 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEgoVLA: Learning Vision-Language-Action Models from Egocentric Human Videos
Jul 16, 2025Real robot data collection for imitation learning has led to significant advancements in robotic manipulation. However, the requirement for robot hardware in the process fundamentally constrains the scale of the data. In this paper, we explore training Vision-Language-Action (VLA) models using egocentric human videos. The benefit of using human videos is not only for their scale but more importantly for the richness of scenes and tasks. With a VLA trained on human video that predicts human wrist and hand actions, we can perform Inverse Kinematics and retargeting to convert the human actions to robot actions. We fine-tune the model using a few robot manipulation demonstrations to obtain the robot policy, namely EgoVLA. We propose a simulation benchmark called Isaac Humanoid Manipulation Benchmark, where we design diverse bimanual manipulation tasks with demonstrations. We fine-tune and evaluate EgoVLA with Isaac Humanoid Manipulation Benchmark and show significant improvements over baselines and ablate the importance of human data. Videos can be found on our website: https://rchalyang.github.io/EgoVLA
CoT-VLA: Visual Chain-of-Thought Reasoning for Vision-Language-Action Models
Mar 27, 2025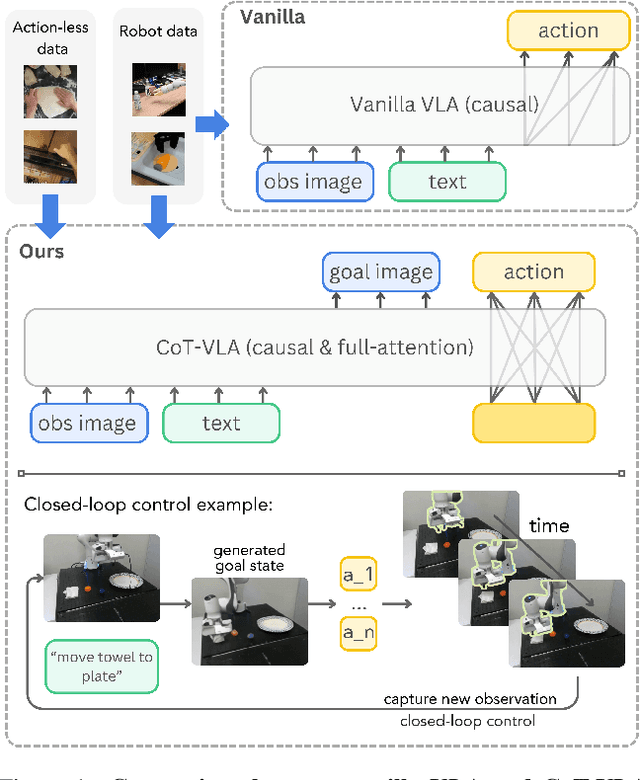

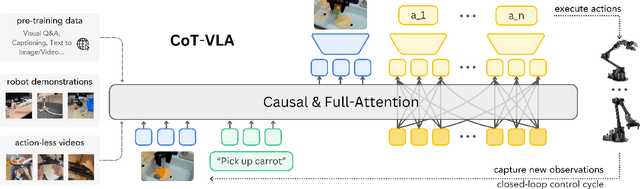
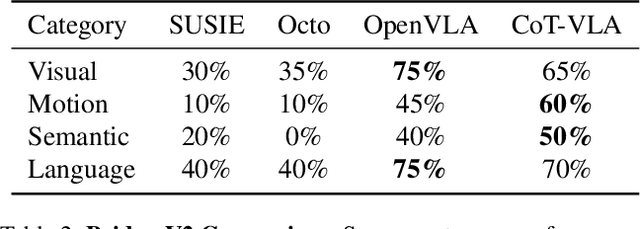
Vision-language-action models (VLAs) have shown potential in leveraging pretrained vision-language models and diverse robot demonstrations for learning generalizable sensorimotor control. While this paradigm effectively utilizes large-scale data from both robotic and non-robotic sources, current VLAs primarily focus on direct input--output mappings, lacking the intermediate reasoning steps crucial for complex manipulation tasks. As a result, existing VLAs lack temporal planning or reasoning capabilities. In this paper, we introduce a method that incorporates explicit visual chain-of-thought (CoT) reasoning into vision-language-action models (VLAs) by predicting future image frames autoregressively as visual goals before generating a short action sequence to achieve these goals. We introduce CoT-VLA, a state-of-the-art 7B VLA that can understand and generate visual and action tokens. Our experimental results demonstrate that CoT-VLA achieves strong performance, outperforming the state-of-the-art VLA model by 17% in real-world manipulation tasks and 6% in simulation benchmarks. Project website: https://cot-vla.github.io/
* Project website: https://cot-vla.github.io/
HART: Efficient Visual Generation with Hybrid Autoregressive Transformer
Oct 14, 2024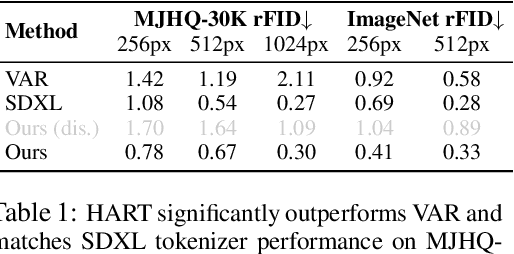

