 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAtomMem : Learnable Dynamic Agentic Memory with Atomic Memory Operation
Jan 13, 2026Equipping agents with memory is essential for solving real-world long-horizon problems. However, most existing agent memory mechanisms rely on static and hand-crafted workflows. This limits the performance and generalization ability of these memory designs, which highlights the need for a more flexible, learning-based memory framework. In this paper, we propose AtomMem, which reframes memory management as a dynamic decision-making problem. We deconstruct high-level memory processes into fundamental atomic CRUD (Create, Read, Update, Delete) operations, transforming the memory workflow into a learnable decision process. By combining supervised fine-tuning with reinforcement learning, AtomMem learns an autonomous, task-aligned policy to orchestrate memory behaviors tailored to specific task demands. Experimental results across 3 long-context benchmarks demonstrate that the trained AtomMem-8B consistently outperforms prior static-workflow memory methods. Further analysis of training dynamics shows that our learning-based formulation enables the agent to discover structured, task-aligned memory management strategies, highlighting a key advantage over predefined routines.
MiniCPM4: Ultra-Efficient LLMs on End Devices
Jun 09, 2025



This paper introduces MiniCPM4, a highly efficient large language model (LLM) designed explicitly for end-side devices. We achieve this efficiency through systematic innovation in four key dimensions: model architecture, training data, training algorithms, and inference systems. Specifically, in terms of model architecture, we propose InfLLM v2, a trainable sparse attention mechanism that accelerates both prefilling and decoding phases for long-context processing. Regarding training data, we propose UltraClean, an efficient and accurate pre-training data filtering and generation strategy, and UltraChat v2, a comprehensive supervised fine-tuning dataset. These datasets enable satisfactory model performance to be achieved using just 8 trillion training tokens. Regarding training algorithms, we propose ModelTunnel v2 for efficient pre-training strategy search, and improve existing post-training methods by introducing chunk-wise rollout for load-balanced reinforcement learning and data-efficient tenary LLM, BitCPM. Regarding inference systems, we propose CPM.cu that integrates sparse attention, model quantization, and speculative sampling to achieve efficient prefilling and decoding. To meet diverse on-device requirements, MiniCPM4 is available in two versions, with 0.5B and 8B parameters, respectively. Sufficient evaluation results show that MiniCPM4 outperforms open-source models of similar size across multiple benchmarks, highlighting both its efficiency and effectiveness. Notably, MiniCPM4-8B demonstrates significant speed improvements over Qwen3-8B when processing long sequences. Through further adaptation, MiniCPM4 successfully powers diverse applications, including trustworthy survey generation and tool use with model context protocol, clearly showcasing its broad usability.
ToLeaP: Rethinking Development of Tool Learning with Large Language Models
May 17, 2025
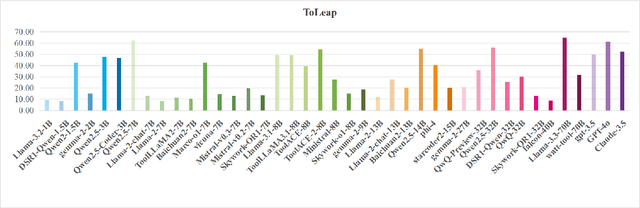
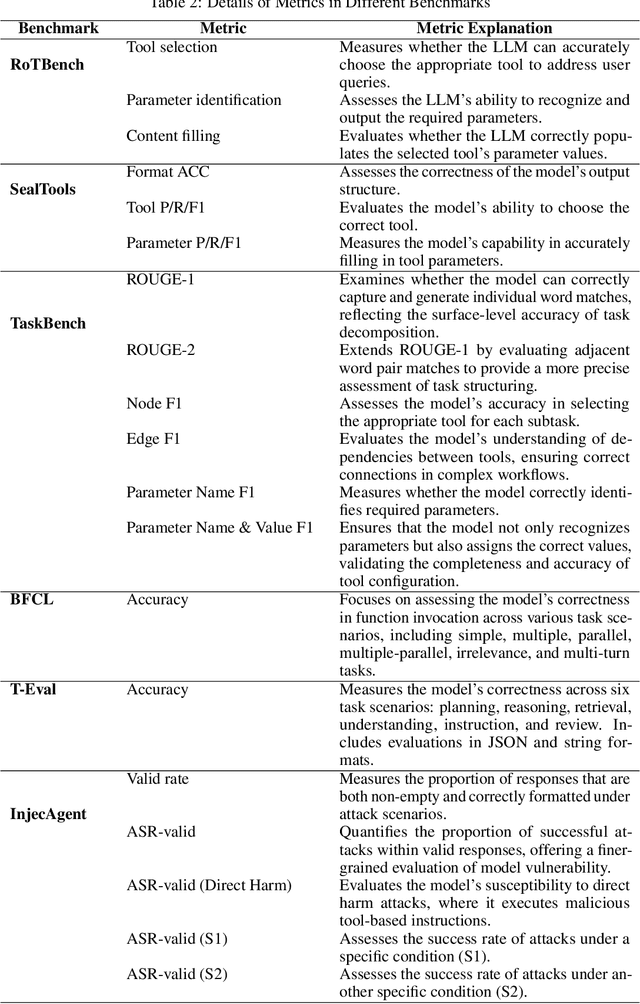
