 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoMP: Predicting Volumetric Mechanical Property Fields
Oct 27, 2025Physical simulation relies on spatially-varying mechanical properties, often laboriously hand-crafted. VoMP is a feed-forward method trained to predict Young's modulus ($E$), Poisson's ratio ($\nu$), and density ($\rho$) throughout the volume of 3D objects, in any representation that can be rendered and voxelized. VoMP aggregates per-voxel multi-view features and passes them to our trained Geometry Transformer to predict per-voxel material latent codes. These latents reside on a manifold of physically plausible materials, which we learn from a real-world dataset, guaranteeing the validity of decoded per-voxel materials. To obtain object-level training data, we propose an annotation pipeline combining knowledge from segmented 3D datasets, material databases, and a vision-language model, along with a new benchmark. Experiments show that VoMP estimates accurate volumetric properties, far outperforming prior art in accuracy and speed.
PARTFIELD: Learning 3D Feature Fields for Part Segmentation and Beyond
Apr 15, 2025We propose PartField, a feedforward approach for learning part-based 3D features, which captures the general concept of parts and their hierarchy without relying on predefined templates or text-based names, and can be applied to open-world 3D shapes across various modalities. PartField requires only a 3D feedforward pass at inference time, significantly improving runtime and robustness compared to prior approaches. Our model is trained by distilling 2D and 3D part proposals from a mix of labeled datasets and image segmentations on large unsupervised datasets, via a contrastive learning formulation. It produces a continuous feature field which can be clustered to yield a hierarchical part decomposition. Comparisons show that PartField is up to 20% more accurate and often orders of magnitude faster than other recent class-agnostic part-segmentation methods. Beyond single-shape part decomposition, consistency in the learned field emerges across shapes, enabling tasks such as co-segmentation and correspondence, which we demonstrate in several applications of these general-purpose, hierarchical, and consistent 3D feature fields. Check our Webpage! https://research.nvidia.com/labs/toronto-ai/partfield-release/
Articulated Kinematics Distillation from Video Diffusion Models