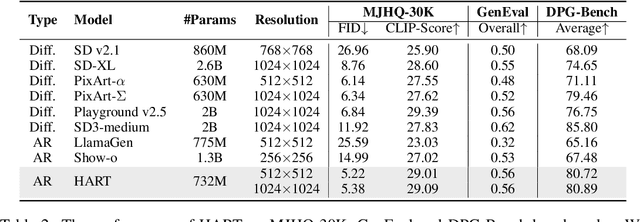

We introduce Hybrid Autoregressive Transformer (HART), an autoregressive (AR) visual generation model capable of directly generating 1024x1024 images, rivaling diffusion models in image generation quality. Existing AR models face limitations due to the poor image reconstruction quality of their discrete tokenizers and the prohibitive training costs associated with generating 1024px images. To address these challenges, we present the hybrid tokenizer, which decomposes the continuous latents from the autoencoder into two components: discrete tokens representing the big picture and continuous tokens representing the residual components that cannot be represented by the discrete tokens. The discrete component is modeled by a scalable-resolution discrete AR model, while the continuous component is learned with a lightweight residual diffusion module with only 37M parameters. Compared with the discrete-only VAR tokenizer, our hybrid approach improves reconstruction FID from 2.11 to 0.30 on MJHQ-30K, leading to a 31% generation FID improvement from 7.85 to 5.38. HART also outperforms state-of-the-art diffusion models in both FID and CLIP score, with 4.5-7.7x higher throughput and 6.9-13.4x lower MACs. Our code is open sourced at https://github.com/mit-han-lab/hart.
VILA-U: a Unified Foundation Model Integrating Visual Understanding and Generation
Sep 06, 2024


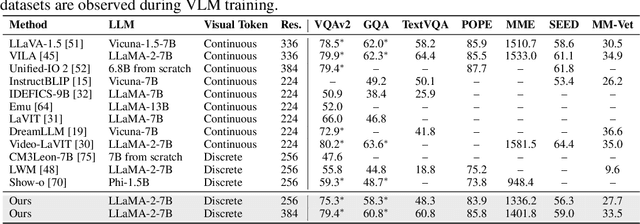
VILA-U is a Unified foundation model that integrates Video, Image, Language understanding and generation. Traditional visual language models (VLMs) use separate modules for understanding and generating visual content, which can lead to misalignment and increased complexity. In contrast, VILA-U employs a single autoregressive next-token prediction framework for both tasks, eliminating the need for additional components like diffusion models. This approach not only simplifies the model but also achieves near state-of-the-art performance in visual language understanding and generation. The success of VILA-U is attributed to two main factors: the unified vision tower that aligns discrete visual tokens with textual inputs during pretraining, which enhances visual perception, and autoregressive image generation can achieve similar quality as diffusion models with high-quality dataset. This allows VILA-U to perform comparably to more complex models using a fully token-based autoregressive framework.