 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeed1.5-VL Technical Report
May 11, 2025



We present Seed1.5-VL, a vision-language foundation model designed to advance general-purpose multimodal understanding and reasoning. Seed1.5-VL is composed with a 532M-parameter vision encoder and a Mixture-of-Experts (MoE) LLM of 20B active parameters. Despite its relatively compact architecture, it delivers strong performance across a wide spectrum of public VLM benchmarks and internal evaluation suites, achieving the state-of-the-art performance on 38 out of 60 public benchmarks. Moreover, in agent-centric tasks such as GUI control and gameplay, Seed1.5-VL outperforms leading multimodal systems, including OpenAI CUA and Claude 3.7. Beyond visual and video understanding, it also demonstrates strong reasoning abilities, making it particularly effective for multimodal reasoning challenges such as visual puzzles. We believe these capabilities will empower broader applications across diverse tasks. In this report, we mainly provide a comprehensive review of our experiences in building Seed1.5-VL across model design, data construction, and training at various stages, hoping that this report can inspire further research. Seed1.5-VL is now accessible at https://www.volcengine.com/ (Volcano Engine Model ID: doubao-1-5-thinking-vision-pro-250428)
UI-TARS: Pioneering Automated GUI Interaction with Native Agents
Jan 21, 2025This paper introduces UI-TARS, a native GUI agent model that solely perceives the screenshots as input and performs human-like interactions (e.g., keyboard and mouse operations). Unlike prevailing agent frameworks that depend on heavily wrapped commercial models (e.g., GPT-4o) with expert-crafted prompts and workflows, UI-TARS is an end-to-end model that outperforms these sophisticated frameworks. Experiments demonstrate its superior performance: UI-TARS achieves SOTA performance in 10+ GUI agent benchmarks evaluating perception, grounding, and GUI task execution. Notably, in the OSWorld benchmark, UI-TARS achieves scores of 24.6 with 50 steps and 22.7 with 15 steps, outperforming Claude (22.0 and 14.9 respectively). In AndroidWorld, UI-TARS achieves 46.6, surpassing GPT-4o (34.5). UI-TARS incorporates several key innovations: (1) Enhanced Perception: leveraging a large-scale dataset of GUI screenshots for context-aware understanding of UI elements and precise captioning; (2) Unified Action Modeling, which standardizes actions into a unified space across platforms and achieves precise grounding and interaction through large-scale action traces; (3) System-2 Reasoning, which incorporates deliberate reasoning into multi-step decision making, involving multiple reasoning patterns such as task decomposition, reflection thinking, milestone recognition, etc. (4) Iterative Training with Reflective Online Traces, which addresses the data bottleneck by automatically collecting, filtering, and reflectively refining new interaction traces on hundreds of virtual machines. Through iterative training and reflection tuning, UI-TARS continuously learns from its mistakes and adapts to unforeseen situations with minimal human intervention. We also analyze the evolution path of GUI agents to guide the further development of this domain.
