 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNot Just the Destination, But the Journey: Reasoning Traces Causally Shape Generalization Behaviors
Mar 12, 2026Chain-of-Thought (CoT) is often viewed as a window into LLM decision-making, yet recent work suggests it may function merely as post-hoc rationalization. This raises a critical alignment question: Does the reasoning trace causally shape model generalization independent of the final answer? To isolate reasoning's causal effect, we design a controlled experiment holding final harmful answers constant while varying reasoning paths. We construct datasets with \textit{Evil} reasoning embracing malice, \textit{Misleading} reasoning rationalizing harm, and \textit{Submissive} reasoning yielding to pressure. We train models (0.6B--14B parameters) under multiple paradigms, including question-thinking-answer (QTA), question-thinking (QT), and thinking-only (T-only), and evaluate them in both think and no-think modes. We find that: (1) CoT training could amplify harmful generalization more than standard fine-tuning; (2) distinct reasoning types induce distinct behavioral patterns aligned with their semantics, despite identical final answers; (3) training on reasoning without answer supervision (QT or T-only) is sufficient to alter behavior, proving reasoning carries an independent signal; and (4) these effects persist even when generating answers without reasoning, indicating deep internalization. Our findings demonstrate that reasoning content is causally potent, challenging alignment strategies that supervise only outputs.
DC-W2S: Dual-Consensus Weak-to-Strong Training for Reliable Process Reward Modeling in Biological Reasoning
Mar 09, 2026In scientific reasoning tasks, the veracity of the reasoning process is as critical as the final outcome. While Process Reward Models (PRMs) offer a solution to the coarse-grained supervision problems inherent in Outcome Reward Models (ORMs), their deployment is hindered by the prohibitive cost of obtaining expert-verified step-wise labels. This paper addresses the challenge of training reliable PRMs using abundant but noisy "weak" supervision. We argue that existing Weak-to-Strong Generalization (W2SG) theories lack prescriptive guidelines for selecting high-quality training signals from noisy data. To bridge this gap, we introduce the Dual-Consensus Weak-to-Strong (DC-W2S) framework. By intersecting Self-Consensus (SC) metrics among weak supervisors with Neighborhood-Consensus (NC) metrics in the embedding space, we stratify supervision signals into distinct reliability regimes. We then employ a curriculum of instance-level balanced sampling and label-level reliability-aware masking to guide the training process. We demonstrate that DC-W2S enables the training of robust PRMs for complex reasoning without exhaustive expert annotation, proving that strategic data curation is more effective than indiscriminate training on large-scale noisy datasets.
What, Whether and How? Unveiling Process Reward Models for Thinking with Images Reasoning
Feb 09, 2026The rapid advancement of Large Vision Language Models (LVLMs) has demonstrated excellent abilities in various visual tasks. Building upon these developments, the thinking with images paradigm has emerged, enabling models to dynamically edit and re-encode visual information at each reasoning step, mirroring human visual processing. However, this paradigm introduces significant challenges as diverse errors may occur during reasoning processes. This necessitates Process Reward Models (PRMs) for distinguishing positive and negative reasoning steps, yet existing benchmarks for PRMs are predominantly text-centric and lack comprehensive assessment under this paradigm. To address these gaps, this work introduces the first comprehensive benchmark specifically designed for evaluating PRMs under the thinking with images paradigm. Our main contributions are: (1) Through extensive analysis of reasoning trajectories and guided search experiments with PRMs, we define 7 fine-grained error types and demonstrate both the necessity for specialized PRMs and the potential for improvement. (2) We construct a comprehensive benchmark comprising 1,206 manually annotated thinking with images reasoning trajectories spanning 4 categories and 16 subcategories for fine-grained evaluation of PRMs. (3) Our experimental analysis reveals that current LVLMs fall short as effective PRMs, exhibiting limited capabilities in visual reasoning process evaluation with significant performance disparities across error types, positive evaluation bias, and sensitivity to reasoning step positions. These findings demonstrate the effectiveness of our benchmark and establish crucial foundations for advancing PRMs in LVLMs.
