 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle-Network Whole-Body Pose Estimation
Sep 30, 2019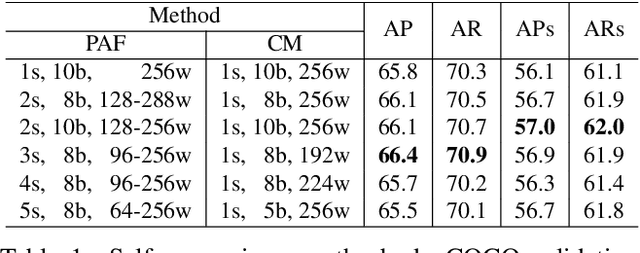


We present the first single-network approach for 2D~whole-body pose estimation, which entails simultaneous localization of body, face, hands, and feet keypoints. Due to the bottom-up formulation, our method maintains constant real-time performance regardless of the number of people in the image. The network is trained in a single stage using multi-task learning, through an improved architecture which can handle scale differences between body/foot and face/hand keypoints. Our approach considerably improves upon OpenPose~\cite{cao2018openpose}, the only work so far capable of whole-body pose estimation, both in terms of speed and global accuracy. Unlike OpenPose, our method does not need to run an additional network for each hand and face candidate, making it substantially faster for multi-person scenarios. This work directly results in a reduction of computational complexity for applications that require 2D whole-body information (e.g., VR/AR, re-targeting). In addition, it yields higher accuracy, especially for occluded, blurry, and low resolution faces and hands. For code, trained models, and validation benchmarks, visit our project page: https://github.com/CMU-Perceptual-Computing-Lab/openpose_train.
Efficient Online Multi-Person 2D Pose Tracking with Recurrent Spatio-Temporal Affinity Fields
Nov 29, 2018

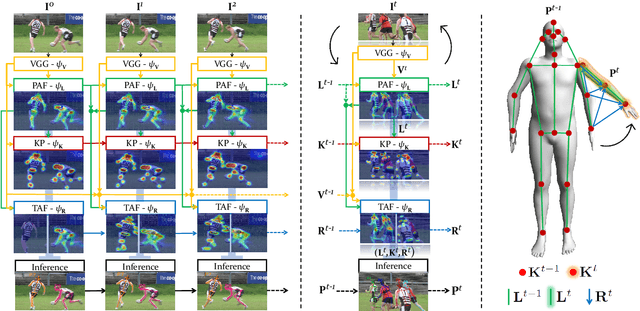
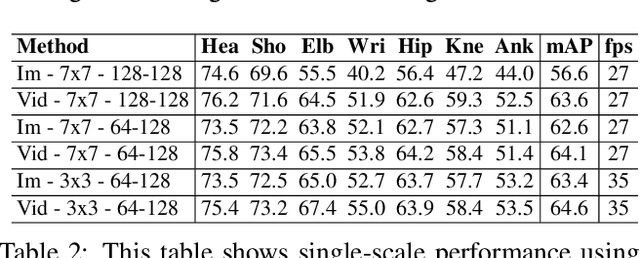
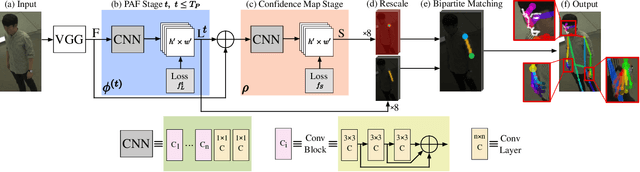
We present an online approach to efficiently and simultaneously detect and track the 2D pose of multiple people in a video sequence. We build upon Part Affinity Field (PAF) representation designed for static images, and propose an architecture that can encode and predict Spatio-Temporal Affinity Fields (STAF) across a video sequence. In particular, we propose a novel temporal topology cross-linked across limbs which can consistently handle body motions of a wide range of magnitudes. Additionally, we make the overall approach recurrent in nature, where the network ingests STAF heatmaps from previous frames and estimates those for the current frame. Our approach uses only online inference and tracking, and is currently the fastest and the most accurate bottom-up approach that is runtime invariant to the number of people in the scene and accuracy invariant to input frame rate of camera. Running at $\sim$30 fps on a single GPU at single scale, it achieves highly competitive results on the PoseTrack benchmarks.