StableToolBench: Towards Stable Large-Scale Benchmarking on Tool Learning of Large Language Models
Mar 13, 2024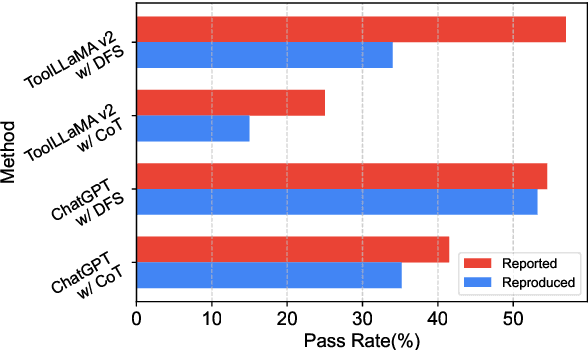
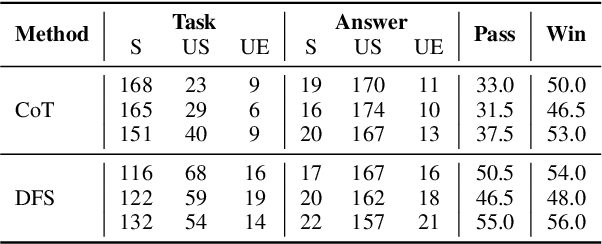
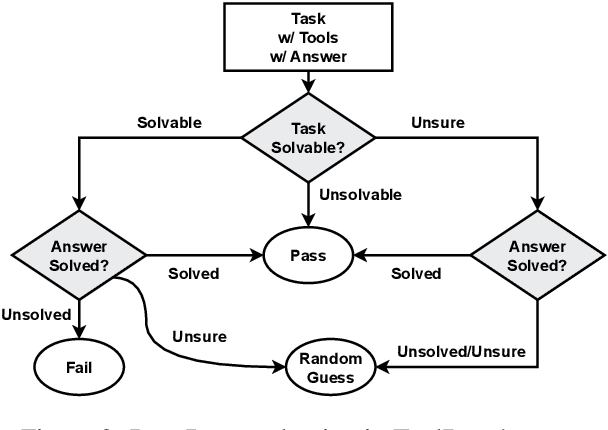
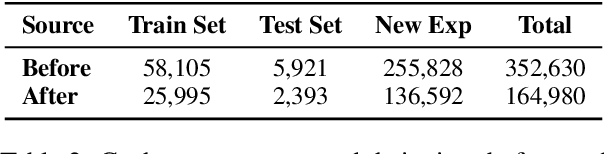
Large Language Models (LLMs) have witnessed remarkable advancements in recent years, prompting the exploration of tool learning, which integrates LLMs with external tools to address diverse real-world challenges. Assessing the capability of LLMs to utilise tools necessitates large-scale and stable benchmarks. However, previous works relied on either hand-crafted online tools with limited scale, or large-scale real online APIs suffering from instability of API status. To address this problem, we introduce StableToolBench, a benchmark evolving from ToolBench, proposing a virtual API server and stable evaluation system. The virtual API server contains a caching system and API simulators which are complementary to alleviate the change in API status. Meanwhile, the stable evaluation system designs solvable pass and win rates using GPT-4 as the automatic evaluator to eliminate the randomness during evaluation. Experimental results demonstrate the stability of StableToolBench, and further discuss the effectiveness of API simulators, the caching system, and the evaluator system.
RepoAgent: An LLM-Powered Open-Source Framework for Repository-level Code Documentation Generation
Feb 26, 2024
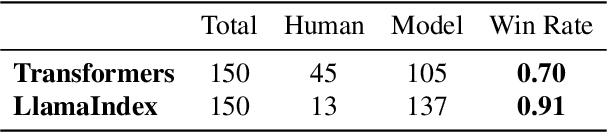
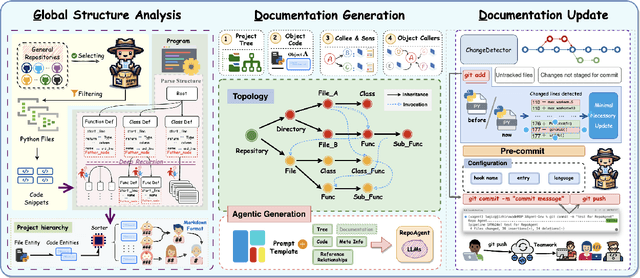
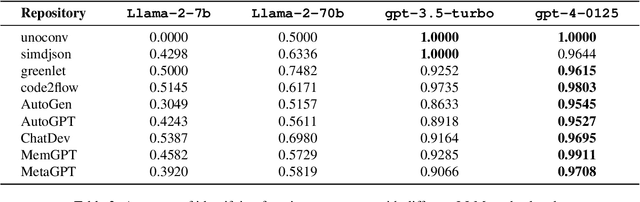
Generative models have demonstrated considerable potential in software engineering, particularly in tasks such as code generation and debugging. However, their utilization in the domain of code documentation generation remains underexplored. To this end, we introduce RepoAgent, a large language model powered open-source framework aimed at proactively generating, maintaining, and updating code documentation. Through both qualitative and quantitative evaluations, we have validated the effectiveness of our approach, showing that RepoAgent excels in generating high-quality repository-level documentation. The code and results are publicly accessible at https://github.com/OpenBMB/RepoAgent.
