 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSE-Bench: Benchmarking Self-Evolution with Knowledge Internalization
Feb 04, 2026True self-evolution requires agents to act as lifelong learners that internalize novel experiences to solve future problems. However, rigorously measuring this foundational capability is hindered by two obstacles: the entanglement of prior knowledge, where ``new'' knowledge may appear in pre-training data, and the entanglement of reasoning complexity, where failures may stem from problem difficulty rather than an inability to recall learned knowledge. We introduce SE-Bench, a diagnostic environment that obfuscates the NumPy library and its API doc into a pseudo-novel package with randomized identifiers. Agents are trained to internalize this package and evaluated on simple coding tasks without access to documentation, yielding a clean setting where tasks are trivial with the new API doc but impossible for base models without it. Our investigation reveals three insights: (1) the Open-Book Paradox, where training with reference documentation inhibits retention, requiring "Closed-Book Training" to force knowledge compression into weights; (2) the RL Gap, where standard RL fails to internalize new knowledge completely due to PPO clipping and negative gradients; and (3) the viability of Self-Play for internalization, proving models can learn from self-generated, noisy tasks when coupled with SFT, but not RL. Overall, SE-Bench establishes a rigorous diagnostic platform for self-evolution with knowledge internalization. Our code and dataset can be found at https://github.com/thunlp/SE-Bench.
CPMobius: Iterative Coach-Player Reasoning for Data-Free Reinforcement Learning
Feb 03, 2026Large Language Models (LLMs) have demonstrated strong potential in complex reasoning, yet their progress remains fundamentally constrained by reliance on massive high-quality human-curated tasks and labels, either through supervised fine-tuning (SFT) or reinforcement learning (RL) on reasoning-specific data. This dependence renders supervision-heavy training paradigms increasingly unsustainable, with signs of diminishing scalability already evident in practice. To overcome this limitation, we introduce CPMöbius (CPMobius), a collaborative Coach-Player paradigm for data-free reinforcement learning of reasoning models. Unlike traditional adversarial self-play, CPMöbius, inspired by real world human sports collaboration and multi-agent collaboration, treats the Coach and Player as independent but cooperative roles. The Coach proposes instructions targeted at the Player's capability and receives rewards based on changes in the Player's performance, while the Player is rewarded for solving the increasingly instructive tasks generated by the Coach. This cooperative optimization loop is designed to directly enhance the Player's mathematical reasoning ability. Remarkably, CPMöbius achieves substantial improvement without relying on any external training data, outperforming existing unsupervised approaches. For example, on Qwen2.5-Math-7B-Instruct, our method improves accuracy by an overall average of +4.9 and an out-of-distribution average of +5.4, exceeding RENT by +1.5 on overall accuracy and R-zero by +4.2 on OOD accuracy.
MiniCPM4: Ultra-Efficient LLMs on End Devices
Jun 09, 2025



This paper introduces MiniCPM4, a highly efficient large language model (LLM) designed explicitly for end-side devices. We achieve this efficiency through systematic innovation in four key dimensions: model architecture, training data, training algorithms, and inference systems. Specifically, in terms of model architecture, we propose InfLLM v2, a trainable sparse attention mechanism that accelerates both prefilling and decoding phases for long-context processing. Regarding training data, we propose UltraClean, an efficient and accurate pre-training data filtering and generation strategy, and UltraChat v2, a comprehensive supervised fine-tuning dataset. These datasets enable satisfactory model performance to be achieved using just 8 trillion training tokens. Regarding training algorithms, we propose ModelTunnel v2 for efficient pre-training strategy search, and improve existing post-training methods by introducing chunk-wise rollout for load-balanced reinforcement learning and data-efficient tenary LLM, BitCPM. Regarding inference systems, we propose CPM.cu that integrates sparse attention, model quantization, and speculative sampling to achieve efficient prefilling and decoding. To meet diverse on-device requirements, MiniCPM4 is available in two versions, with 0.5B and 8B parameters, respectively. Sufficient evaluation results show that MiniCPM4 outperforms open-source models of similar size across multiple benchmarks, highlighting both its efficiency and effectiveness. Notably, MiniCPM4-8B demonstrates significant speed improvements over Qwen3-8B when processing long sequences. Through further adaptation, MiniCPM4 successfully powers diverse applications, including trustworthy survey generation and tool use with model context protocol, clearly showcasing its broad usability.