Apr 01, 2025We present Articulated Kinematics Distillation (AKD), a framework for generating high-fidelity character animations by merging the strengths of skeleton-based animation and modern generative models. AKD uses a skeleton-based representation for rigged 3D assets, drastically reducing the Degrees of Freedom (DoFs) by focusing on joint-level control, which allows for efficient, consistent motion synthesis. Through Score Distillation Sampling (SDS) with pre-trained video diffusion models, AKD distills complex, articulated motions while maintaining structural integrity, overcoming challenges faced by 4D neural deformation fields in preserving shape consistency. This approach is naturally compatible with physics-based simulation, ensuring physically plausible interactions. Experiments show that AKD achieves superior 3D consistency and motion quality compared with existing works on text-to-4D generation. Project page: https://research.nvidia.com/labs/dir/akd/
CoT-VLA: Visual Chain-of-Thought Reasoning for Vision-Language-Action Models
Mar 27, 2025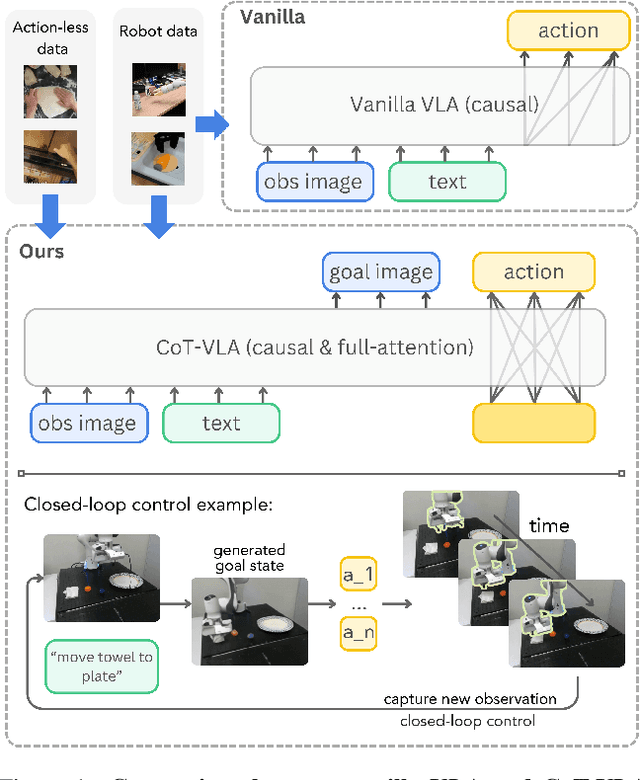

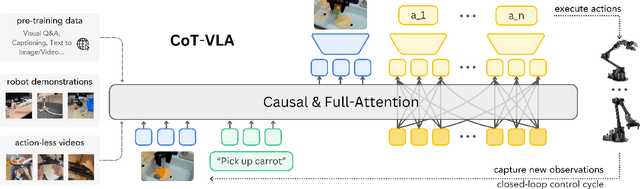
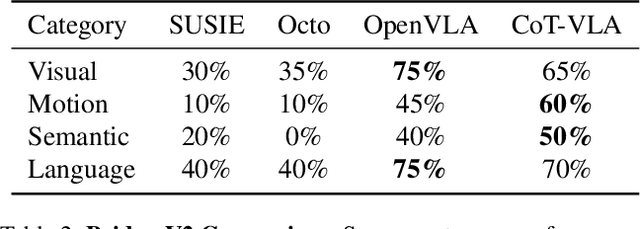
Vision-language-action models (VLAs) have shown potential in leveraging pretrained vision-language models and diverse robot demonstrations for learning generalizable sensorimotor control. While this paradigm effectively utilizes large-scale data from both robotic and non-robotic sources, current VLAs primarily focus on direct input--output mappings, lacking the intermediate reasoning steps crucial for complex manipulation tasks. As a result, existing VLAs lack temporal planning or reasoning capabilities. In this paper, we introduce a method that incorporates explicit visual chain-of-thought (CoT) reasoning into vision-language-action models (VLAs) by predicting future image frames autoregressively as visual goals before generating a short action sequence to achieve these goals. We introduce CoT-VLA, a state-of-the-art 7B VLA that can understand and generate visual and action tokens. Our experimental results demonstrate that CoT-VLA achieves strong performance, outperforming the state-of-the-art VLA model by 17% in real-world manipulation tasks and 6% in simulation benchmarks. Project website: https://cot-vla.github.io/
* Project website: https://cot-vla.github.io/
Edify 3D: Scalable High-Quality 3D Asset Generation
Nov 11, 2024
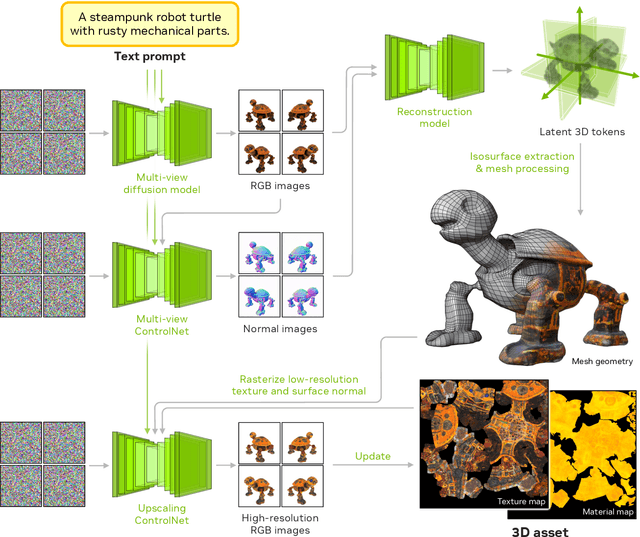
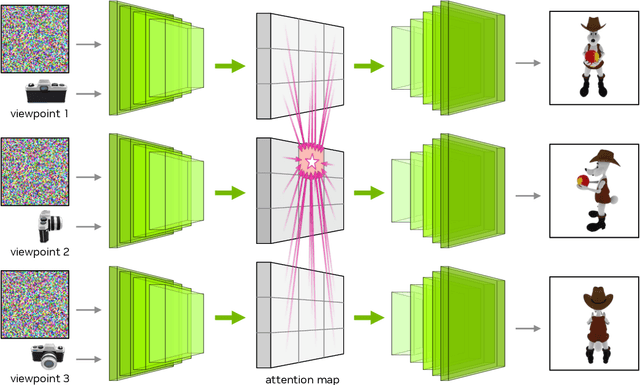

We introduce Edify 3D, an advanced solution designed for high-quality 3D asset generation. Our method first synthesizes RGB and surface normal images of the described object at multiple viewpoints using a diffusion model. The multi-view observations are then used to reconstruct the shape, texture, and PBR materials of the object. Our method can generate high-quality 3D assets with detailed geometry, clean shape topologies, high-resolution textures, and materials within 2 minutes of runtime.