Composition Loss for Counting, Density Map Estimation and Localization in Dense Crowds
Aug 02, 2018
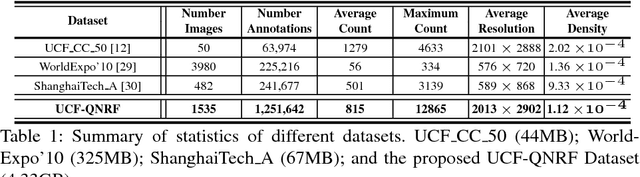
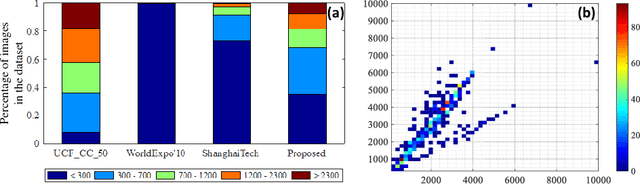
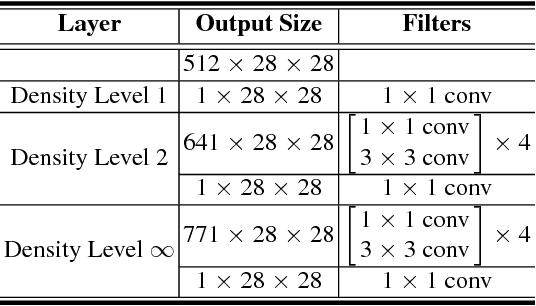
With multiple crowd gatherings of millions of people every year in events ranging from pilgrimages to protests, concerts to marathons, and festivals to funerals; visual crowd analysis is emerging as a new frontier in computer vision. In particular, counting in highly dense crowds is a challenging problem with far-reaching applicability in crowd safety and management, as well as gauging political significance of protests and demonstrations. In this paper, we propose a novel approach that simultaneously solves the problems of counting, density map estimation and localization of people in a given dense crowd image. Our formulation is based on an important observation that the three problems are inherently related to each other making the loss function for optimizing a deep CNN decomposable. Since localization requires high-quality images and annotations, we introduce UCF-QNRF dataset that overcomes the shortcomings of previous datasets, and contains 1.25 million humans manually marked with dot annotations. Finally, we present evaluation measures and comparison with recent deep CNN networks, including those developed specifically for crowd counting. Our approach significantly outperforms state-of-the-art on the new dataset, which is the most challenging dataset with the largest number of crowd annotations in the most diverse set of scenes.
Large-scale Image Geo-Localization Using Dominant Sets
Sep 14, 2017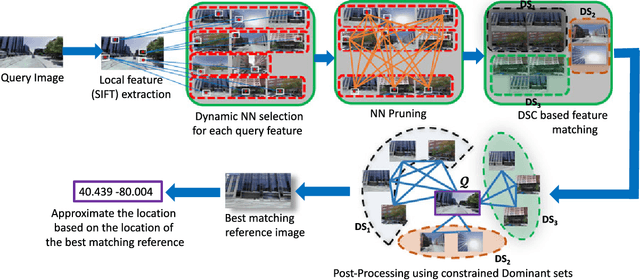

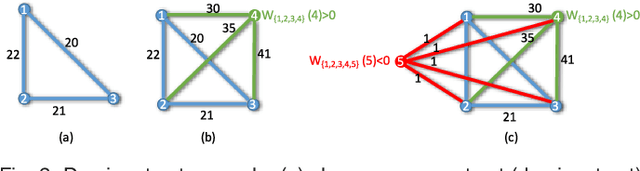
This paper presents a new approach for the challenging problem of geo-locating an image using image matching in a structured database of city-wide reference images with known GPS coordinates. We cast the geo-localization as a clustering problem on local image features. Akin to existing approaches on the problem, our framework builds on low-level features which allow partial matching between images. For each local feature in the query image, we find its approximate nearest neighbors in the reference set. Next, we cluster the features from reference images using Dominant Set clustering, which affords several advantages over existing approaches. First, it permits variable number of nodes in the cluster which we use to dynamically select the number of nearest neighbors (typically coming from multiple reference images) for each query feature based on its discrimination value. Second, as we also quantify in our experiments, this approach is several orders of magnitude faster than existing approaches. Thus, we obtain multiple clusters (different local maximizers) and obtain a robust final solution to the problem using multiple weak solutions through constrained Dominant Set clustering on global image features, where we enforce the constraint that the query image must be included in the cluster. This second level of clustering also bypasses heuristic approaches to voting and selecting the reference image that matches to the query. We evaluated the proposed framework on an existing dataset of 102k street view images as well as a new dataset of 300k images, and show that it outperforms the state-of-the-art by 20% and 7%, respectively, on the two datasets.