The Overthinker's DIET: Cutting Token Calories with DIfficulty-AwarE Training
May 25, 2025



Recent large language models (LLMs) exhibit impressive reasoning but often over-think, generating excessively long responses that hinder efficiency. We introduce DIET ( DIfficulty-AwarE Training), a framework that systematically cuts these "token calories" by integrating on-the-fly problem difficulty into the reinforcement learning (RL) process. DIET dynamically adapts token compression strategies by modulating token penalty strength and conditioning target lengths on estimated task difficulty, to optimize the performance-efficiency trade-off. We also theoretically analyze the pitfalls of naive reward weighting in group-normalized RL algorithms like GRPO, and propose Advantage Weighting technique, which enables stable and effective implementation of these difficulty-aware objectives. Experimental results demonstrate that DIET significantly reduces token counts while simultaneously improving reasoning performance. Beyond raw token reduction, we show two crucial benefits largely overlooked by prior work: (1) DIET leads to superior inference scaling. By maintaining high per-sample quality with fewer tokens, it enables better scaling performance via majority voting with more samples under fixed computational budgets, an area where other methods falter. (2) DIET enhances the natural positive correlation between response length and problem difficulty, ensuring verbosity is appropriately allocated, unlike many existing compression methods that disrupt this relationship. Our analyses provide a principled and effective framework for developing more efficient, practical, and high-performing LLMs.
Process Reinforcement through Implicit Rewards
Feb 03, 2025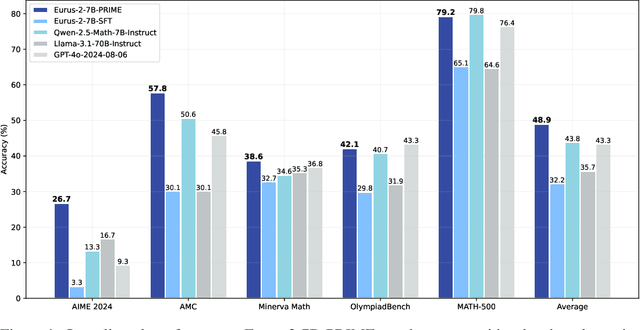

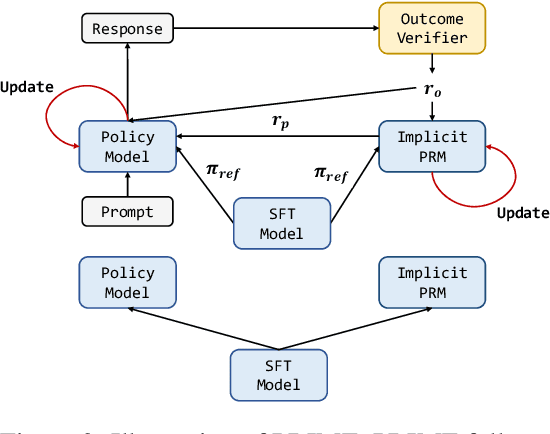
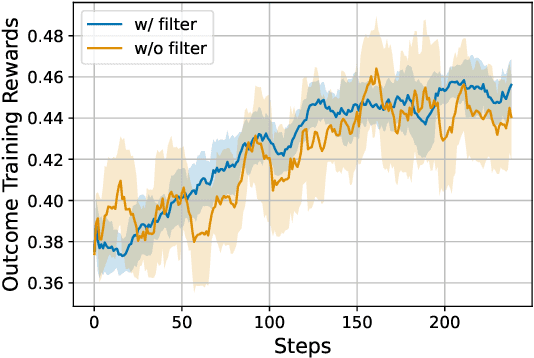
Dense process rewards have proven a more effective alternative to the sparse outcome-level rewards in the inference-time scaling of large language models (LLMs), particularly in tasks requiring complex multi-step reasoning. While dense rewards also offer an appealing choice for the reinforcement learning (RL) of LLMs since their fine-grained rewards have the potential to address some inherent issues of outcome rewards, such as training efficiency and credit assignment, this potential remains largely unrealized. This can be primarily attributed to the challenges of training process reward models (PRMs) online, where collecting high-quality process labels is prohibitively expensive, making them particularly vulnerable to reward hacking. To address these challenges, we propose PRIME (Process Reinforcement through IMplicit rEwards), which enables online PRM updates using only policy rollouts and outcome labels through implict process rewards. PRIME combines well with various advantage functions and forgoes the dedicated reward model training phrase that existing approaches require, substantially reducing the development overhead. We demonstrate PRIME's effectiveness on competitional math and coding. Starting from Qwen2.5-Math-7B-Base, PRIME achieves a 15.1% average improvement across several key reasoning benchmarks over the SFT model. Notably, our resulting model, Eurus-2-7B-PRIME, surpasses Qwen2.5-Math-7B-Instruct on seven reasoning benchmarks with 10% of its training data.
