 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiniCPM4: Ultra-Efficient LLMs on End Devices
Jun 09, 2025



This paper introduces MiniCPM4, a highly efficient large language model (LLM) designed explicitly for end-side devices. We achieve this efficiency through systematic innovation in four key dimensions: model architecture, training data, training algorithms, and inference systems. Specifically, in terms of model architecture, we propose InfLLM v2, a trainable sparse attention mechanism that accelerates both prefilling and decoding phases for long-context processing. Regarding training data, we propose UltraClean, an efficient and accurate pre-training data filtering and generation strategy, and UltraChat v2, a comprehensive supervised fine-tuning dataset. These datasets enable satisfactory model performance to be achieved using just 8 trillion training tokens. Regarding training algorithms, we propose ModelTunnel v2 for efficient pre-training strategy search, and improve existing post-training methods by introducing chunk-wise rollout for load-balanced reinforcement learning and data-efficient tenary LLM, BitCPM. Regarding inference systems, we propose CPM.cu that integrates sparse attention, model quantization, and speculative sampling to achieve efficient prefilling and decoding. To meet diverse on-device requirements, MiniCPM4 is available in two versions, with 0.5B and 8B parameters, respectively. Sufficient evaluation results show that MiniCPM4 outperforms open-source models of similar size across multiple benchmarks, highlighting both its efficiency and effectiveness. Notably, MiniCPM4-8B demonstrates significant speed improvements over Qwen3-8B when processing long sequences. Through further adaptation, MiniCPM4 successfully powers diverse applications, including trustworthy survey generation and tool use with model context protocol, clearly showcasing its broad usability.
YuLan: An Open-source Large Language Model
Jun 28, 2024