Glance-or-Gaze: Incentivizing LMMs to Adaptively Focus Search via Reinforcement Learning
Jan 20, 2026Large Multimodal Models (LMMs) have achieved remarkable success in visual understanding, yet they struggle with knowledge-intensive queries involving long-tail entities or evolving information due to static parametric knowledge. Recent search-augmented approaches attempt to address this limitation, but existing methods rely on indiscriminate whole-image retrieval that introduces substantial visual redundancy and noise, and lack deep iterative reflection, limiting their effectiveness on complex visual queries. To overcome these challenges, we propose Glance-or-Gaze (GoG), a fully autonomous framework that shifts from passive perception to active visual planning. GoG introduces a Selective Gaze mechanism that dynamically chooses whether to glance at global context or gaze into high-value regions, filtering irrelevant information before retrieval. We design a dual-stage training strategy: Reflective GoG Behavior Alignment via supervised fine-tuning instills the fundamental GoG paradigm, while Complexity-Adaptive Reinforcement Learning further enhances the model's capability to handle complex queries through iterative reasoning. Experiments across six benchmarks demonstrate state-of-the-art performance. Ablation studies confirm that both Selective Gaze and complexity-adaptive RL are essential for effective visual search. We will release our data and models for further exploration soon.
AM$^3$Safety: Towards Data Efficient Alignment of Multi-modal Multi-turn Safety for MLLMs
Jan 08, 2026Multi-modal Large Language Models (MLLMs) are increasingly deployed in interactive applications. However, their safety vulnerabilities become pronounced in multi-turn multi-modal scenarios, where harmful intent can be gradually reconstructed across turns, and security protocols fade into oblivion as the conversation progresses. Existing Reinforcement Learning from Human Feedback (RLHF) alignment methods are largely developed for single-turn visual question-answer (VQA) task and often require costly manual preference annotations, limiting their effectiveness and scalability in dialogues. To address this challenge, we present InterSafe-V, an open-source multi-modal dialogue dataset containing 11,270 dialogues and 500 specially designed refusal VQA samples. This dataset, constructed through interaction between several models, is designed to more accurately reflect real-world scenarios and includes specialized VQA pairs tailored for specific domains. Building on this dataset, we propose AM$^3$Safety, a framework that combines a cold-start refusal phase with Group Relative Policy Optimization (GRPO) fine-tuning using turn-aware dual-objective rewards across entire dialogues. Experiments on Qwen2.5-VL-7B-Instruct and LLaVA-NeXT-7B show more than 10\% decrease in Attack Success Rate (ASR) together with an increment of at least 8\% in harmless dimension and over 13\% in helpful dimension of MLLMs on multi-modal multi-turn safety benchmarks, while preserving their general abilities.
ReViSE: Towards Reason-Informed Video Editing in Unified Models with Self-Reflective Learning
Dec 11, 2025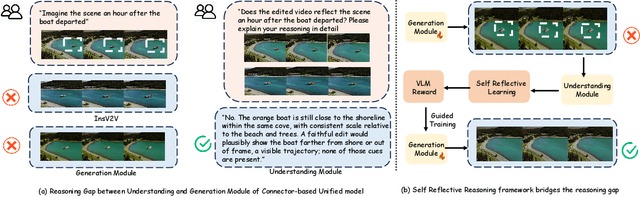
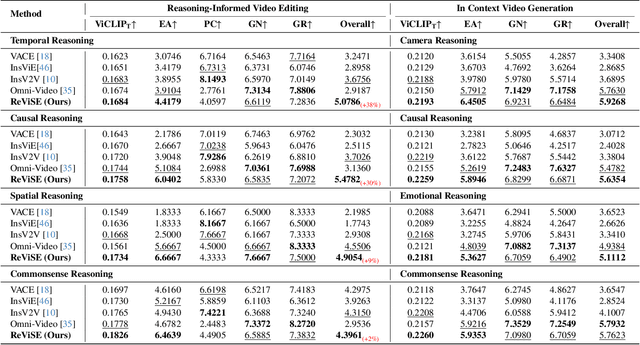

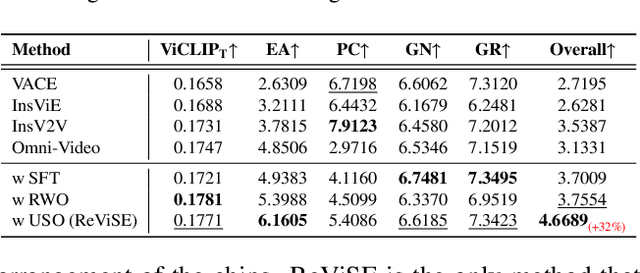
Video unified models exhibit strong capabilities in understanding and generation, yet they struggle with reason-informed visual editing even when equipped with powerful internal vision-language models (VLMs). We attribute this gap to two factors: 1) existing datasets are inadequate for training and evaluating reasoning-aware video editing, and 2) an inherent disconnect between the models' reasoning and editing capabilities, which prevents the rich understanding from effectively instructing the editing process. Bridging this gap requires an integrated framework that connects reasoning with visual transformation. To address this gap, we introduce the Reason-Informed Video Editing (RVE) task, which requires reasoning about physical plausibility and causal dynamics during editing. To support systematic evaluation, we construct RVE-Bench, a comprehensive benchmark with two complementary subsets: Reasoning-Informed Video Editing and In-Context Video Generation. These subsets cover diverse reasoning dimensions and real-world editing scenarios. Building upon this foundation, we propose the ReViSE, a Self-Reflective Reasoning (SRF) framework that unifies generation and evaluation within a single architecture. The model's internal VLM provides intrinsic feedback by assessing whether the edited video logically satisfies the given instruction. The differential feedback that refines the generator's reasoning behavior during training. Extensive experiments on RVE-Bench demonstrate that ReViSE significantly enhances editing accuracy and visual fidelity, achieving a 32% improvement of the Overall score in the reasoning-informed video editing subset over state-of-the-art methods.
