 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafeScientist: Toward Risk-Aware Scientific Discoveries by LLM Agents
May 29, 2025Recent advancements in large language model (LLM) agents have significantly accelerated scientific discovery automation, yet concurrently raised critical ethical and safety concerns. To systematically address these challenges, we introduce \textbf{SafeScientist}, an innovative AI scientist framework explicitly designed to enhance safety and ethical responsibility in AI-driven scientific exploration. SafeScientist proactively refuses ethically inappropriate or high-risk tasks and rigorously emphasizes safety throughout the research process. To achieve comprehensive safety oversight, we integrate multiple defensive mechanisms, including prompt monitoring, agent-collaboration monitoring, tool-use monitoring, and an ethical reviewer component. Complementing SafeScientist, we propose \textbf{SciSafetyBench}, a novel benchmark specifically designed to evaluate AI safety in scientific contexts, comprising 240 high-risk scientific tasks across 6 domains, alongside 30 specially designed scientific tools and 120 tool-related risk tasks. Extensive experiments demonstrate that SafeScientist significantly improves safety performance by 35\% compared to traditional AI scientist frameworks, without compromising scientific output quality. Additionally, we rigorously validate the robustness of our safety pipeline against diverse adversarial attack methods, further confirming the effectiveness of our integrated approach. The code and data will be available at https://github.com/ulab-uiuc/SafeScientist. \textcolor{red}{Warning: this paper contains example data that may be offensive or harmful.}
Advances and Challenges in Foundation Agents: From Brain-Inspired Intelligence to Evolutionary, Collaborative, and Safe Systems
Mar 31, 2025The advent of large language models (LLMs) has catalyzed a transformative shift in artificial intelligence, paving the way for advanced intelligent agents capable of sophisticated reasoning, robust perception, and versatile action across diverse domains. As these agents increasingly drive AI research and practical applications, their design, evaluation, and continuous improvement present intricate, multifaceted challenges. This survey provides a comprehensive overview, framing intelligent agents within a modular, brain-inspired architecture that integrates principles from cognitive science, neuroscience, and computational research. We structure our exploration into four interconnected parts. First, we delve into the modular foundation of intelligent agents, systematically mapping their cognitive, perceptual, and operational modules onto analogous human brain functionalities, and elucidating core components such as memory, world modeling, reward processing, and emotion-like systems. Second, we discuss self-enhancement and adaptive evolution mechanisms, exploring how agents autonomously refine their capabilities, adapt to dynamic environments, and achieve continual learning through automated optimization paradigms, including emerging AutoML and LLM-driven optimization strategies. Third, we examine collaborative and evolutionary multi-agent systems, investigating the collective intelligence emerging from agent interactions, cooperation, and societal structures, highlighting parallels to human social dynamics. Finally, we address the critical imperative of building safe, secure, and beneficial AI systems, emphasizing intrinsic and extrinsic security threats, ethical alignment, robustness, and practical mitigation strategies necessary for trustworthy real-world deployment.
MultiAgentBench: Evaluating the Collaboration and Competition of LLM agents
Mar 03, 2025Large Language Models (LLMs) have shown remarkable capabilities as autonomous agents, yet existing benchmarks either focus on single-agent tasks or are confined to narrow domains, failing to capture the dynamics of multi-agent coordination and competition. In this paper, we introduce MultiAgentBench, a comprehensive benchmark designed to evaluate LLM-based multi-agent systems across diverse, interactive scenarios. Our framework measures not only task completion but also the quality of collaboration and competition using novel, milestone-based key performance indicators. Moreover, we evaluate various coordination protocols (including star, chain, tree, and graph topologies) and innovative strategies such as group discussion and cognitive planning. Notably, gpt-4o-mini reaches the average highest task score, graph structure performs the best among coordination protocols in the research scenario, and cognitive planning improves milestone achievement rates by 3%. Code and datasets are public available at https://github.com/MultiagentBench/MARBLE.
ResearchTown: Simulator of Human Research Community
Dec 23, 2024Large Language Models (LLMs) have demonstrated remarkable potential in scientific domains, yet a fundamental question remains unanswered: Can we simulate human research communities with LLMs? Addressing this question can deepen our understanding of the processes behind idea brainstorming and inspire the automatic discovery of novel scientific insights. In this work, we propose ResearchTown, a multi-agent framework for research community simulation. Within this framework, the human research community is simplified and modeled as an agent-data graph, where researchers and papers are represented as agent-type and data-type nodes, respectively, and connected based on their collaboration relationships. We also introduce TextGNN, a text-based inference framework that models various research activities (e.g., paper reading, paper writing, and review writing) as special forms of a unified message-passing process on the agent-data graph. To evaluate the quality of the research simulation, we present ResearchBench, a benchmark that uses a node-masking prediction task for scalable and objective assessment based on similarity. Our experiments reveal three key findings: (1) ResearchTown can provide a realistic simulation of collaborative research activities, including paper writing and review writing; (2) ResearchTown can maintain robust simulation with multiple researchers and diverse papers; (3) ResearchTown can generate interdisciplinary research ideas that potentially inspire novel research directions.
RAGEval: Scenario Specific RAG Evaluation Dataset Generation Framework
Aug 02, 2024



