 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplement Kubernetes Pod-Level Remote Attestation for Confidential Workloads on dstack
Jun 03, 2026The rise of LLM-as-a-Service and other confidential cloud workloads demands cryptographic proof that user data is processed in a trusted, untampered environment. Existing solutions, notably Confidential Containers (CoCo), enforce a strict "one Pod per VM" model that attests only the Guest OS stack, leaving container-level identity unverified and incurring prohibitive per-VM resource overhead. We present dstack-capsule, a Kubernetes platform that enables Pod-level remote attestation on Intel TDX by allowing multiple Pods to share a single Confidential VM while each retains independent, hardware-backed proof of identity. Our key insight is a two-layer attestation architecture: static platform measurements are frozen in RTMR[3] via an irreversible privilege fuse, while dynamic Pod identities (pod_uid, pod_spec_hash, workload_id) are embedded in the TDX Quote's report_data field and signed by hardware on every request. dstack-capsule introduces (1) a Pod-level attestation protocol binding Pod spec digests to hardware-signed Quotes; (2) a privilege fuse mechanism that atomically transitions a node from setup mode to secure mode; (3) a multi-layer sandbox spanning storage, runtime, admission, API, and network isolation layers; and (4) a complete open-source implementation based on Kubernetes 1.32, Intel TDX, and Sysbox. We evaluate the security properties, attestation correctness, and performance characteristics of dstack-capsule, demonstrating that it achieves Pod-granularity verification without the resource overhead of per-VM isolation.
NTIRE 2026 Challenge on Single Image Reflection Removal in the Wild: Datasets, Results, and Methods
Apr 11, 2026In this paper, we review the NTIRE 2026 challenge on single-image reflection removal (SIRR) in the Wild. SIRR is a fundamental task in image restoration. Despite progress in academic research, most methods are tested on synthetic images or limited real-world images, creating a gap in real-world applications. In this challenge, we provide participants with the OpenRR-5k dataset, which requires them to process real-world images that cover a range of reflection scenarios and intensities, with the goal of generating clean images without reflections. The challenge attracted more than 100 registrations, with 11 of them participating in the final testing phase. The top-ranked methods advanced the state-of-the-art reflection removal performance and earned unanimous recognition from the five experts in the field. The proposed OpenRR-5k dataset is available at https://huggingface.co/datasets/qiuzhangTiTi/OpenRR-5k, and the homepage of this challenge is at https://github.com/caijie0620/OpenRR-5k. Due to page limitations, this article only presents partial content; the full report and detailed analyses are available in the extended arXiv version.
Dogfight Search: A Swarm-Based Optimization Algorithm for Complex Engineering Optimization and Mountainous Terrain Path Planning
Mar 30, 2026Dogfight is a tactical behavior of cooperation between fighters. Inspired by this, this paper proposes a novel metaphor-free metaheuristic algorithm called Dogfight Search (DoS). Unlike traditional algorithms, DoS draws algorithmic framework from the inspiration, but its search mechanism is constructed based on the displacement integration equations in kinematics. Through experimental validation on CEC2017 and CEC2022 benchmark test functions, 10 real-world constrained optimization problems and mountainous terrain path planning tasks, DoS significantly outperforms 7 advanced competitors in overall performance and ranks first in the Friedman ranking. Furthermore, this paper compares the performance of DoS with 3 SOTA algorithms on the CEC2017 and CEC2022 benchmark test functions. The results show that DoS continues to maintain its lead, demonstrating strong competitiveness. The source code of DoS is available at https://ww2.mathworks.cn/matlabcentral/fileexchange/183519-dogfight-search.
OpenRR-1k: A Scalable Dataset for Real-World Reflection Removal
Jun 10, 2025Reflection removal technology plays a crucial role in photography and computer vision applications. However, existing techniques are hindered by the lack of high-quality in-the-wild datasets. In this paper, we propose a novel paradigm for collecting reflection datasets from a fresh perspective. Our approach is convenient, cost-effective, and scalable, while ensuring that the collected data pairs are of high quality, perfectly aligned, and represent natural and diverse scenarios. Following this paradigm, we collect a Real-world, Diverse, and Pixel-aligned dataset (named OpenRR-1k dataset), which contains 1,000 high-quality transmission-reflection image pairs collected in the wild. Through the analysis of several reflection removal methods and benchmark evaluation experiments on our dataset, we demonstrate its effectiveness in improving robustness in challenging real-world environments. Our dataset is available at https://github.com/caijie0620/OpenRR-1k.