Optima: Optimizing Effectiveness and Efficiency for LLM-Based Multi-Agent System
Oct 10, 2024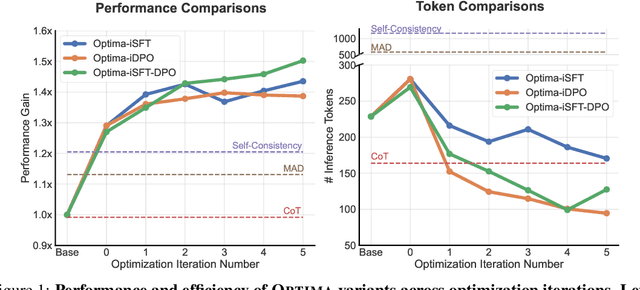
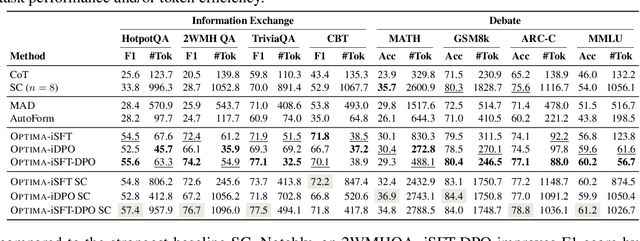
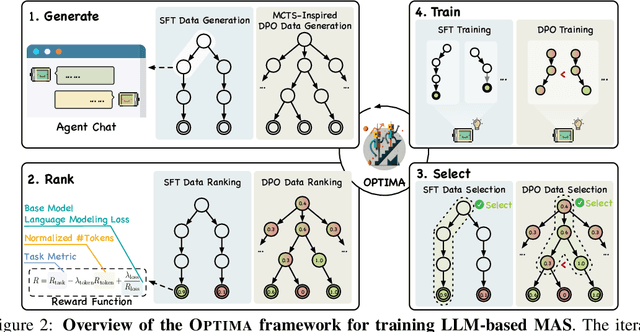
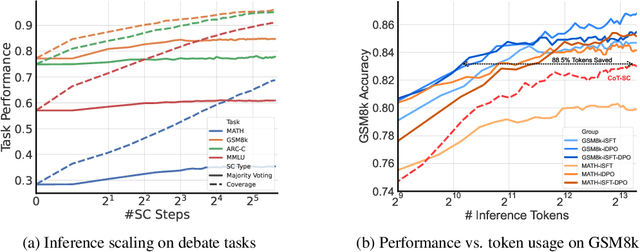
Large Language Model (LLM) based multi-agent systems (MAS) show remarkable potential in collaborative problem-solving, yet they still face critical challenges: low communication efficiency, poor scalability, and a lack of effective parameter-updating optimization methods. We present Optima, a novel framework that addresses these issues by significantly enhancing both communication efficiency and task effectiveness in LLM-based MAS through LLM training. Optima employs an iterative generate, rank, select, and train paradigm with a reward function balancing task performance, token efficiency, and communication readability. We explore various RL algorithms, including Supervised Fine-Tuning, Direct Preference Optimization, and their hybrid approaches, providing insights into their effectiveness-efficiency trade-offs. We integrate Monte Carlo Tree Search-inspired techniques for DPO data generation, treating conversation turns as tree nodes to explore diverse interaction paths. Evaluated on common multi-agent tasks, including information-asymmetric question answering and complex reasoning, Optima shows consistent and substantial improvements over single-agent baselines and vanilla MAS based on Llama 3 8B, achieving up to 2.8x performance gain with less than 10\% tokens on tasks requiring heavy information exchange. Moreover, Optima's efficiency gains open new possibilities for leveraging inference-compute more effectively, leading to improved inference-time scaling laws. By addressing fundamental challenges in LLM-based MAS, Optima shows the potential towards scalable, efficient, and effective MAS (https://chenweize1998.github.io/optima-project-page).
Beyond Natural Language: LLMs Leveraging Alternative Formats for Enhanced Reasoning and Communication
Feb 28, 2024
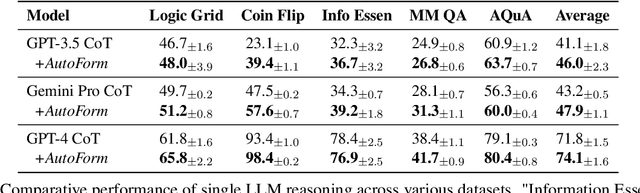

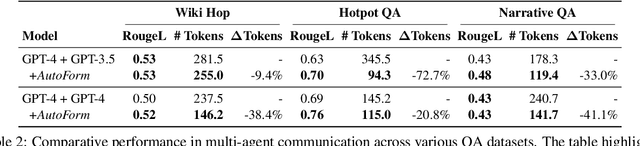
Natural language (NL) has long been the predominant format for human cognition and communication, and by extension, has been similarly pivotal in the development and application of Large Language Models (LLMs). Yet, besides NL, LLMs have seen various non-NL formats during pre-training, such as code and logical expression. NL's status as the optimal format for LLMs, particularly in single-LLM reasoning and multi-agent communication, has not been thoroughly examined. In this work, we challenge the default use of NL by exploring the utility of non-NL formats in these contexts. We show that allowing LLMs to autonomously select the most suitable format before reasoning or communicating leads to a 3.3 to 5.7\% improvement in reasoning efficiency for different LLMs, and up to a 72.7\% reduction in token usage in multi-agent communication, all while maintaining communicative effectiveness. Our comprehensive analysis further reveals that LLMs can devise a format from limited task instructions and that the devised format is effectively transferable across different LLMs. Intriguingly, the structured communication format decided by LLMs exhibits notable parallels with established agent communication languages, suggesting a natural evolution towards efficient, structured communication in agent communication. Our code is released at \url{https://github.com/thunlp/AutoForm}.