Tool learning, which enables large language models (LLMs) to utilize external tools effectively, has garnered increasing attention for its potential to revolutionize productivity across industries. Despite rapid development in tool learning, key challenges and opportunities remain understudied, limiting deeper insights and future advancements. In this paper, we investigate the tool learning ability of 41 prevalent LLMs by reproducing 33 benchmarks and enabling one-click evaluation for seven of them, forming a Tool Learning Platform named ToLeaP. We also collect 21 out of 33 potential training datasets to facilitate future exploration. After analyzing over 3,000 bad cases of 41 LLMs based on ToLeaP, we identify four main critical challenges: (1) benchmark limitations induce both the neglect and lack of (2) autonomous learning, (3) generalization, and (4) long-horizon task-solving capabilities of LLMs. To aid future advancements, we take a step further toward exploring potential directions, namely (1) real-world benchmark construction, (2) compatibility-aware autonomous learning, (3) rationale learning by thinking, and (4) identifying and recalling key clues. The preliminary experiments demonstrate their effectiveness, highlighting the need for further research and exploration.
Learning to Generate Structured Output with Schema Reinforcement Learning
Feb 26, 2025This study investigates the structured generation capabilities of large language models (LLMs), focusing on producing valid JSON outputs against a given schema. Despite the widespread use of JSON in integrating language models with programs, there is a lack of comprehensive analysis and benchmarking of these capabilities. We explore various aspects of JSON generation, such as structure understanding, escaping, and natural language description, to determine how to assess and enable LLMs to generate valid responses. Building upon this, we propose SchemaBench features around 40K different JSON schemas to obtain and assess models' abilities in generating valid JSON. We find that the latest LLMs are still struggling to generate a valid JSON string. Moreover, we demonstrate that incorporating reinforcement learning with a Fine-grained Schema Validator can further enhance models' understanding of JSON schema, leading to improved performance. Our models demonstrate significant improvement in both generating JSON outputs and downstream tasks.
AgentRM: Enhancing Agent Generalization with Reward Modeling
Feb 25, 2025Existing LLM-based agents have achieved strong performance on held-in tasks, but their generalizability to unseen tasks remains poor. Hence, some recent work focus on fine-tuning the policy model with more diverse tasks to improve the generalizability. In this work, we find that finetuning a reward model to guide the policy model is more robust than directly finetuning the policy model. Based on this finding, we propose AgentRM, a generalizable reward model, to guide the policy model for effective test-time search. We comprehensively investigate three approaches to construct the reward model, including explicit reward modeling, implicit reward modeling and LLM-as-a-judge. We then use AgentRM to guide the answer generation with Best-of-N sampling and step-level beam search. On four types of nine agent tasks, AgentRM enhances the base policy model by $8.8$ points on average, surpassing the top general agent by $4.0$. Moreover, it demonstrates weak-to-strong generalization, yielding greater improvement of $12.6$ on LLaMA-3-70B policy model. As for the specializability, AgentRM can also boost a finetuned policy model and outperform the top specialized agent by $11.4$ on three held-in tasks. Further analysis verifies its effectiveness in test-time scaling. Codes will be released to facilitate the research in this area.