MiniCPM4: Ultra-Efficient LLMs on End Devices
Jun 09, 2025



This paper introduces MiniCPM4, a highly efficient large language model (LLM) designed explicitly for end-side devices. We achieve this efficiency through systematic innovation in four key dimensions: model architecture, training data, training algorithms, and inference systems. Specifically, in terms of model architecture, we propose InfLLM v2, a trainable sparse attention mechanism that accelerates both prefilling and decoding phases for long-context processing. Regarding training data, we propose UltraClean, an efficient and accurate pre-training data filtering and generation strategy, and UltraChat v2, a comprehensive supervised fine-tuning dataset. These datasets enable satisfactory model performance to be achieved using just 8 trillion training tokens. Regarding training algorithms, we propose ModelTunnel v2 for efficient pre-training strategy search, and improve existing post-training methods by introducing chunk-wise rollout for load-balanced reinforcement learning and data-efficient tenary LLM, BitCPM. Regarding inference systems, we propose CPM.cu that integrates sparse attention, model quantization, and speculative sampling to achieve efficient prefilling and decoding. To meet diverse on-device requirements, MiniCPM4 is available in two versions, with 0.5B and 8B parameters, respectively. Sufficient evaluation results show that MiniCPM4 outperforms open-source models of similar size across multiple benchmarks, highlighting both its efficiency and effectiveness. Notably, MiniCPM4-8B demonstrates significant speed improvements over Qwen3-8B when processing long sequences. Through further adaptation, MiniCPM4 successfully powers diverse applications, including trustworthy survey generation and tool use with model context protocol, clearly showcasing its broad usability.
Degradation-Aware Image Enhancement via Vision-Language Classification
Jun 05, 2025Image degradation is a prevalent issue in various real-world applications, affecting visual quality and downstream processing tasks. In this study, we propose a novel framework that employs a Vision-Language Model (VLM) to automatically classify degraded images into predefined categories. The VLM categorizes an input image into one of four degradation types: (A) super-resolution degradation (including noise, blur, and JPEG compression), (B) reflection artifacts, (C) motion blur, or (D) no visible degradation (high-quality image). Once classified, images assigned to categories A, B, or C undergo targeted restoration using dedicated models tailored for each specific degradation type. The final output is a restored image with improved visual quality. Experimental results demonstrate the effectiveness of our approach in accurately classifying image degradations and enhancing image quality through specialized restoration models. Our method presents a scalable and automated solution for real-world image enhancement tasks, leveraging the capabilities of VLMs in conjunction with state-of-the-art restoration techniques.
OpenRR-5k: A Large-Scale Benchmark for Reflection Removal in the Wild
Jun 05, 2025Removing reflections is a crucial task in computer vision, with significant applications in photography and image enhancement. Nevertheless, existing methods are constrained by the absence of large-scale, high-quality, and diverse datasets. In this paper, we present a novel benchmark for Single Image Reflection Removal (SIRR). We have developed a large-scale dataset containing 5,300 high-quality, pixel-aligned image pairs, each consisting of a reflection image and its corresponding clean version. Specifically, the dataset is divided into two parts: 5,000 images are used for training, and 300 images are used for validation. Additionally, we have included 100 real-world testing images without ground truth (GT) to further evaluate the practical performance of reflection removal methods. All image pairs are precisely aligned at the pixel level to guarantee accurate supervision. The dataset encompasses a broad spectrum of real-world scenarios, featuring various lighting conditions, object types, and reflection patterns, and is segmented into training, validation, and test sets to facilitate thorough evaluation. To validate the usefulness of our dataset, we train a U-Net-based model and evaluate it using five widely-used metrics, including PSNR, SSIM, LPIPS, DISTS, and NIQE. We will release both the dataset and the code on https://github.com/caijie0620/OpenRR-5k to facilitate future research in this field.