DressRecon: Freeform 4D Human Reconstruction from Monocular Video
Sep 30, 2024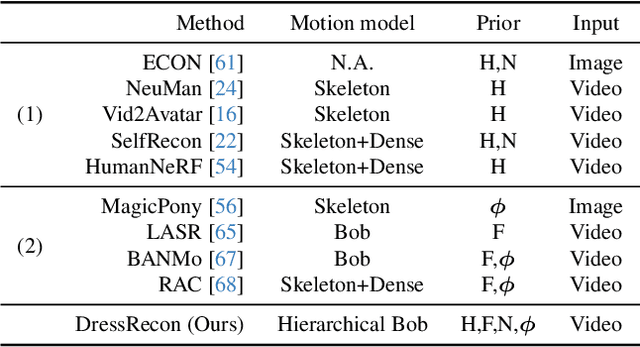
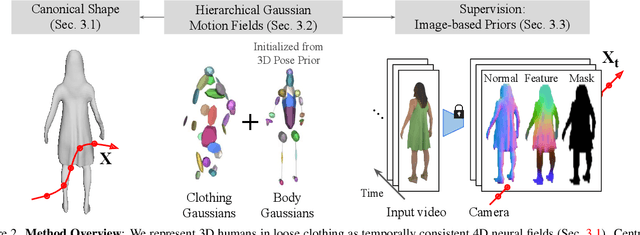
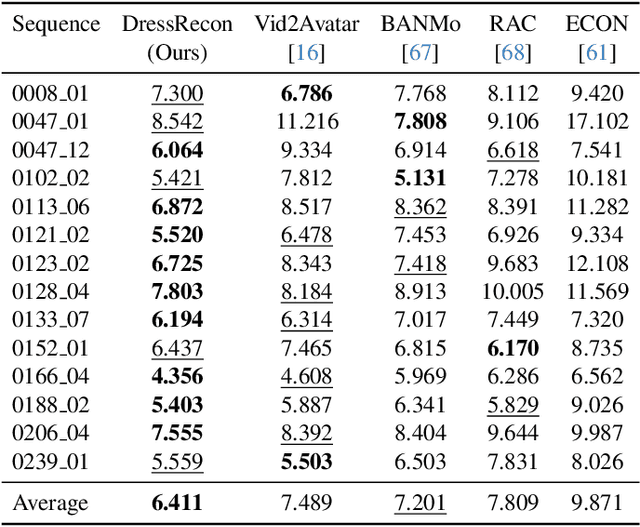
We present a method to reconstruct time-consistent human body models from monocular videos, focusing on extremely loose clothing or handheld object interactions. Prior work in human reconstruction is either limited to tight clothing with no object interactions, or requires calibrated multi-view captures or personalized template scans which are costly to collect at scale. Our key insight for high-quality yet flexible reconstruction is the careful combination of generic human priors about articulated body shape (learned from large-scale training data) with video-specific articulated "bag-of-bones" deformation (fit to a single video via test-time optimization). We accomplish this by learning a neural implicit model that disentangles body versus clothing deformations as separate motion model layers. To capture subtle geometry of clothing, we leverage image-based priors such as human body pose, surface normals, and optical flow during optimization. The resulting neural fields can be extracted into time-consistent meshes, or further optimized as explicit 3D Gaussians for high-fidelity interactive rendering. On datasets with highly challenging clothing deformations and object interactions, DressRecon yields higher-fidelity 3D reconstructions than prior art. Project page: https://jefftan969.github.io/dressrecon/
PhysAvatar: Learning the Physics of Dressed 3D Avatars from Visual Observations
Apr 09, 2024



Modeling and rendering photorealistic avatars is of crucial importance in many applications. Existing methods that build a 3D avatar from visual observations, however, struggle to reconstruct clothed humans. We introduce PhysAvatar, a novel framework that combines inverse rendering with inverse physics to automatically estimate the shape and appearance of a human from multi-view video data along with the physical parameters of the fabric of their clothes. For this purpose, we adopt a mesh-aligned 4D Gaussian technique for spatio-temporal mesh tracking as well as a physically based inverse renderer to estimate the intrinsic material properties. PhysAvatar integrates a physics simulator to estimate the physical parameters of the garments using gradient-based optimization in a principled manner. These novel capabilities enable PhysAvatar to create high-quality novel-view renderings of avatars dressed in loose-fitting clothes under motions and lighting conditions not seen in the training data. This marks a significant advancement towards modeling photorealistic digital humans using physically based inverse rendering with physics in the loop. Our project website is at: https://qingqing-zhao.github.io/PhysAvatar
