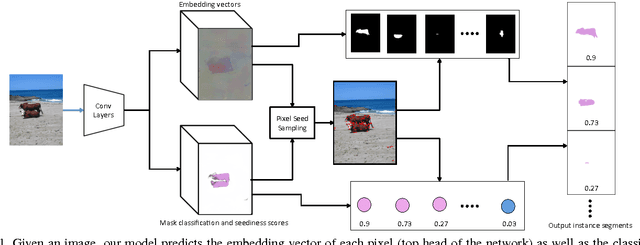
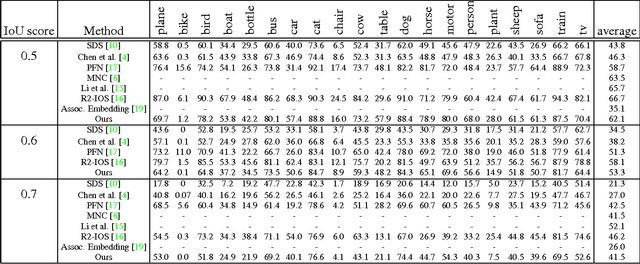
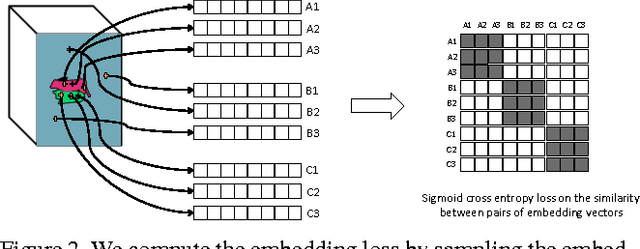

We propose a new method for semantic instance segmentation, by first computing how likely two pixels are to belong to the same object, and then by grouping similar pixels together. Our similarity metric is based on a deep, fully convolutional embedding model. Our grouping method is based on selecting all points that are sufficiently similar to a set of "seed points", chosen from a deep, fully convolutional scoring model. We show competitive results on the Pascal VOC instance segmentation benchmark.