 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Degradation with Vision Language Model
Feb 04, 2026Understanding visual degradations is a critical yet challenging problem in computer vision. While recent Vision-Language Models (VLMs) excel at qualitative description, they often fall short in understanding the parametric physics underlying image degradations. In this work, we redefine degradation understanding as a hierarchical structured prediction task, necessitating the concurrent estimation of degradation types, parameter keys, and their continuous physical values. Although these sub-tasks operate in disparate spaces, we prove that they can be unified under one autoregressive next-token prediction paradigm, whose error is bounded by the value-space quantization grid. Building on this insight, we introduce DU-VLM, a multimodal chain-of-thought model trained with supervised fine-tuning and reinforcement learning using structured rewards. Furthermore, we show that DU-VLM can serve as a zero-shot controller for pre-trained diffusion models, enabling high-fidelity image restoration without fine-tuning the generative backbone. We also introduce \textbf{DU-110k}, a large-scale dataset comprising 110,000 clean-degraded pairs with grounded physical annotations. Extensive experiments demonstrate that our approach significantly outperforms generalist baselines in both accuracy and robustness, exhibiting generalization to unseen distributions.
Paper2Rebuttal: A Multi-Agent Framework for Transparent Author Response Assistance
Jan 20, 2026Writing effective rebuttals is a high-stakes task that demands more than linguistic fluency, as it requires precise alignment between reviewer intent and manuscript details. Current solutions typically treat this as a direct-to-text generation problem, suffering from hallucination, overlooked critiques, and a lack of verifiable grounding. To address these limitations, we introduce $\textbf{RebuttalAgent}$, the first multi-agents framework that reframes rebuttal generation as an evidence-centric planning task. Our system decomposes complex feedback into atomic concerns and dynamically constructs hybrid contexts by synthesizing compressed summaries with high-fidelity text while integrating an autonomous and on-demand external search module to resolve concerns requiring outside literature. By generating an inspectable response plan before drafting, $\textbf{RebuttalAgent}$ ensures that every argument is explicitly anchored in internal or external evidence. We validate our approach on the proposed $\textbf{RebuttalBench}$ and demonstrate that our pipeline outperforms strong baselines in coverage, faithfulness, and strategic coherence, offering a transparent and controllable assistant for the peer review process. Code will be released.
A Unified Shape-Aware Foundation Model for Time Series Classification
Jan 10, 2026Foundation models pre-trained on large-scale source datasets are reshaping the traditional training paradigm for time series classification. However, existing time series foundation models primarily focus on forecasting tasks and often overlook classification-specific challenges, such as modeling interpretable shapelets that capture class-discriminative temporal features. To bridge this gap, we propose UniShape, a unified shape-aware foundation model designed for time series classification. UniShape incorporates a shape-aware adapter that adaptively aggregates multiscale discriminative subsequences (shapes) into class tokens, effectively selecting the most relevant subsequence scales to enhance model interpretability. Meanwhile, a prototype-based pretraining module is introduced to jointly learn instance- and shape-level representations, enabling the capture of transferable shape patterns. Pre-trained on a large-scale multi-domain time series dataset comprising 1.89 million samples, UniShape exhibits superior generalization across diverse target domains. Experiments on 128 UCR datasets and 30 additional time series datasets demonstrate that UniShape achieves state-of-the-art classification performance, with interpretability and ablation analyses further validating its effectiveness.
The RoboSense Challenge: Sense Anything, Navigate Anywhere, Adapt Across Platforms
Jan 08, 2026Autonomous systems are increasingly deployed in open and dynamic environments -- from city streets to aerial and indoor spaces -- where perception models must remain reliable under sensor noise, environmental variation, and platform shifts. However, even state-of-the-art methods often degrade under unseen conditions, highlighting the need for robust and generalizable robot sensing. The RoboSense 2025 Challenge is designed to advance robustness and adaptability in robot perception across diverse sensing scenarios. It unifies five complementary research tracks spanning language-grounded decision making, socially compliant navigation, sensor configuration generalization, cross-view and cross-modal correspondence, and cross-platform 3D perception. Together, these tasks form a comprehensive benchmark for evaluating real-world sensing reliability under domain shifts, sensor failures, and platform discrepancies. RoboSense 2025 provides standardized datasets, baseline models, and unified evaluation protocols, enabling large-scale and reproducible comparison of robust perception methods. The challenge attracted 143 teams from 85 institutions across 16 countries, reflecting broad community engagement. By consolidating insights from 23 winning solutions, this report highlights emerging methodological trends, shared design principles, and open challenges across all tracks, marking a step toward building robots that can sense reliably, act robustly, and adapt across platforms in real-world environments.
