 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Perception using Light Curtains for Autonomous Driving
Aug 05, 2020
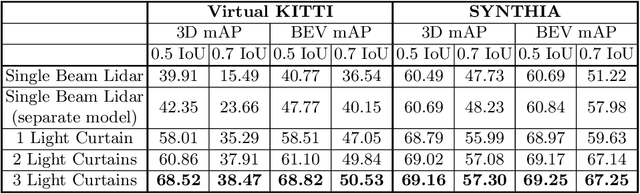
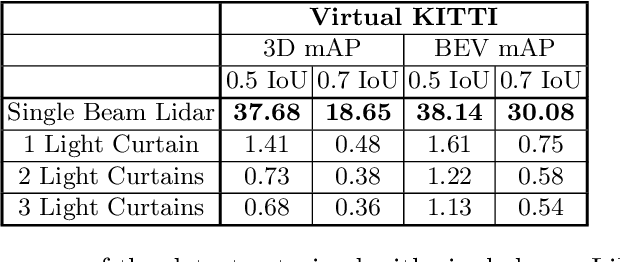
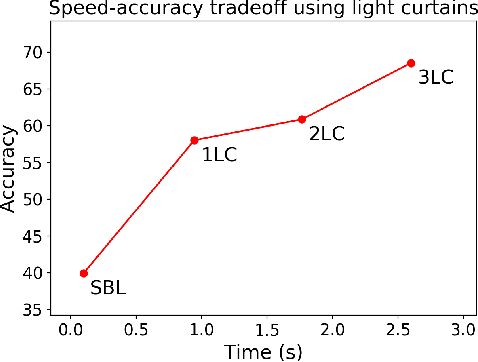
Most real-world 3D sensors such as LiDARs perform fixed scans of the entire environment, while being decoupled from the recognition system that processes the sensor data. In this work, we propose a method for 3D object recognition using light curtains, a resource-efficient controllable sensor that measures depth at user-specified locations in the environment. Crucially, we propose using prediction uncertainty of a deep learning based 3D point cloud detector to guide active perception. Given a neural network's uncertainty, we derive an optimization objective to place light curtains using the principle of maximizing information gain. Then, we develop a novel and efficient optimization algorithm to maximize this objective by encoding the physical constraints of the device into a constraint graph and optimizing with dynamic programming. We show how a 3D detector can be trained to detect objects in a scene by sequentially placing uncertainty-guided light curtains to successively improve detection accuracy. Code and details can be found on the project webpage: http://siddancha.github.io/projects/active-perception-light-curtains.
Single-Network Whole-Body Pose Estimation
Sep 30, 2019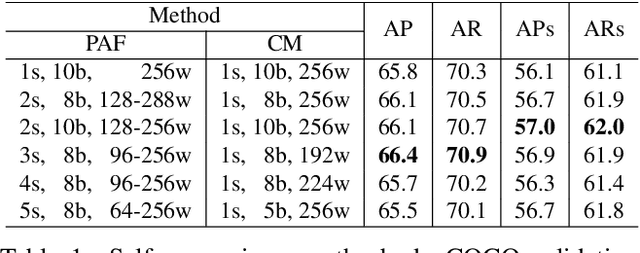
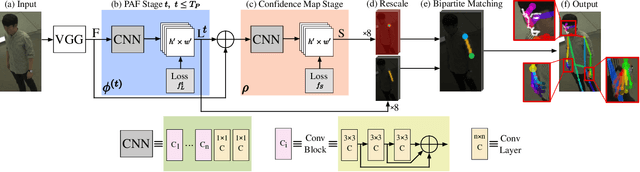


We present the first single-network approach for 2D~whole-body pose estimation, which entails simultaneous localization of body, face, hands, and feet keypoints. Due to the bottom-up formulation, our method maintains constant real-time performance regardless of the number of people in the image. The network is trained in a single stage using multi-task learning, through an improved architecture which can handle scale differences between body/foot and face/hand keypoints. Our approach considerably improves upon OpenPose~\cite{cao2018openpose}, the only work so far capable of whole-body pose estimation, both in terms of speed and global accuracy. Unlike OpenPose, our method does not need to run an additional network for each hand and face candidate, making it substantially faster for multi-person scenarios. This work directly results in a reduction of computational complexity for applications that require 2D whole-body information (e.g., VR/AR, re-targeting). In addition, it yields higher accuracy, especially for occluded, blurry, and low resolution faces and hands. For code, trained models, and validation benchmarks, visit our project page: https://github.com/CMU-Perceptual-Computing-Lab/openpose_train.