The Mirage of Multimodality: Where Truth is Tested and Honesty Unravels
May 26, 2025Reasoning models have recently attracted significant attention, especially for tasks that involve complex inference. Their strengths exemplify the System II paradigm (slow, structured thinking), contrasting with the System I (rapid, heuristic-driven). Yet, does slower reasoning necessarily lead to greater truthfulness? Our findings suggest otherwise. In this study, we present the first systematic investigation of distortions associated with System I and System II reasoning in multimodal contexts. We demonstrate that slower reasoning models, when presented with incomplete or misleading visual inputs, are more likely to fabricate plausible yet false details to support flawed reasoning -- a phenomenon we term the "Mirage of Multimodality". To examine this, we constructed a 5,000-sample hierarchical prompt dataset annotated by 50 human participants. These prompts gradually increase in complexity, revealing a consistent pattern: slower reasoning models tend to employ depth-first thinking (delving deeper into incorrect premises), whereas faster chat models favor breadth-first inference, exhibiting greater caution under uncertainty. Our results highlight a critical vulnerability of slower reasoning models: although highly effective in structured domains such as mathematics, it becomes brittle when confronted with ambiguous multimodal inputs.
J1: Exploring Simple Test-Time Scaling for LLM-as-a-Judge
May 17, 2025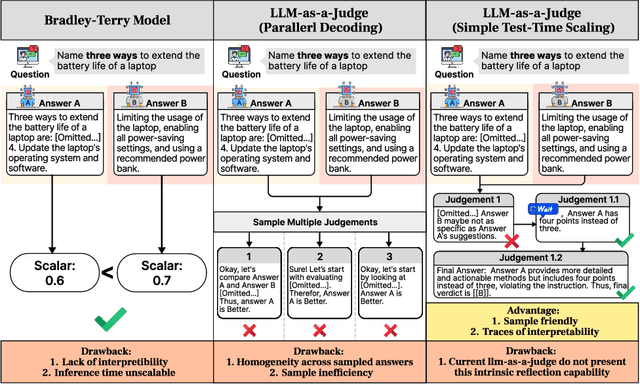
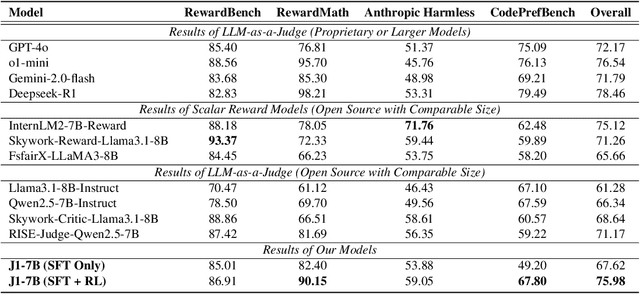
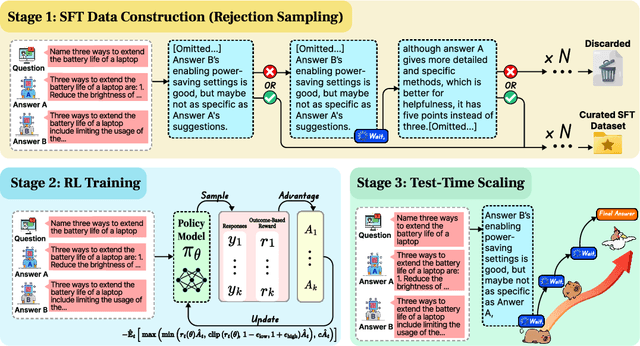
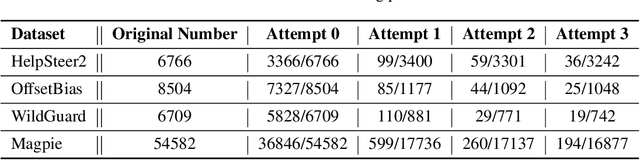
The current focus of AI research is shifting from emphasizing model training towards enhancing evaluation quality, a transition that is crucial for driving further advancements in AI systems. Traditional evaluation methods typically rely on reward models assigning scalar preference scores to outputs. Although effective, such approaches lack interpretability, leaving users often uncertain about why a reward model rates a particular response as high or low. The advent of LLM-as-a-Judge provides a more scalable and interpretable method of supervision, offering insights into the decision-making process. Moreover, with the emergence of large reasoning models, which consume more tokens for deeper thinking and answer refinement, scaling test-time computation in the LLM-as-a-Judge paradigm presents an avenue for further boosting performance and providing more interpretability through reasoning traces. In this paper, we introduce $\textbf{J1-7B}$, which is first supervised fine-tuned on reflection-enhanced datasets collected via rejection-sampling and subsequently trained using Reinforcement Learning (RL) with verifiable rewards. At inference time, we apply Simple Test-Time Scaling (STTS) strategies for additional performance improvement. Experimental results demonstrate that $\textbf{J1-7B}$ surpasses the previous state-of-the-art LLM-as-a-Judge by $ \textbf{4.8}$\% and exhibits a $ \textbf{5.1}$\% stronger scaling trend under STTS. Additionally, we present three key findings: (1) Existing LLM-as-a-Judge does not inherently exhibit such scaling trend. (2) Model simply fine-tuned on reflection-enhanced datasets continues to demonstrate similarly weak scaling behavior. (3) Significant scaling trend emerges primarily during the RL phase, suggesting that effective STTS capability is acquired predominantly through RL training.