Diffusion Shape Prior for Wrinkle-Accurate Cloth Registration
Nov 10, 2023



Registering clothes from 4D scans with vertex-accurate correspondence is challenging, yet important for dynamic appearance modeling and physics parameter estimation from real-world data. However, previous methods either rely on texture information, which is not always reliable, or achieve only coarse-level alignment. In this work, we present a novel approach to enabling accurate surface registration of texture-less clothes with large deformation. Our key idea is to effectively leverage a shape prior learned from pre-captured clothing using diffusion models. We also propose a multi-stage guidance scheme based on learned functional maps, which stabilizes registration for large-scale deformation even when they vary significantly from training data. Using high-fidelity real captured clothes, our experiments show that the proposed approach based on diffusion models generalizes better than surface registration with VAE or PCA-based priors, outperforming both optimization-based and learning-based non-rigid registration methods for both interpolation and extrapolation tests.
Drivable Avatar Clothing: Faithful Full-Body Telepresence with Dynamic Clothing Driven by Sparse RGB-D Input
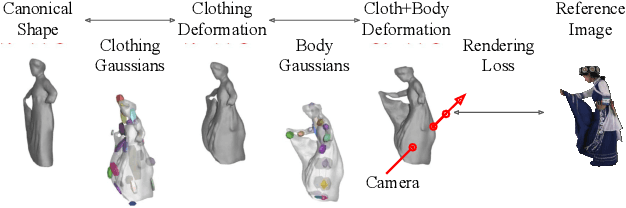
Oct 11, 2023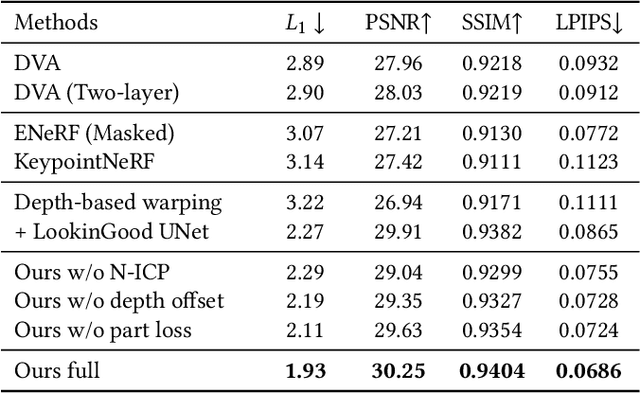


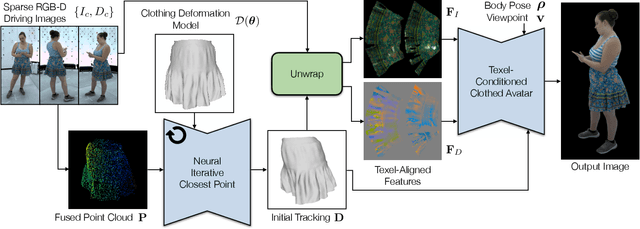
Clothing is an important part of human appearance but challenging to model in photorealistic avatars. In this work we present avatars with dynamically moving loose clothing that can be faithfully driven by sparse RGB-D inputs as well as body and face motion. We propose a Neural Iterative Closest Point (N-ICP) algorithm that can efficiently track the coarse garment shape given sparse depth input. Given the coarse tracking results, the input RGB-D images are then remapped to texel-aligned features, which are fed into the drivable avatar models to faithfully reconstruct appearance details. We evaluate our method against recent image-driven synthesis baselines, and conduct a comprehensive analysis of the N-ICP algorithm. We demonstrate that our method can generalize to a novel testing environment, while preserving the ability to produce high-fidelity and faithful clothing dynamics and appearance.