Virtual Width Networks
Nov 17, 2025



We introduce Virtual Width Networks (VWN), a framework that delivers the benefits of wider representations without incurring the quadratic cost of increasing the hidden size. VWN decouples representational width from backbone width, expanding the embedding space while keeping backbone compute nearly constant. In our large-scale experiment, an 8-times expansion accelerates optimization by over 2 times for next-token and 3 times for next-2-token prediction. The advantage amplifies over training as both the loss gap grows and the convergence-speedup ratio increases, showing that VWN is not only token-efficient but also increasingly effective with scale. Moreover, we identify an approximately log-linear scaling relation between virtual width and loss reduction, offering an initial empirical basis and motivation for exploring virtual-width scaling as a new dimension of large-model efficiency.
HyperIMTS: Hypergraph Neural Network for Irregular Multivariate Time Series Forecasting
May 23, 2025Irregular multivariate time series (IMTS) are characterized by irregular time intervals within variables and unaligned observations across variables, posing challenges in learning temporal and variable dependencies. Many existing IMTS models either require padded samples to learn separately from temporal and variable dimensions, or represent original samples via bipartite graphs or sets. However, the former approaches often need to handle extra padding values affecting efficiency and disrupting original sampling patterns, while the latter ones have limitations in capturing dependencies among unaligned observations. To represent and learn both dependencies from original observations in a unified form, we propose HyperIMTS, a Hypergraph neural network for Irregular Multivariate Time Series forecasting. Observed values are converted as nodes in the hypergraph, interconnected by temporal and variable hyperedges to enable message passing among all observations. Through irregularity-aware message passing, HyperIMTS captures variable dependencies in a time-adaptive way to achieve accurate forecasting. Experiments demonstrate HyperIMTS's competitive performance among state-of-the-art models in IMTS forecasting with low computational cost.
LifelongAgentBench: Evaluating LLM Agents as Lifelong Learners
May 17, 2025Lifelong learning is essential for intelligent agents operating in dynamic environments. Current large language model (LLM)-based agents, however, remain stateless and unable to accumulate or transfer knowledge over time. Existing benchmarks treat agents as static systems and fail to evaluate lifelong learning capabilities. We present LifelongAgentBench, the first unified benchmark designed to systematically assess the lifelong learning ability of LLM agents. It provides skill-grounded, interdependent tasks across three interactive environments, Database, Operating System, and Knowledge Graph, with automatic label verification, reproducibility, and modular extensibility. Extensive experiments reveal that conventional experience replay has limited effectiveness for LLM agents due to irrelevant information and context length constraints. We further introduce a group self-consistency mechanism that significantly improves lifelong learning performance. We hope LifelongAgentBench will advance the development of adaptive, memory-capable LLM agents.
Learning Soft Sparse Shapes for Efficient Time-Series Classification
May 11, 2025Shapelets are discriminative subsequences (or shapes) with high interpretability in time series classification. Due to the time-intensive nature of shapelet discovery, existing shapelet-based methods mainly focus on selecting discriminative shapes while discarding others to achieve candidate subsequence sparsification. However, this approach may exclude beneficial shapes and overlook the varying contributions of shapelets to classification performance. To this end, we propose a \textbf{Soft} sparse \textbf{Shape}s (\textbf{SoftShape}) model for efficient time series classification. Our approach mainly introduces soft shape sparsification and soft shape learning blocks. The former transforms shapes into soft representations based on classification contribution scores, merging lower-scored ones into a single shape to retain and differentiate all subsequence information. The latter facilitates intra- and inter-shape temporal pattern learning, improving model efficiency by using sparsified soft shapes as inputs. Specifically, we employ a learnable router to activate a subset of class-specific expert networks for intra-shape pattern learning. Meanwhile, a shared expert network learns inter-shape patterns by converting sparsified shapes into sequences. Extensive experiments show that SoftShape outperforms state-of-the-art methods and produces interpretable results.