Proactive Agent: Shifting LLM Agents from Reactive Responses to Active Assistance
Oct 16, 2024



Agents powered by large language models have shown remarkable abilities in solving complex tasks. However, most agent systems remain reactive, limiting their effectiveness in scenarios requiring foresight and autonomous decision-making. In this paper, we tackle the challenge of developing proactive agents capable of anticipating and initiating tasks without explicit human instructions. We propose a novel data-driven approach for this problem. Firstly, we collect real-world human activities to generate proactive task predictions. These predictions are then labeled by human annotators as either accepted or rejected. The labeled data is used to train a reward model that simulates human judgment and serves as an automatic evaluator of the proactiveness of LLM agents. Building on this, we develop a comprehensive data generation pipeline to create a diverse dataset, ProactiveBench, containing 6,790 events. Finally, we demonstrate that fine-tuning models with the proposed ProactiveBench can significantly elicit the proactiveness of LLM agents. Experimental results show that our fine-tuned model achieves an F1-Score of 66.47% in proactively offering assistance, outperforming all open-source and close-source models. These results highlight the potential of our method in creating more proactive and effective agent systems, paving the way for future advancements in human-agent collaboration.
RepoAgent: An LLM-Powered Open-Source Framework for Repository-level Code Documentation Generation
Feb 26, 2024
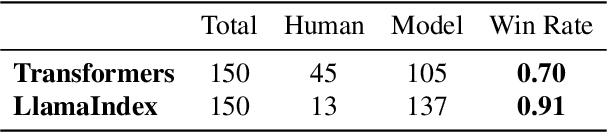
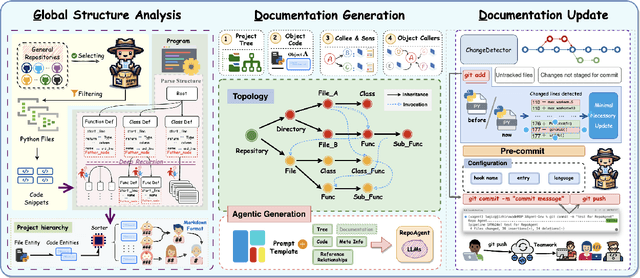
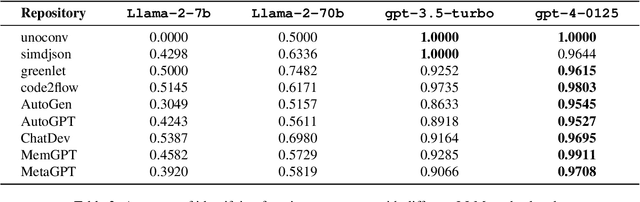
Generative models have demonstrated considerable potential in software engineering, particularly in tasks such as code generation and debugging. However, their utilization in the domain of code documentation generation remains underexplored. To this end, we introduce RepoAgent, a large language model powered open-source framework aimed at proactively generating, maintaining, and updating code documentation. Through both qualitative and quantitative evaluations, we have validated the effectiveness of our approach, showing that RepoAgent excels in generating high-quality repository-level documentation. The code and results are publicly accessible at https://github.com/OpenBMB/RepoAgent.
GitAgent: Facilitating Autonomous Agent with GitHub by Tool Extension
Dec 28, 2023While Large Language Models (LLMs) like ChatGPT and GPT-4 have demonstrated exceptional proficiency in natural language processing, their efficacy in addressing complex, multifaceted tasks remains limited. A growing area of research focuses on LLM-based agents equipped with external tools capable of performing diverse tasks. However, existing LLM-based agents only support a limited set of tools which is unable to cover a diverse range of user queries, especially for those involving expertise domains. It remains a challenge for LLM-based agents to extend their tools autonomously when confronted with various user queries. As GitHub has hosted a multitude of repositories which can be seen as a good resource for tools, a promising solution is that LLM-based agents can autonomously integrate the repositories in GitHub according to the user queries to extend their tool set. In this paper, we introduce GitAgent, an agent capable of achieving the autonomous tool extension from GitHub. GitAgent follows a four-phase procedure to incorporate repositories and it can learn human experience by resorting to GitHub Issues/PRs to solve problems encountered during the procedure. Experimental evaluation involving 30 user queries demonstrates GitAgent's effectiveness, achieving a 69.4% success rate on average.