Re-identification of Humans in Crowds using Personal, Social and Environmental Constraints
Dec 07, 2016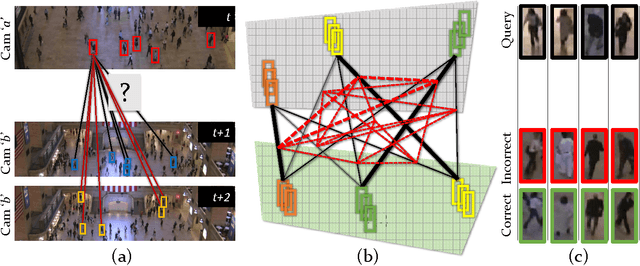
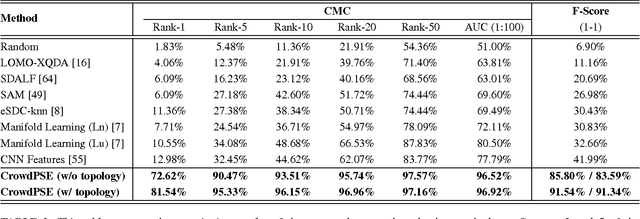
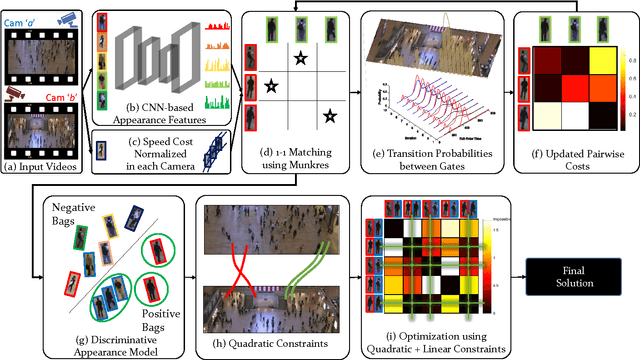

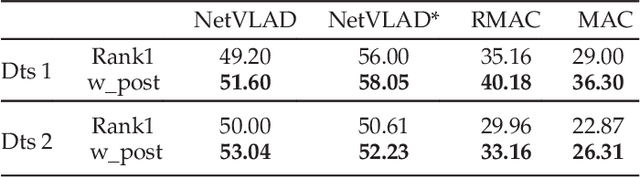
This paper addresses the problem of human re-identification across non-overlapping cameras in crowds.Re-identification in crowded scenes is a challenging problem due to large number of people and frequent occlusions, coupled with changes in their appearance due to different properties and exposure of cameras. To solve this problem, we model multiple Personal, Social and Environmental (PSE) constraints on human motion across cameras. The personal constraints include appearance and preferred speed of each individual assumed to be similar across the non-overlapping cameras. The social influences (constraints) are quadratic in nature, i.e. occur between pairs of individuals, and modeled through grouping and collision avoidance. Finally, the environmental constraints capture the transition probabilities between gates (entrances / exits) in different cameras, defined as multi-modal distributions of transition time and destination between all pairs of gates. We incorporate these constraints into an energy minimization framework for solving human re-identification. Assigning $1-1$ correspondence while modeling PSE constraints is NP-hard. We present a stochastic local search algorithm to restrict the search space of hypotheses, and obtain $1-1$ solution in the presence of linear and quadratic PSE constraints. Moreover, we present an alternate optimization using Frank-Wolfe algorithm that solves the convex approximation of the objective function with linear relaxation on binary variables, and yields an order of magnitude speed up over stochastic local search with minor drop in performance. We evaluate our approach using Cumulative Matching Curves as well $1-1$ assignment on several thousand frames of Grand Central, PRID and DukeMTMC datasets, and obtain significantly better results compared to existing re-identification methods.