Dressing Avatars: Deep Photorealistic Appearance for Physically Simulated Clothing
Jun 30, 2022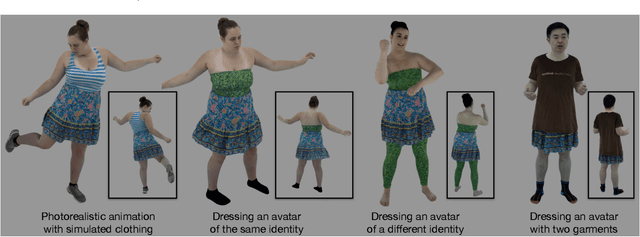
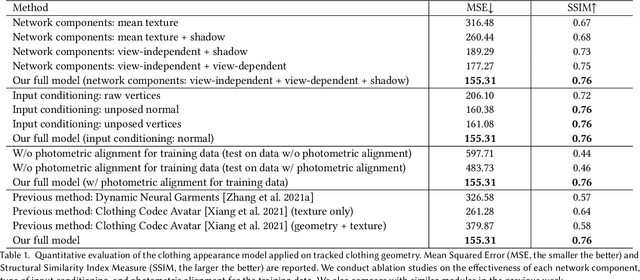
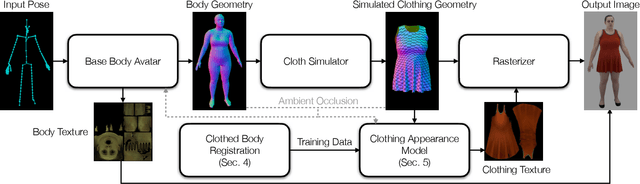
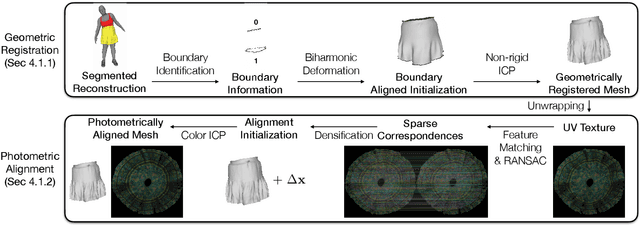
Despite recent progress in developing animatable full-body avatars, realistic modeling of clothing - one of the core aspects of human self-expression - remains an open challenge. State-of-the-art physical simulation methods can generate realistically behaving clothing geometry at interactive rate. Modeling photorealistic appearance, however, usually requires physically-based rendering which is too expensive for interactive applications. On the other hand, data-driven deep appearance models are capable of efficiently producing realistic appearance, but struggle at synthesizing geometry of highly dynamic clothing and handling challenging body-clothing configurations. To this end, we introduce pose-driven avatars with explicit modeling of clothing that exhibit both realistic clothing dynamics and photorealistic appearance learned from real-world data. The key idea is to introduce a neural clothing appearance model that operates on top of explicit geometry: at train time we use high-fidelity tracking, whereas at animation time we rely on physically simulated geometry. Our key contribution is a physically-inspired appearance network, capable of generating photorealistic appearance with view-dependent and dynamic shadowing effects even for unseen body-clothing configurations. We conduct a thorough evaluation of our model and demonstrate diverse animation results on several subjects and different types of clothing. Unlike previous work on photorealistic full-body avatars, our approach can produce much richer dynamics and more realistic deformations even for loose clothing. We also demonstrate that our formulation naturally allows clothing to be used with avatars of different people while staying fully animatable, thus enabling, for the first time, photorealistic avatars with novel clothing.