 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScale-Adaptive Power Flow Analysis with Local Topology Slicing and Multi-Task Graph Learning
Jan 04, 2026Developing deep learning models with strong adaptability to topological variations is of great practical significance for power flow analysis. To enhance model performance under variable system scales and improve robustness in branch power prediction, this paper proposes a Scale-adaptive Multi-task Power Flow Analysis (SaMPFA) framework. SaMPFA introduces a Local Topology Slicing (LTS) sampling technique that extracts subgraphs of different scales from the complete power network to strengthen the model's cross-scale learning capability. Furthermore, a Reference-free Multi-task Graph Learning (RMGL) model is designed for robust power flow prediction. Unlike existing approaches, RMGL predicts bus voltages and branch powers instead of phase angles. This design not only avoids the risk of error amplification in branch power calculation but also guides the model to learn the physical relationships of phase angle differences. In addition, the loss function incorporates extra terms that encourage the model to capture the physical patterns of angle differences and power transmission, further improving consistency between predictions and physical laws. Simulations on the IEEE 39-bus system and a real provincial grid in China demonstrate that the proposed model achieves superior adaptability and generalization under variable system scales, with accuracy improvements of 4.47% and 36.82%, respectively.
WebCPM: Interactive Web Search for Chinese Long-form Question Answering
May 23, 2023

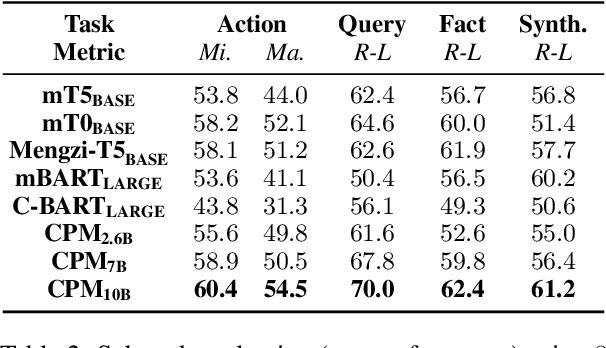

Long-form question answering (LFQA) aims at answering complex, open-ended questions with detailed, paragraph-length responses. The de facto paradigm of LFQA necessitates two procedures: information retrieval, which searches for relevant supporting facts, and information synthesis, which integrates these facts into a coherent answer. In this paper, we introduce WebCPM, the first Chinese LFQA dataset. One unique feature of WebCPM is that its information retrieval is based on interactive web search, which engages with a search engine in real time. Following WebGPT, we develop a web search interface. We recruit annotators to search for relevant information using our interface and then answer questions. Meanwhile, the web search behaviors of our annotators would be recorded. In total, we collect 5,500 high-quality question-answer pairs, together with 14,315 supporting facts and 121,330 web search actions. We fine-tune pre-trained language models to imitate human behaviors for web search and to generate answers based on the collected facts. Our LFQA pipeline, built on these fine-tuned models, generates answers that are no worse than human-written ones in 32.5% and 47.5% of the cases on our dataset and DuReader, respectively.