Online Localization and Prediction of Actions and Interactions
Dec 04, 2016
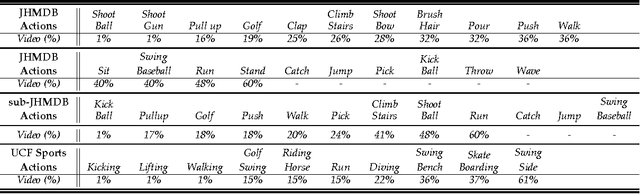
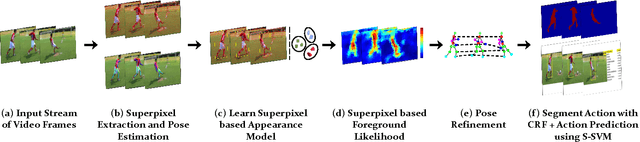
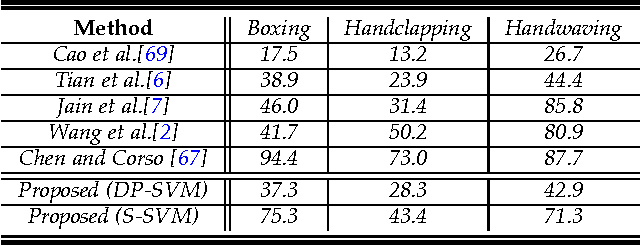
This paper proposes a person-centric and online approach to the challenging problem of localization and prediction of actions and interactions in videos. Typically, localization or recognition is performed in an offline manner where all the frames in the video are processed together. This prevents timely localization and prediction of actions and interactions - an important consideration for many tasks including surveillance and human-machine interaction. In our approach, we estimate human poses at each frame and train discriminative appearance models using the superpixels inside the pose bounding boxes. Since the pose estimation per frame is inherently noisy, the conditional probability of pose hypotheses at current time-step (frame) is computed using pose estimations in the current frame and their consistency with poses in the previous frames. Next, both the superpixel and pose-based foreground likelihoods are used to infer the location of actors at each time through a Conditional Random. The issue of visual drift is handled by updating the appearance models, and refining poses using motion smoothness on joint locations, in an online manner. For online prediction of action (interaction) confidences, we propose an approach based on Structural SVM that operates on short video segments, and is trained with the objective that confidence of an action or interaction increases as time progresses. Lastly, we quantify the performance of both detection and prediction together, and analyze how the prediction accuracy varies as a time function of observed action (interaction) at different levels of detection performance. Our experiments on several datasets suggest that despite using only a few frames to localize actions (interactions) at each time instant, we are able to obtain competitive results to state-of-the-art offline methods.
The THUMOS Challenge on Action Recognition for Videos "in the Wild"
Apr 21, 2016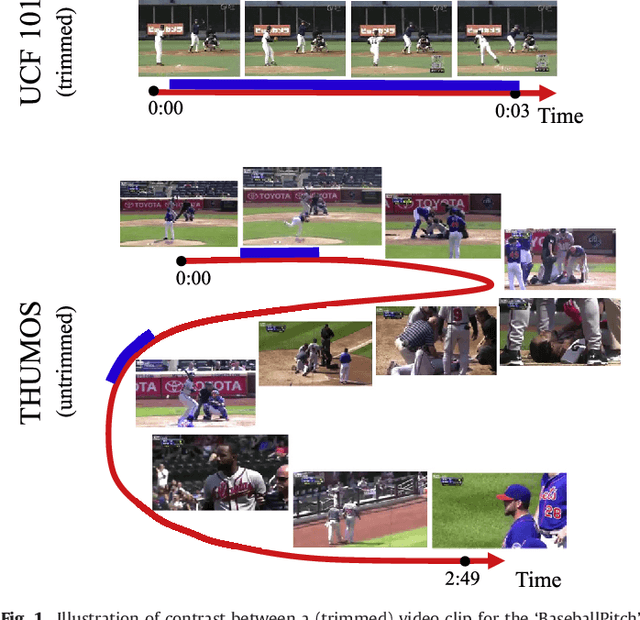
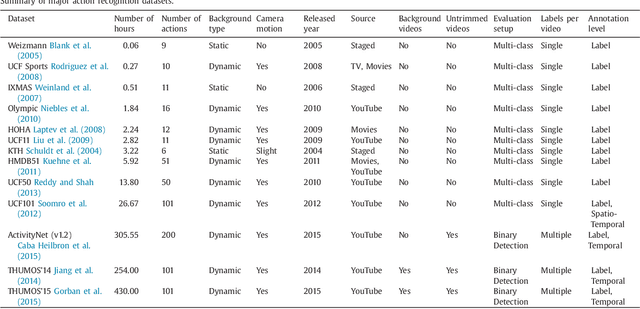
Automatically recognizing and localizing wide ranges of human actions has crucial importance for video understanding. Towards this goal, the THUMOS challenge was introduced in 2013 to serve as a benchmark for action recognition. Until then, video action recognition, including THUMOS challenge, had focused primarily on the classification of pre-segmented (i.e., trimmed) videos, which is an artificial task. In THUMOS 2014, we elevated action recognition to a more practical level by introducing temporally untrimmed videos. These also include `background videos' which share similar scenes and backgrounds as action videos, but are devoid of the specific actions. The three editions of the challenge organized in 2013--2015 have made THUMOS a common benchmark for action classification and detection and the annual challenge is widely attended by teams from around the world. In this paper we describe the THUMOS benchmark in detail and give an overview of data collection and annotation procedures. We present the evaluation protocols used to quantify results in the two THUMOS tasks of action classification and temporal detection. We also present results of submissions to the THUMOS 2015 challenge and review the participating approaches. Additionally, we include a comprehensive empirical study evaluating the differences in action recognition between trimmed and untrimmed videos, and how well methods trained on trimmed videos generalize to untrimmed videos. We conclude by proposing several directions and improvements for future THUMOS challenges.