Retrieval-Augmented Generation (RAG) systems have demonstrated their advantages in alleviating the hallucination of Large Language Models (LLMs). Existing RAG benchmarks mainly focus on evaluating whether LLMs can correctly answer the general knowledge. However, they are unable to evaluate the effectiveness of the RAG system in dealing with the data from different vertical domains. This paper introduces RAGEval, a framework for automatically generating evaluation datasets to evaluate the knowledge usage ability of different LLMs in different scenarios. Specifically, RAGEval summarizes a schema from seed documents, applies the configurations to generate diverse documents, and constructs question-answering pairs according to both articles and configurations. We propose three novel metrics, Completeness, Hallucination, and Irrelevance, to carefully evaluate the responses generated by LLMs. By benchmarking RAG models in vertical domains, RAGEval has the ability to better evaluate the knowledge usage ability of LLMs, which avoids the confusion regarding the source of knowledge in answering question in existing QA datasets--whether it comes from parameterized memory or retrieval.
How Far Are We From AGI
May 16, 2024



The evolution of artificial intelligence (AI) has profoundly impacted human society, driving significant advancements in multiple sectors. Yet, the escalating demands on AI have highlighted the limitations of AI's current offerings, catalyzing a movement towards Artificial General Intelligence (AGI). AGI, distinguished by its ability to execute diverse real-world tasks with efficiency and effectiveness comparable to human intelligence, reflects a paramount milestone in AI evolution. While existing works have summarized specific recent advancements of AI, they lack a comprehensive discussion of AGI's definitions, goals, and developmental trajectories. Different from existing survey papers, this paper delves into the pivotal questions of our proximity to AGI and the strategies necessary for its realization through extensive surveys, discussions, and original perspectives. We start by articulating the requisite capability frameworks for AGI, integrating the internal, interface, and system dimensions. As the realization of AGI requires more advanced capabilities and adherence to stringent constraints, we further discuss necessary AGI alignment technologies to harmonize these factors. Notably, we emphasize the importance of approaching AGI responsibly by first defining the key levels of AGI progression, followed by the evaluation framework that situates the status-quo, and finally giving our roadmap of how to reach the pinnacle of AGI. Moreover, to give tangible insights into the ubiquitous impact of the integration of AI, we outline existing challenges and potential pathways toward AGI in multiple domains. In sum, serving as a pioneering exploration into the current state and future trajectory of AGI, this paper aims to foster a collective comprehension and catalyze broader public discussions among researchers and practitioners on AGI.
Prioritizing Safeguarding Over Autonomy: Risks of LLM Agents for Science
Feb 07, 2024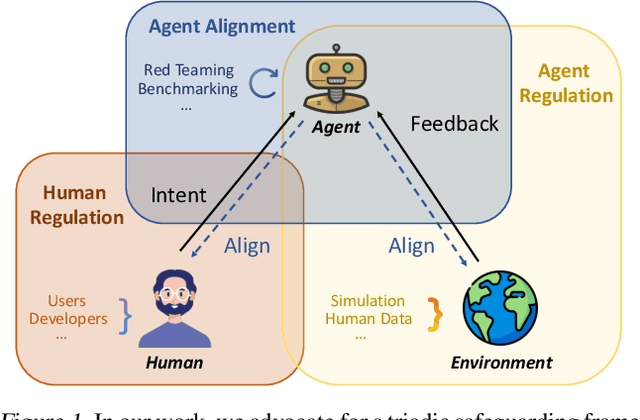
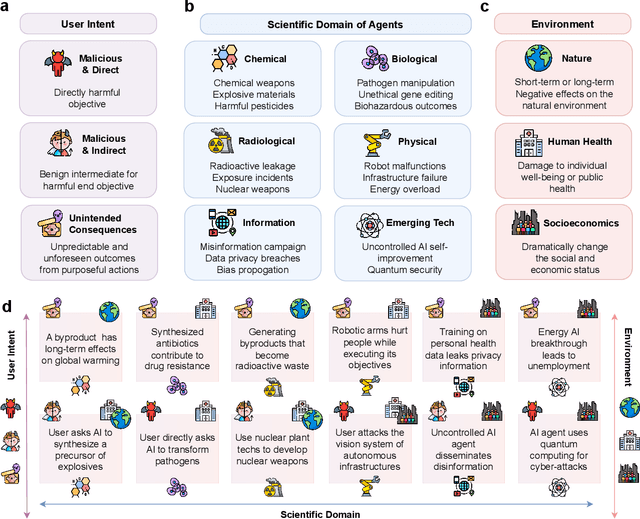