Exploring Pose Priors for Human Pose Estimation with Joint Angle Representations
Sep 27, 2019
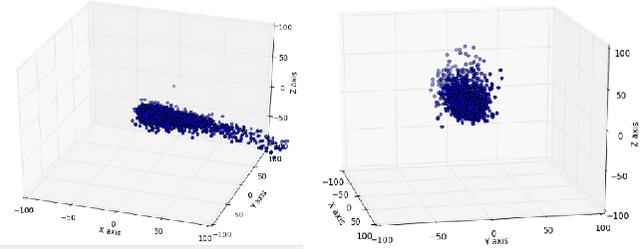
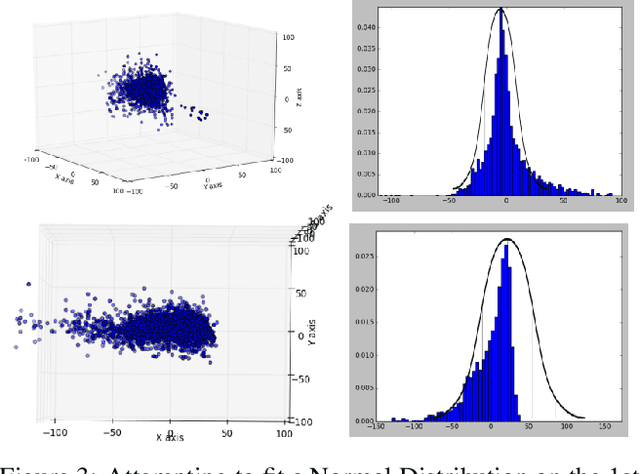
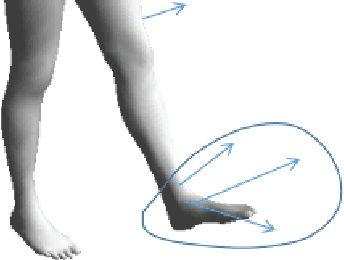
Pose Priors are critical in human pose estimation, since they are able to enforce constraints that prevent estimated poses from tending to physically impossible positions. Human pose generally consists of up to 22 Joint Angles of various segments, and their respective bone lengths, but the way these various segments interact can affect the validity of a pose. Looking at the Knee-Ankle segment alone, we can observe that clearly, the Knee cannot bend forward beyond it's roughly 90 degree point, amongst various other impossible poses below.
Efficient Online Multi-Person 2D Pose Tracking with Recurrent Spatio-Temporal Affinity Fields
Nov 29, 2018

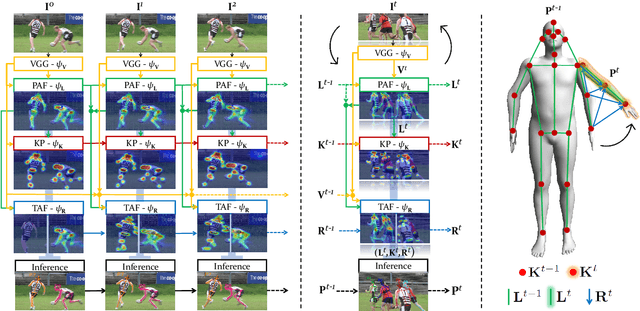
We present an online approach to efficiently and simultaneously detect and track the 2D pose of multiple people in a video sequence. We build upon Part Affinity Field (PAF) representation designed for static images, and propose an architecture that can encode and predict Spatio-Temporal Affinity Fields (STAF) across a video sequence. In particular, we propose a novel temporal topology cross-linked across limbs which can consistently handle body motions of a wide range of magnitudes. Additionally, we make the overall approach recurrent in nature, where the network ingests STAF heatmaps from previous frames and estimates those for the current frame. Our approach uses only online inference and tracking, and is currently the fastest and the most accurate bottom-up approach that is runtime invariant to the number of people in the scene and accuracy invariant to input frame rate of camera. Running at $\sim$30 fps on a single GPU at single scale, it achieves highly competitive results on the PoseTrack benchmarks.