ThinkPatterns-21k: A Systematic Study on the Impact of Thinking Patterns in LLMs
Mar 17, 2025Large language models (LLMs) have demonstrated enhanced performance through the \textit{Thinking then Responding} paradigm, where models generate internal thoughts before final responses (aka, System 2 thinking). However, existing research lacks a systematic understanding of the mechanisms underlying how thinking patterns affect performance across model sizes. In this work, we conduct a comprehensive analysis of the impact of various thinking types on model performance and introduce ThinkPatterns-21k, a curated dataset comprising 21k instruction-response pairs (QA) collected from existing instruction-following datasets with five thinking types. For each pair, we augment it with five distinct internal thinking patterns: one unstructured thinking (monologue) and four structured variants (decomposition, self-ask, self-debate and self-critic), while maintaining the same instruction and response. Through extensive evaluation across different model sizes (3B-32B parameters), we have two key findings: (1) smaller models (<30B parameters) can benefit from most of structured thinking patterns, while larger models (32B) with structured thinking like decomposition would degrade performance and (2) unstructured monologue demonstrates broad effectiveness across different model sizes. Finally, we released all of our datasets, checkpoints, training logs of diverse thinking patterns to reproducibility, aiming to facilitate further research in this direction.
Llasa: Scaling Train-Time and Inference-Time Compute for Llama-based Speech Synthesis
Feb 06, 2025Recent advances in text-based large language models (LLMs), particularly in the GPT series and the o1 model, have demonstrated the effectiveness of scaling both training-time and inference-time compute. However, current state-of-the-art TTS systems leveraging LLMs are often multi-stage, requiring separate models (e.g., diffusion models after LLM), complicating the decision of whether to scale a particular model during training or testing. This work makes the following contributions: First, we explore the scaling of train-time and inference-time compute for speech synthesis. Second, we propose a simple framework Llasa for speech synthesis that employs a single-layer vector quantizer (VQ) codec and a single Transformer architecture to fully align with standard LLMs such as Llama. Our experiments reveal that scaling train-time compute for Llasa consistently improves the naturalness of synthesized speech and enables the generation of more complex and accurate prosody patterns. Furthermore, from the perspective of scaling inference-time compute, we employ speech understanding models as verifiers during the search, finding that scaling inference-time compute shifts the sampling modes toward the preferences of specific verifiers, thereby improving emotional expressiveness, timbre consistency, and content accuracy. In addition, we released the checkpoint and training code for our TTS model (1B, 3B, 8B) and codec model publicly available.