 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention-based Extraction of Structured Information from Street View Imagery
Aug 20, 2017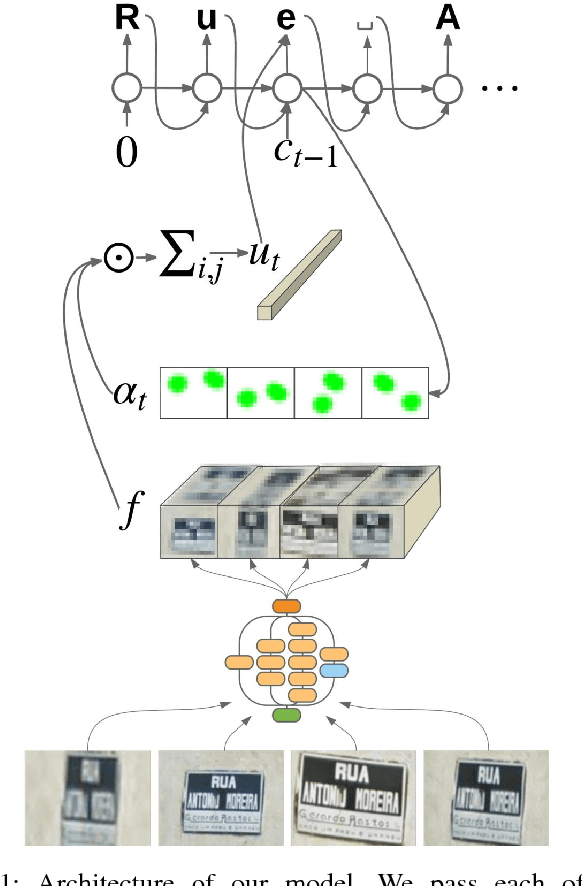
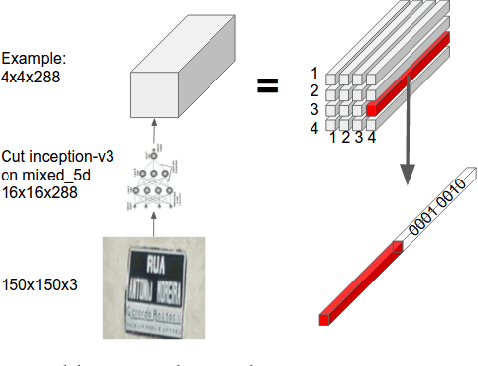


We present a neural network model - based on CNNs, RNNs and a novel attention mechanism - which achieves 84.2% accuracy on the challenging French Street Name Signs (FSNS) dataset, significantly outperforming the previous state of the art (Smith'16), which achieved 72.46%. Furthermore, our new method is much simpler and more general than the previous approach. To demonstrate the generality of our model, we show that it also performs well on an even more challenging dataset derived from Google Street View, in which the goal is to extract business names from store fronts. Finally, we study the speed/accuracy tradeoff that results from using CNN feature extractors of different depths. Surprisingly, we find that deeper is not always better (in terms of accuracy, as well as speed). Our resulting model is simple, accurate and fast, allowing it to be used at scale on a variety of challenging real-world text extraction problems.
The THUMOS Challenge on Action Recognition for Videos "in the Wild"
Apr 21, 2016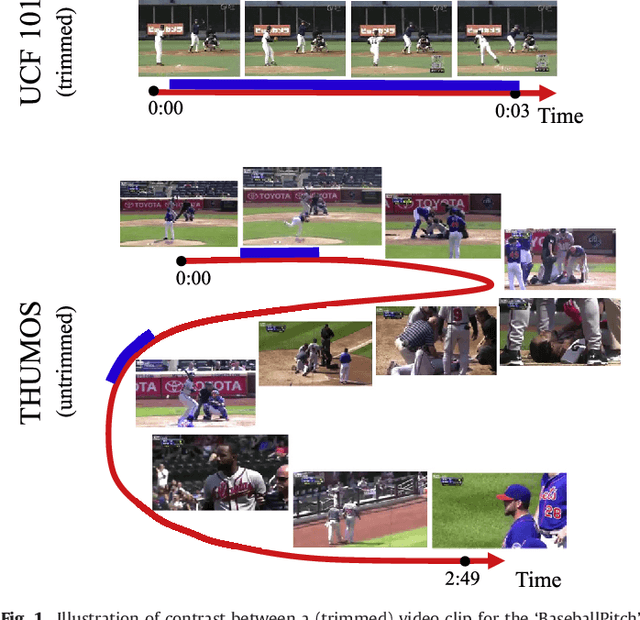
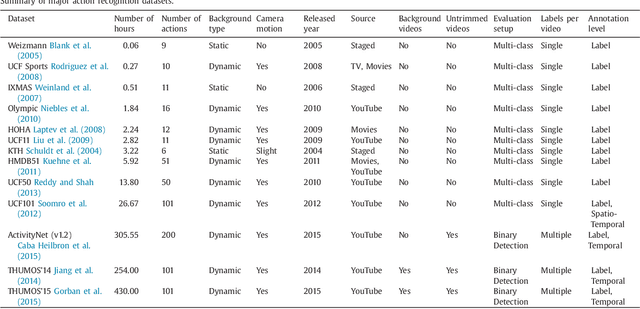
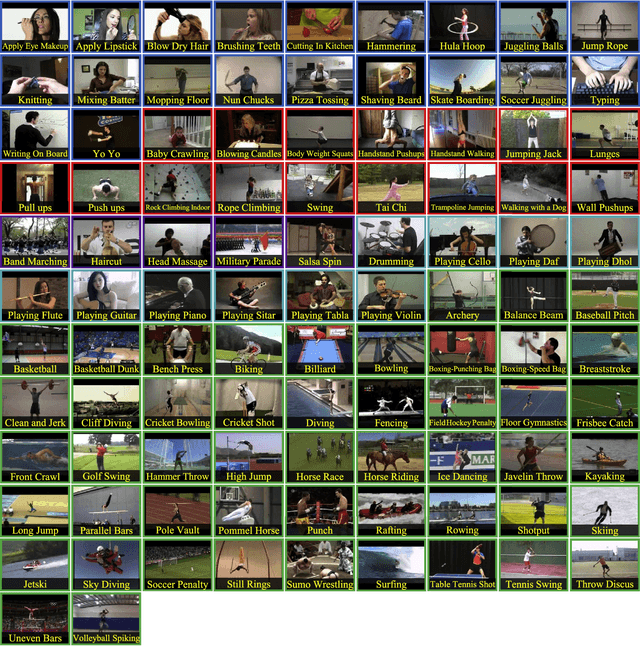
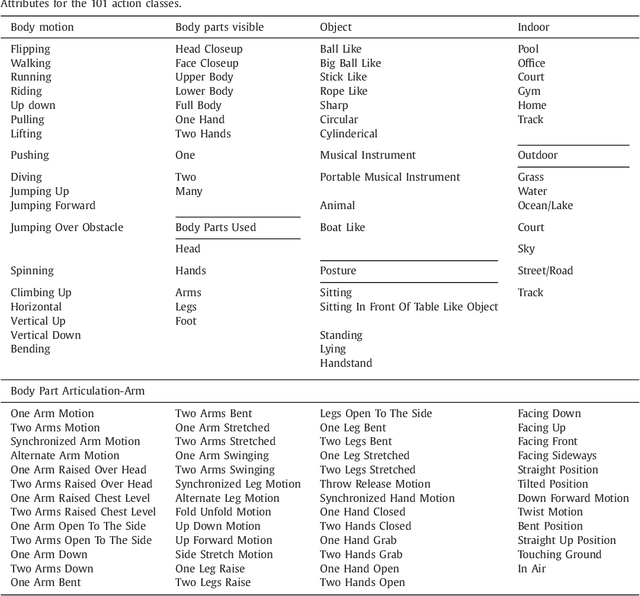
Automatically recognizing and localizing wide ranges of human actions has crucial importance for video understanding. Towards this goal, the THUMOS challenge was introduced in 2013 to serve as a benchmark for action recognition. Until then, video action recognition, including THUMOS challenge, had focused primarily on the classification of pre-segmented (i.e., trimmed) videos, which is an artificial task. In THUMOS 2014, we elevated action recognition to a more practical level by introducing temporally untrimmed videos. These also include `background videos' which share similar scenes and backgrounds as action videos, but are devoid of the specific actions. The three editions of the challenge organized in 2013--2015 have made THUMOS a common benchmark for action classification and detection and the annual challenge is widely attended by teams from around the world. In this paper we describe the THUMOS benchmark in detail and give an overview of data collection and annotation procedures. We present the evaluation protocols used to quantify results in the two THUMOS tasks of action classification and temporal detection. We also present results of submissions to the THUMOS 2015 challenge and review the participating approaches. Additionally, we include a comprehensive empirical study evaluating the differences in action recognition between trimmed and untrimmed videos, and how well methods trained on trimmed videos generalize to untrimmed videos. We conclude by proposing several directions and improvements for future THUMOS challenges.