Large language models (LLMs) have become the foundation of many applications, leveraging their extensive capabilities in processing and understanding natural language. While many open-source LLMs have been released with technical reports, the lack of training details hinders further research and development. This paper presents the development of YuLan, a series of open-source LLMs with $12$ billion parameters. The base model of YuLan is pre-trained on approximately $1.7$T tokens derived from a diverse corpus, including massive English, Chinese, and multilingual texts. We design a three-stage pre-training method to enhance YuLan's overall capabilities. Subsequent phases of training incorporate instruction-tuning and human alignment, employing a substantial volume of high-quality synthesized data. To facilitate the learning of complex and long-tail knowledge, we devise a curriculum-learning framework throughout across these stages, which helps LLMs learn knowledge in an easy-to-hard manner. YuLan's training is finished on Jan, 2024 and has achieved performance on par with state-of-the-art LLMs across various English and Chinese benchmarks. This paper outlines a comprehensive technical roadmap for developing LLMs from scratch. Our model and codes are available at https://github.com/RUC-GSAI/YuLan-Chat.
ICLEval: Evaluating In-Context Learning Ability of Large Language Models
Jun 21, 2024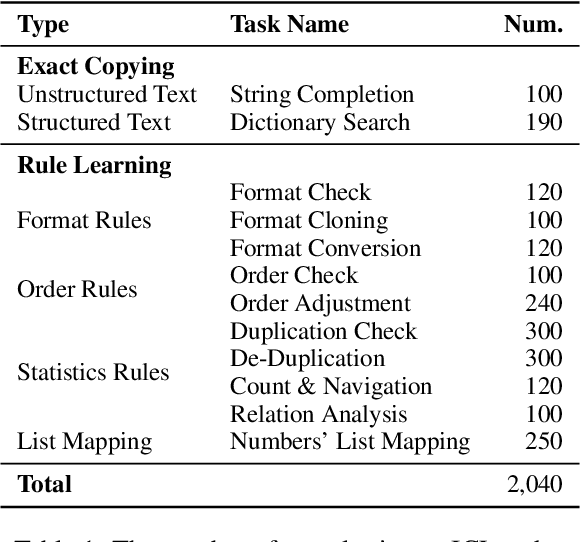
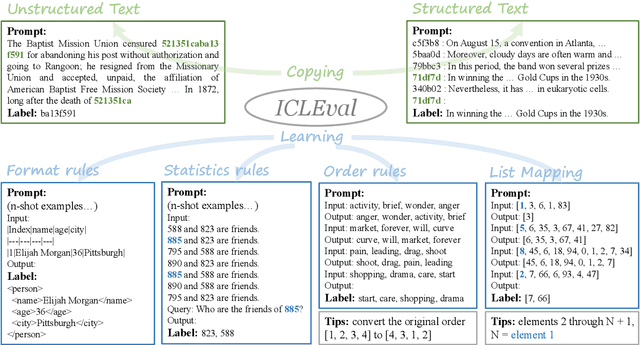
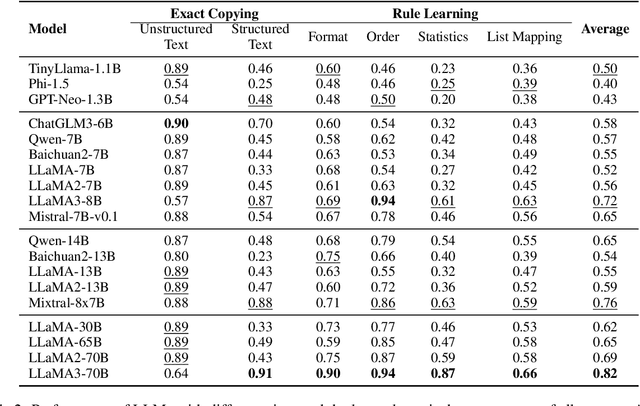
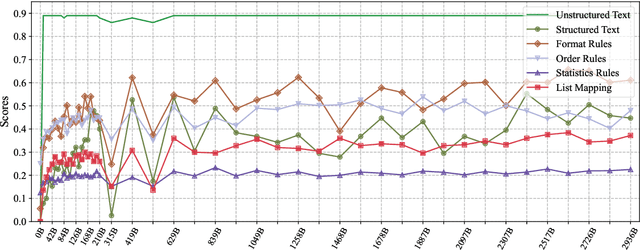
In-Context Learning (ICL) is a critical capability of Large Language Models (LLMs) as it empowers them to comprehend and reason across interconnected inputs. Evaluating the ICL ability of LLMs can enhance their utilization and deepen our understanding of how this ability is acquired at the training stage. However, existing evaluation frameworks primarily focus on language abilities and knowledge, often overlooking the assessment of ICL ability. In this work, we introduce the ICLEval benchmark to evaluate the ICL abilities of LLMs, which encompasses two key sub-abilities: exact copying and rule learning. Through the ICLEval benchmark, we demonstrate that ICL ability is universally present in different LLMs, and model size is not the sole determinant of ICL efficacy. Surprisingly, we observe that ICL abilities, particularly copying, develop early in the pretraining process and stabilize afterward. Our source codes and benchmark are released at https://github.com/yiye3/ICLEval.