F2T2-HiT: A U-Shaped FFT Transformer and Hierarchical Transformer for Reflection Removal
Jun 05, 2025Single Image Reflection Removal (SIRR) technique plays a crucial role in image processing by eliminating unwanted reflections from the background. These reflections, often caused by photographs taken through glass surfaces, can significantly degrade image quality. SIRR remains a challenging problem due to the complex and varied reflections encountered in real-world scenarios. These reflections vary significantly in intensity, shapes, light sources, sizes, and coverage areas across the image, posing challenges for most existing methods to effectively handle all cases. To address these challenges, this paper introduces a U-shaped Fast Fourier Transform Transformer and Hierarchical Transformer (F2T2-HiT) architecture, an innovative Transformer-based design for SIRR. Our approach uniquely combines Fast Fourier Transform (FFT) Transformer blocks and Hierarchical Transformer blocks within a UNet framework. The FFT Transformer blocks leverage the global frequency domain information to effectively capture and separate reflection patterns, while the Hierarchical Transformer blocks utilize multi-scale feature extraction to handle reflections of varying sizes and complexities. Extensive experiments conducted on three publicly available testing datasets demonstrate state-of-the-art performance, validating the effectiveness of our approach.
Ultra-FineWeb: Efficient Data Filtering and Verification for High-Quality LLM Training Data
May 08, 2025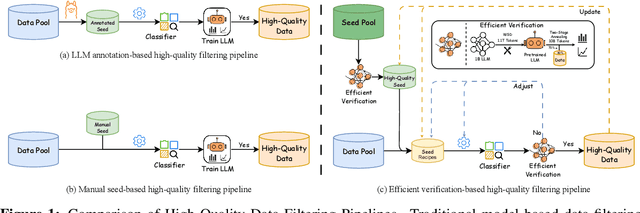



Data quality has become a key factor in enhancing model performance with the rapid development of large language models (LLMs). Model-driven data filtering has increasingly become a primary approach for acquiring high-quality data. However, it still faces two main challenges: (1) the lack of an efficient data verification strategy makes it difficult to provide timely feedback on data quality; and (2) the selection of seed data for training classifiers lacks clear criteria and relies heavily on human expertise, introducing a degree of subjectivity. To address the first challenge, we introduce an efficient verification strategy that enables rapid evaluation of the impact of data on LLM training with minimal computational cost. To tackle the second challenge, we build upon the assumption that high-quality seed data is beneficial for LLM training, and by integrating the proposed verification strategy, we optimize the selection of positive and negative samples and propose an efficient data filtering pipeline. This pipeline not only improves filtering efficiency, classifier quality, and robustness, but also significantly reduces experimental and inference costs. In addition, to efficiently filter high-quality data, we employ a lightweight classifier based on fastText, and successfully apply the filtering pipeline to two widely-used pre-training corpora, FineWeb and Chinese FineWeb datasets, resulting in the creation of the higher-quality Ultra-FineWeb dataset. Ultra-FineWeb contains approximately 1 trillion English tokens and 120 billion Chinese tokens. Empirical results demonstrate that the LLMs trained on Ultra-FineWeb exhibit significant performance improvements across multiple benchmark tasks, validating the effectiveness of our pipeline in enhancing both data quality and training efficiency.
Survey on Single-Image Reflection Removal using Deep Learning Techniques
Feb 12, 2025The phenomenon of reflection is quite common in digital images, posing significant challenges for various applications such as computer vision, photography, and image processing. Traditional methods for reflection removal often struggle to achieve clean results while maintaining high fidelity and robustness, particularly in real-world scenarios. Over the past few decades, numerous deep learning-based approaches for reflection removal have emerged, yielding impressive results. In this survey, we conduct a comprehensive review of the current literature by focusing on key venues such as ICCV, ECCV, CVPR, NeurIPS, etc., as these conferences and journals have been central to advances in the field. Our review follows a structured paper selection process, and we critically assess both single-stage and two-stage deep learning methods for reflection removal. The contribution of this survey is three-fold: first, we provide a comprehensive summary of the most recent work on single-image reflection removal; second, we outline task hypotheses, current deep learning techniques, publicly available datasets, and relevant evaluation metrics; and third, we identify key challenges and opportunities in deep learning-based reflection removal, highlighting the potential of this rapidly evolving research area.