ProAgent: From Robotic Process Automation to Agentic Process Automation
Nov 02, 2023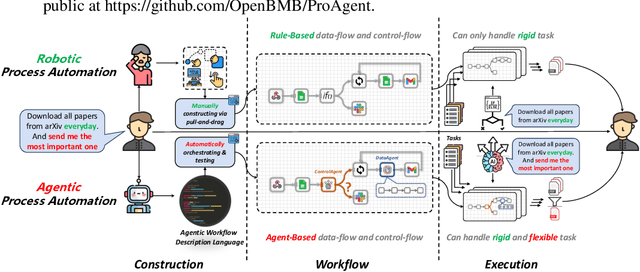
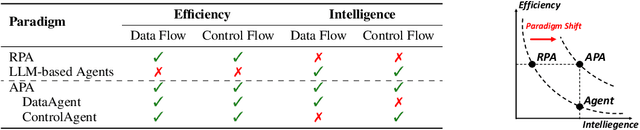
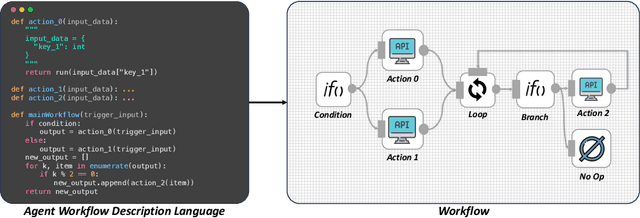
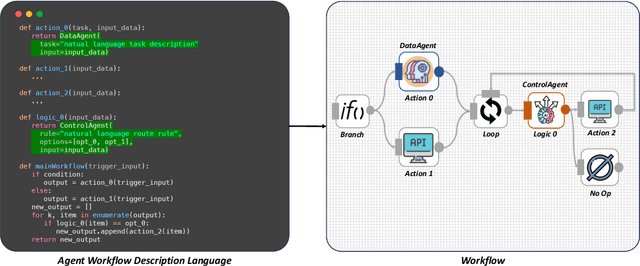
From ancient water wheels to robotic process automation (RPA), automation technology has evolved throughout history to liberate human beings from arduous tasks. Yet, RPA struggles with tasks needing human-like intelligence, especially in elaborate design of workflow construction and dynamic decision-making in workflow execution. As Large Language Models (LLMs) have emerged human-like intelligence, this paper introduces Agentic Process Automation (APA), a groundbreaking automation paradigm using LLM-based agents for advanced automation by offloading the human labor to agents associated with construction and execution. We then instantiate ProAgent, an LLM-based agent designed to craft workflows from human instructions and make intricate decisions by coordinating specialized agents. Empirical experiments are conducted to detail its construction and execution procedure of workflow, showcasing the feasibility of APA, unveiling the possibility of a new paradigm of automation driven by agents. Our code is public at https://github.com/OpenBMB/ProAgent.
AgentVerse: Facilitating Multi-Agent Collaboration and Exploring Emergent Behaviors in Agents
Aug 21, 2023



Autonomous agents empowered by Large Language Models (LLMs) have undergone significant improvements, enabling them to generalize across a broad spectrum of tasks. However, in real-world scenarios, cooperation among individuals is often required to enhance the efficiency and effectiveness of task accomplishment. Hence, inspired by human group dynamics, we propose a multi-agent framework \framework that can collaboratively and dynamically adjust its composition as a greater-than-the-sum-of-its-parts system. Our experiments demonstrate that \framework framework can effectively deploy multi-agent groups that outperform a single agent. Furthermore, we delve into the emergence of social behaviors among individual agents within a group during collaborative task accomplishment. In view of these behaviors, we discuss some possible strategies to leverage positive ones and mitigate negative ones for improving the collaborative potential of multi-agent groups. Our codes for \framework will soon be released at \url{https://github.com/OpenBMB/AgentVerse}.