 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControllable Coupled Image Generation via Diffusion Models
Jun 07, 2025We provide an attention-level control method for the task of coupled image generation, where "coupled" means that multiple simultaneously generated images are expected to have the same or very similar backgrounds. While backgrounds coupled, the centered objects in the generated images are still expected to enjoy the flexibility raised from different text prompts. The proposed method disentangles the background and entity components in the model's cross-attention modules, attached with a sequence of time-varying weight control parameters depending on the time step of sampling. We optimize this sequence of weight control parameters with a combined objective that assesses how coupled the backgrounds are as well as text-to-image alignment and overall visual quality. Empirical results demonstrate that our method outperforms existing approaches across these criteria.
Improving LLM Interpretability and Performance via Guided Embedding Refinement for Sequential Recommendation
Apr 15, 2025



The fast development of Large Language Models (LLMs) offers growing opportunities to further improve sequential recommendation systems. Yet for some practitioners, integrating LLMs to their existing base recommendation systems raises questions about model interpretability, transparency and related safety. To partly alleviate challenges from these questions, we propose guided embedding refinement, a method that carries out a guided and interpretable usage of LLM to enhance the embeddings associated with the base recommendation system. Instead of directly using LLMs as the backbone of sequential recommendation systems, we utilize them as auxiliary tools to emulate the sales logic of recommendation and generate guided embeddings that capture domain-relevant semantic information on interpretable attributes. Benefiting from the strong generalization capabilities of the guided embedding, we construct refined embedding by using the guided embedding and reduced-dimension version of the base embedding. We then integrate the refined embedding into the recommendation module for training and inference. A range of numerical experiments demonstrate that guided embedding is adaptable to various given existing base embedding models, and generalizes well across different recommendation tasks. The numerical results show that the refined embedding not only improves recommendation performance, achieving approximately $10\%$ to $50\%$ gains in Mean Reciprocal Rank (MRR), Recall rate, and Normalized Discounted Cumulative Gain (NDCG), but also enhances interpretability, as evidenced by case studies.
Literature Meets Data: A Synergistic Approach to Hypothesis Generation
Oct 22, 2024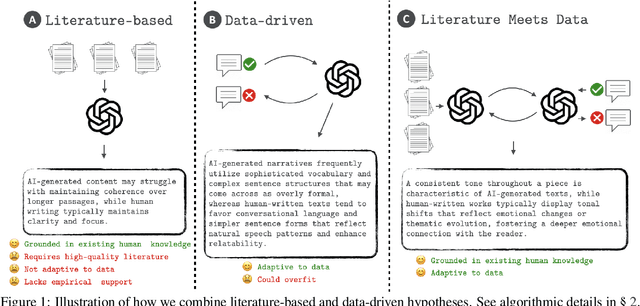
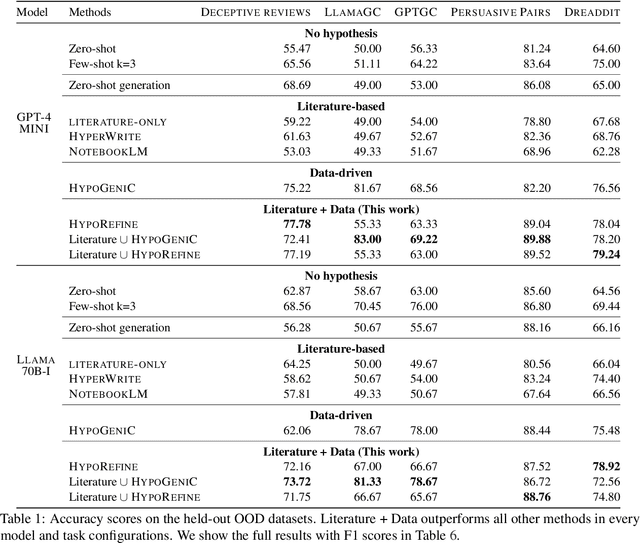
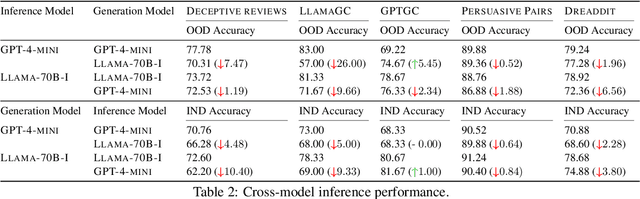
AI holds promise for transforming scientific processes, including hypothesis generation. Prior work on hypothesis generation can be broadly categorized into theory-driven and data-driven approaches. While both have proven effective in generating novel and plausible hypotheses, it remains an open question whether they can complement each other. To address this, we develop the first method that combines literature-based insights with data to perform LLM-powered hypothesis generation. We apply our method on five different datasets and demonstrate that integrating literature and data outperforms other baselines (8.97\% over few-shot, 15.75\% over literature-based alone, and 3.37\% over data-driven alone). Additionally, we conduct the first human evaluation to assess the utility of LLM-generated hypotheses in assisting human decision-making on two challenging tasks: deception detection and AI generated content detection. Our results show that human accuracy improves significantly by 7.44\% and 14.19\% on these tasks, respectively. These findings suggest that integrating literature-based and data-driven approaches provides a comprehensive and nuanced framework for hypothesis generation and could open new avenues for scientific inquiry.
Beyond Natural Language: LLMs Leveraging Alternative Formats for Enhanced Reasoning and Communication
Feb 28, 2024
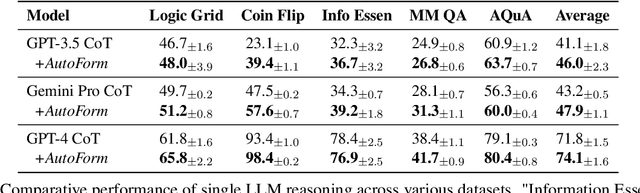