Articulated Kinematics Distillation from Video Diffusion Models
Apr 01, 2025We present Articulated Kinematics Distillation (AKD), a framework for generating high-fidelity character animations by merging the strengths of skeleton-based animation and modern generative models. AKD uses a skeleton-based representation for rigged 3D assets, drastically reducing the Degrees of Freedom (DoFs) by focusing on joint-level control, which allows for efficient, consistent motion synthesis. Through Score Distillation Sampling (SDS) with pre-trained video diffusion models, AKD distills complex, articulated motions while maintaining structural integrity, overcoming challenges faced by 4D neural deformation fields in preserving shape consistency. This approach is naturally compatible with physics-based simulation, ensuring physically plausible interactions. Experiments show that AKD achieves superior 3D consistency and motion quality compared with existing works on text-to-4D generation. Project page: https://research.nvidia.com/labs/dir/akd/
CoT-VLA: Visual Chain-of-Thought Reasoning for Vision-Language-Action Models
Mar 27, 2025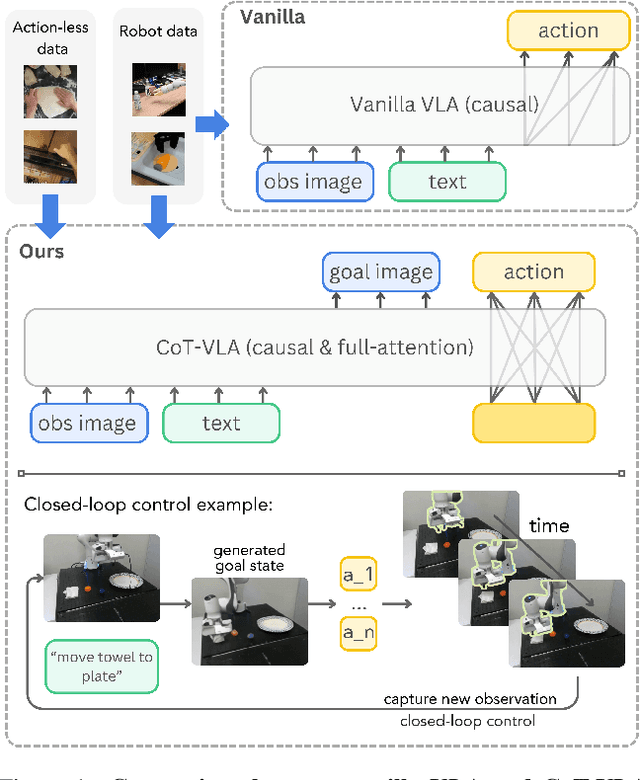

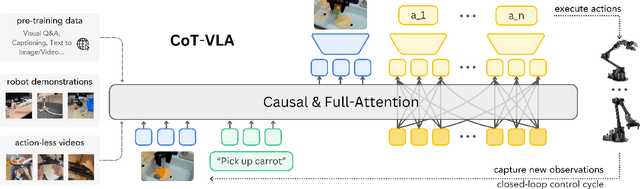
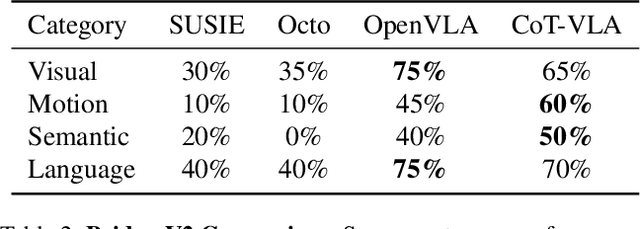
Vision-language-action models (VLAs) have shown potential in leveraging pretrained vision-language models and diverse robot demonstrations for learning generalizable sensorimotor control. While this paradigm effectively utilizes large-scale data from both robotic and non-robotic sources, current VLAs primarily focus on direct input--output mappings, lacking the intermediate reasoning steps crucial for complex manipulation tasks. As a result, existing VLAs lack temporal planning or reasoning capabilities. In this paper, we introduce a method that incorporates explicit visual chain-of-thought (CoT) reasoning into vision-language-action models (VLAs) by predicting future image frames autoregressively as visual goals before generating a short action sequence to achieve these goals. We introduce CoT-VLA, a state-of-the-art 7B VLA that can understand and generate visual and action tokens. Our experimental results demonstrate that CoT-VLA achieves strong performance, outperforming the state-of-the-art VLA model by 17% in real-world manipulation tasks and 6% in simulation benchmarks. Project website: https://cot-vla.github.io/
* Project website: https://cot-vla.github.io/