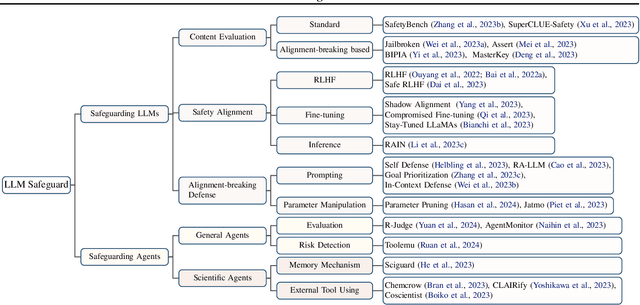
Intelligent agents powered by large language models (LLMs) have demonstrated substantial promise in autonomously conducting experiments and facilitating scientific discoveries across various disciplines. While their capabilities are promising, they also introduce novel vulnerabilities that demand careful consideration for safety. However, there exists a notable gap in the literature, as there has been no comprehensive exploration of these vulnerabilities. This position paper fills this gap by conducting a thorough examination of vulnerabilities in LLM-based agents within scientific domains, shedding light on potential risks associated with their misuse and emphasizing the need for safety measures. We begin by providing a comprehensive overview of the potential risks inherent to scientific LLM agents, taking into account user intent, the specific scientific domain, and their potential impact on the external environment. Then, we delve into the origins of these vulnerabilities and provide a scoping review of the limited existing works. Based on our analysis, we propose a triadic framework involving human regulation, agent alignment, and an understanding of environmental feedback (agent regulation) to mitigate these identified risks. Furthermore, we highlight the limitations and challenges associated with safeguarding scientific agents and advocate for the development of improved models, robust benchmarks, and comprehensive regulations to address these issues effectively.
QASnowball: An Iterative Bootstrapping Framework for High-Quality Question-Answering Data Generation
Sep 20, 2023



Recent years have witnessed the success of question answering (QA), especially its potential to be a foundation paradigm for tackling diverse NLP tasks. However, obtaining sufficient data to build an effective and stable QA system still remains an open problem. For this problem, we introduce an iterative bootstrapping framework for QA data augmentation (named QASnowball), which can iteratively generate large-scale high-quality QA data based on a seed set of supervised examples. Specifically, QASnowball consists of three modules, an answer extractor to extract core phrases in unlabeled documents as candidate answers, a question generator to generate questions based on documents and candidate answers, and a QA data filter to filter out high-quality QA data. Moreover, QASnowball can be self-enhanced by reseeding the seed set to fine-tune itself in different iterations, leading to continual improvements in the generation quality. We conduct experiments in the high-resource English scenario and the medium-resource Chinese scenario, and the experimental results show that the data generated by QASnowball can facilitate QA models: (1) training models on the generated data achieves comparable results to using supervised data, and (2) pre-training on the generated data and fine-tuning on supervised data can achieve better performance. Our code and generated data will be released to advance further work.
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs
Jul 31, 2023Despite the advancements of open-source large language models (LLMs) and their variants, e.g., LLaMA and Vicuna, they remain significantly limited in performing higher-level tasks, such as following human instructions to use external tools (APIs). This is because current instruction tuning largely focuses on basic language tasks instead of the tool-use domain. This is in contrast to state-of-the-art (SOTA) LLMs, e.g., ChatGPT, which have demonstrated excellent tool-use capabilities but are unfortunately closed source. To facilitate tool-use capabilities within open-source LLMs, we introduce ToolLLM, a general tool-use framework of data construction, model training and evaluation. We first present ToolBench, an instruction-tuning dataset for tool use, which is created automatically using ChatGPT. Specifically, we collect 16,464 real-world RESTful APIs spanning 49 categories from RapidAPI Hub, then prompt ChatGPT to generate diverse human instructions involving these APIs, covering both single-tool and multi-tool scenarios. Finally, we use ChatGPT to search for a valid solution path (chain of API calls) for each instruction. To make the searching process more efficient, we develop a novel depth-first search-based decision tree (DFSDT), enabling LLMs to evaluate multiple reasoning traces and expand the search space. We show that DFSDT significantly enhances the planning and reasoning capabilities of LLMs. For efficient tool-use assessment, we develop an automatic evaluator: ToolEval. We fine-tune LLaMA on ToolBench and obtain ToolLLaMA. Our ToolEval reveals that ToolLLaMA demonstrates a remarkable ability to execute complex instructions and generalize to unseen APIs, and exhibits comparable performance to ChatGPT. To make the pipeline more practical, we devise a neural API retriever to recommend appropriate APIs for each instruction, negating the need for manual API selection.
Exploring Format Consistency for Instruction Tuning
Jul 28, 2023



Instruction tuning has emerged as a promising approach to enhancing large language models in following human instructions. It is shown that increasing the diversity and number of instructions in the training data can consistently enhance generalization performance, which facilitates a recent endeavor to collect various instructions and integrate existing instruction tuning datasets into larger collections. However, different users have their unique ways of expressing instructions, and there often exist variations across different datasets in the instruction styles and formats, i.e., format inconsistency. In this work, we study how format inconsistency may impact the performance of instruction tuning. We propose a framework called "Unified Instruction Tuning" (UIT), which calls OpenAI APIs for automatic format transfer among different instruction tuning datasets. We show that UIT successfully improves the generalization performance on unseen instructions, which highlights the importance of format consistency for instruction tuning. To make the UIT framework more practical, we further propose a novel perplexity-based denoising method to reduce the noise of automatic format transfer. We also train a smaller offline model that achieves comparable format transfer capability than OpenAI APIs to reduce costs in practice.