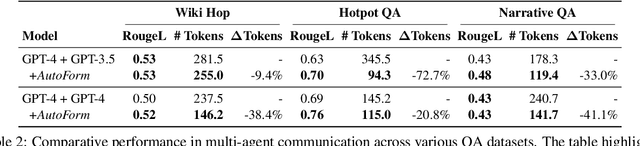
Natural language (NL) has long been the predominant format for human cognition and communication, and by extension, has been similarly pivotal in the development and application of Large Language Models (LLMs). Yet, besides NL, LLMs have seen various non-NL formats during pre-training, such as code and logical expression. NL's status as the optimal format for LLMs, particularly in single-LLM reasoning and multi-agent communication, has not been thoroughly examined. In this work, we challenge the default use of NL by exploring the utility of non-NL formats in these contexts. We show that allowing LLMs to autonomously select the most suitable format before reasoning or communicating leads to a 3.3 to 5.7\% improvement in reasoning efficiency for different LLMs, and up to a 72.7\% reduction in token usage in multi-agent communication, all while maintaining communicative effectiveness. Our comprehensive analysis further reveals that LLMs can devise a format from limited task instructions and that the devised format is effectively transferable across different LLMs. Intriguingly, the structured communication format decided by LLMs exhibits notable parallels with established agent communication languages, suggesting a natural evolution towards efficient, structured communication in agent communication. Our code is released at \url{https://github.com/thunlp/AutoForm}.
AgentVerse: Facilitating Multi-Agent Collaboration and Exploring Emergent Behaviors in Agents
Aug 21, 2023



Autonomous agents empowered by Large Language Models (LLMs) have undergone significant improvements, enabling them to generalize across a broad spectrum of tasks. However, in real-world scenarios, cooperation among individuals is often required to enhance the efficiency and effectiveness of task accomplishment. Hence, inspired by human group dynamics, we propose a multi-agent framework \framework that can collaboratively and dynamically adjust its composition as a greater-than-the-sum-of-its-parts system. Our experiments demonstrate that \framework framework can effectively deploy multi-agent groups that outperform a single agent. Furthermore, we delve into the emergence of social behaviors among individual agents within a group during collaborative task accomplishment. In view of these behaviors, we discuss some possible strategies to leverage positive ones and mitigate negative ones for improving the collaborative potential of multi-agent groups. Our codes for \framework will soon be released at \url{https://github.com/OpenBMB/AgentVerse}.