GUICourse: From General Vision Language Models to Versatile GUI Agents
Jun 17, 2024
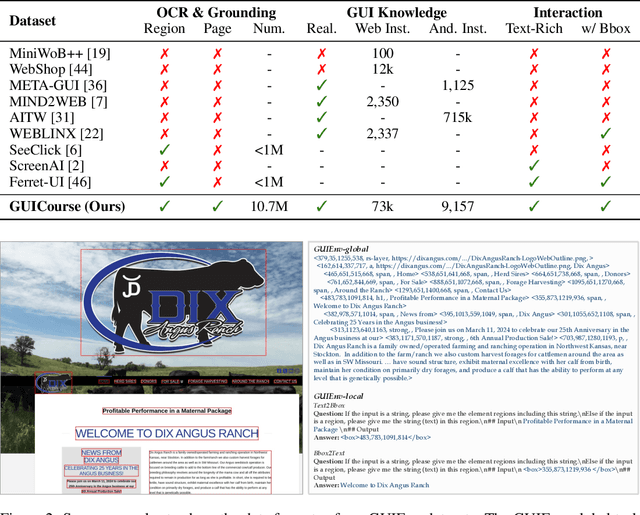
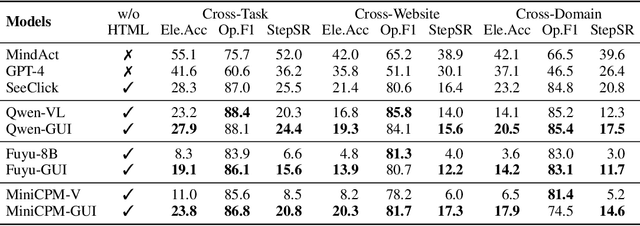
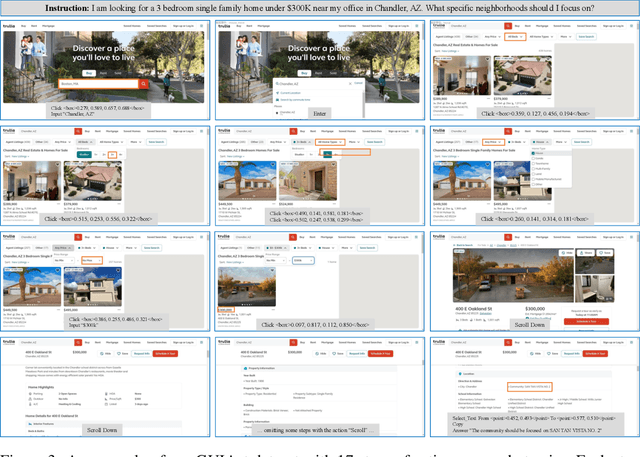
Utilizing Graphic User Interface (GUI) for human-computer interaction is essential for accessing a wide range of digital tools. Recent advancements in Vision Language Models (VLMs) highlight the compelling potential to develop versatile agents to help humans finish GUI navigation tasks. However, current VLMs are challenged in terms of fundamental abilities (OCR and grounding) and GUI knowledge (the functions and control methods of GUI elements), preventing them from becoming practical GUI agents. To solve these challenges, we contribute GUICourse, a suite of datasets to train visual-based GUI agents from general VLMs. First, we introduce the GUIEnv dataset to strengthen the OCR and grounding capabilities of VLMs. Then, we introduce the GUIAct and GUIChat datasets to enrich their knowledge of GUI components and interactions. Experiments demonstrate that our GUI agents have better performance on common GUI tasks than their baseline VLMs. Even the small-size GUI agent (with 3.1B parameters) can still work well on single-step and multi-step GUI tasks. Finally, we analyze the different varieties in the training stage of this agent by ablation study. Our source codes and datasets are released at https://github.com/yiye3/GUICourse.
Don't Make Your LLM an Evaluation Benchmark Cheater
Nov 03, 2023Large language models~(LLMs) have greatly advanced the frontiers of artificial intelligence, attaining remarkable improvement in model capacity. To assess the model performance, a typical approach is to construct evaluation benchmarks for measuring the ability level of LLMs in different aspects. Despite that a number of high-quality benchmarks have been released, the concerns about the appropriate use of these benchmarks and the fair comparison of different models are increasingly growing. Considering these concerns, in this paper, we discuss the potential risk and impact of inappropriately using evaluation benchmarks and misleadingly interpreting the evaluation results. Specially, we focus on a special issue that would lead to inappropriate evaluation, \ie \emph{benchmark leakage}, referring that the data related to evaluation sets is occasionally used for model training. This phenomenon now becomes more common since pre-training data is often prepared ahead of model test. We conduct extensive experiments to study the effect of benchmark leverage, and find that it can dramatically boost the evaluation results, which would finally lead to an unreliable assessment of model performance. To improve the use of existing evaluation benchmarks, we finally present several guidelines for both LLM developers and benchmark maintainers. We hope this work can draw attention to appropriate training and evaluation of LLMs.