Investigate-Consolidate-Exploit: A General Strategy for Inter-Task Agent Self-Evolution
Jan 25, 2024This paper introduces Investigate-Consolidate-Exploit (ICE), a novel strategy for enhancing the adaptability and flexibility of AI agents through inter-task self-evolution. Unlike existing methods focused on intra-task learning, ICE promotes the transfer of knowledge between tasks for genuine self-evolution, similar to human experience learning. The strategy dynamically investigates planning and execution trajectories, consolidates them into simplified workflows and pipelines, and exploits them for improved task execution. Our experiments on the XAgent framework demonstrate ICE's effectiveness, reducing API calls by as much as 80% and significantly decreasing the demand for the model's capability. Specifically, when combined with GPT-3.5, ICE's performance matches that of raw GPT-4 across various agent tasks. We argue that this self-evolution approach represents a paradigm shift in agent design, contributing to a more robust AI community and ecosystem, and moving a step closer to full autonomy.
QASnowball: An Iterative Bootstrapping Framework for High-Quality Question-Answering Data Generation
Sep 20, 2023



Recent years have witnessed the success of question answering (QA), especially its potential to be a foundation paradigm for tackling diverse NLP tasks. However, obtaining sufficient data to build an effective and stable QA system still remains an open problem. For this problem, we introduce an iterative bootstrapping framework for QA data augmentation (named QASnowball), which can iteratively generate large-scale high-quality QA data based on a seed set of supervised examples. Specifically, QASnowball consists of three modules, an answer extractor to extract core phrases in unlabeled documents as candidate answers, a question generator to generate questions based on documents and candidate answers, and a QA data filter to filter out high-quality QA data. Moreover, QASnowball can be self-enhanced by reseeding the seed set to fine-tune itself in different iterations, leading to continual improvements in the generation quality. We conduct experiments in the high-resource English scenario and the medium-resource Chinese scenario, and the experimental results show that the data generated by QASnowball can facilitate QA models: (1) training models on the generated data achieves comparable results to using supervised data, and (2) pre-training on the generated data and fine-tuning on supervised data can achieve better performance. Our code and generated data will be released to advance further work.
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs
Jul 31, 2023Despite the advancements of open-source large language models (LLMs) and their variants, e.g., LLaMA and Vicuna, they remain significantly limited in performing higher-level tasks, such as following human instructions to use external tools (APIs). This is because current instruction tuning largely focuses on basic language tasks instead of the tool-use domain. This is in contrast to state-of-the-art (SOTA) LLMs, e.g., ChatGPT, which have demonstrated excellent tool-use capabilities but are unfortunately closed source. To facilitate tool-use capabilities within open-source LLMs, we introduce ToolLLM, a general tool-use framework of data construction, model training and evaluation. We first present ToolBench, an instruction-tuning dataset for tool use, which is created automatically using ChatGPT. Specifically, we collect 16,464 real-world RESTful APIs spanning 49 categories from RapidAPI Hub, then prompt ChatGPT to generate diverse human instructions involving these APIs, covering both single-tool and multi-tool scenarios. Finally, we use ChatGPT to search for a valid solution path (chain of API calls) for each instruction. To make the searching process more efficient, we develop a novel depth-first search-based decision tree (DFSDT), enabling LLMs to evaluate multiple reasoning traces and expand the search space. We show that DFSDT significantly enhances the planning and reasoning capabilities of LLMs. For efficient tool-use assessment, we develop an automatic evaluator: ToolEval. We fine-tune LLaMA on ToolBench and obtain ToolLLaMA. Our ToolEval reveals that ToolLLaMA demonstrates a remarkable ability to execute complex instructions and generalize to unseen APIs, and exhibits comparable performance to ChatGPT. To make the pipeline more practical, we devise a neural API retriever to recommend appropriate APIs for each instruction, negating the need for manual API selection.
Exploring Format Consistency for Instruction Tuning
Jul 28, 2023



Instruction tuning has emerged as a promising approach to enhancing large language models in following human instructions. It is shown that increasing the diversity and number of instructions in the training data can consistently enhance generalization performance, which facilitates a recent endeavor to collect various instructions and integrate existing instruction tuning datasets into larger collections. However, different users have their unique ways of expressing instructions, and there often exist variations across different datasets in the instruction styles and formats, i.e., format inconsistency. In this work, we study how format inconsistency may impact the performance of instruction tuning. We propose a framework called "Unified Instruction Tuning" (UIT), which calls OpenAI APIs for automatic format transfer among different instruction tuning datasets. We show that UIT successfully improves the generalization performance on unseen instructions, which highlights the importance of format consistency for instruction tuning. To make the UIT framework more practical, we further propose a novel perplexity-based denoising method to reduce the noise of automatic format transfer. We also train a smaller offline model that achieves comparable format transfer capability than OpenAI APIs to reduce costs in practice.
WebCPM: Interactive Web Search for Chinese Long-form Question Answering
May 23, 2023

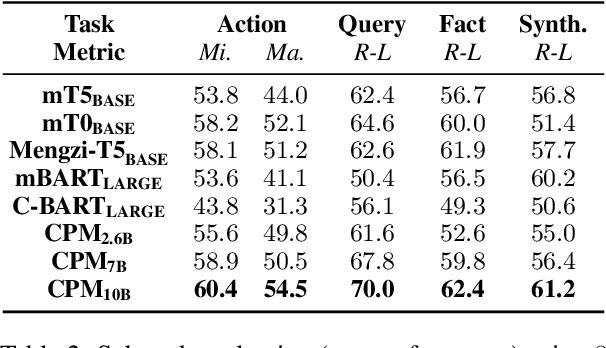

Long-form question answering (LFQA) aims at answering complex, open-ended questions with detailed, paragraph-length responses. The de facto paradigm of LFQA necessitates two procedures: information retrieval, which searches for relevant supporting facts, and information synthesis, which integrates these facts into a coherent answer. In this paper, we introduce WebCPM, the first Chinese LFQA dataset. One unique feature of WebCPM is that its information retrieval is based on interactive web search, which engages with a search engine in real time. Following WebGPT, we develop a web search interface. We recruit annotators to search for relevant information using our interface and then answer questions. Meanwhile, the web search behaviors of our annotators would be recorded. In total, we collect 5,500 high-quality question-answer pairs, together with 14,315 supporting facts and 121,330 web search actions. We fine-tune pre-trained language models to imitate human behaviors for web search and to generate answers based on the collected facts. Our LFQA pipeline, built on these fine-tuned models, generates answers that are no worse than human-written ones in 32.5% and 47.5% of the cases on our dataset and DuReader, respectively.
Tool Learning with Foundation Models
Apr 17, 2023Humans possess an extraordinary ability to create and utilize tools, allowing them to overcome physical limitations and explore new frontiers. With the advent of foundation models, AI systems have the potential to be equally adept in tool use as humans. This paradigm, i.e., tool learning with foundation models, combines the strengths of specialized tools and foundation models to achieve enhanced accuracy, efficiency, and automation in problem-solving. Despite its immense potential, there is still a lack of a comprehensive understanding of key challenges, opportunities, and future endeavors in this field. To this end, we present a systematic investigation of tool learning in this paper. We first introduce the background of tool learning, including its cognitive origins, the paradigm shift of foundation models, and the complementary roles of tools and models. Then we recapitulate existing tool learning research into tool-augmented and tool-oriented learning. We formulate a general tool learning framework: starting from understanding the user instruction, models should learn to decompose a complex task into several subtasks, dynamically adjust their plan through reasoning, and effectively conquer each sub-task by selecting appropriate tools. We also discuss how to train models for improved tool-use capabilities and facilitate the generalization in tool learning. Considering the lack of a systematic tool learning evaluation in prior works, we experiment with 17 representative tools and show the potential of current foundation models in skillfully utilizing tools. Finally, we discuss several open problems that require further investigation for tool learning. Overall, we hope this paper could inspire future research in integrating tools with foundation models.