 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUltraEval-Audio: A Unified Framework for Comprehensive Evaluation of Audio Foundation Models
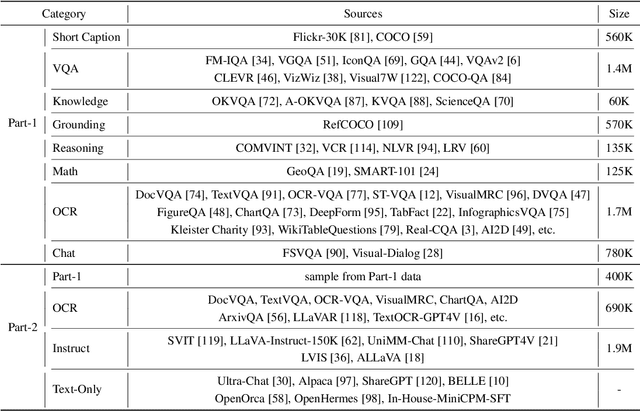
Jan 04, 2026The development of audio foundation models has accelerated rapidly since the emergence of GPT-4o. However, the lack of comprehensive evaluation has become a critical bottleneck for further progress in the field, particularly in audio generation. Current audio evaluation faces three major challenges: (1) audio evaluation lacks a unified framework, with datasets and code scattered across various sources, hindering fair and efficient cross-model comparison;(2) audio codecs, as a key component of audio foundation models, lack a widely accepted and holistic evaluation methodology; (3) existing speech benchmarks are heavily reliant on English, making it challenging to objectively assess models' performance on Chinese. To address the first issue, we introduce UltraEval-Audio, a unified evaluation framework for audio foundation models, specifically designed for both audio understanding and generation tasks. UltraEval-Audio features a modular architecture, supporting 10 languages and 14 core task categories, while seamlessly integrating 24 mainstream models and 36 authoritative benchmarks. To enhance research efficiency, the framework provides a one-command evaluation feature, accompanied by real-time public leaderboards. For the second challenge, UltraEval-Audio adopts a novel comprehensive evaluation scheme for audio codecs, evaluating performance across three key dimensions: semantic accuracy, timbre fidelity, and acoustic quality. To address the third issue, we propose two new Chinese benchmarks, SpeechCMMLU and SpeechHSK, designed to assess Chinese knowledge proficiency and language fluency. We wish that UltraEval-Audio will provide both academia and industry with a transparent, efficient, and fair platform for comparison of audio models. Our code, benchmarks, and leaderboards are available at https://github.com/OpenBMB/UltraEval-Audio.
VisRAG: Vision-based Retrieval-augmented Generation on Multi-modality Documents
Oct 14, 2024



Retrieval-augmented generation (RAG) is an effective technique that enables large language models (LLMs) to utilize external knowledge sources for generation. However, current RAG systems are solely based on text, rendering it impossible to utilize vision information like layout and images that play crucial roles in real-world multi-modality documents. In this paper, we introduce VisRAG, which tackles this issue by establishing a vision-language model (VLM)-based RAG pipeline. In this pipeline, instead of first parsing the document to obtain text, the document is directly embedded using a VLM as an image and then retrieved to enhance the generation of a VLM. Compared to traditional text-based RAG, VisRAG maximizes the retention and utilization of the data information in the original documents, eliminating the information loss introduced during the parsing process. We collect both open-source and synthetic data to train the retriever in VisRAG and explore a variety of generation methods. Experiments demonstrate that VisRAG outperforms traditional RAG in both the retrieval and generation stages, achieving a 25--39\% end-to-end performance gain over traditional text-based RAG pipeline. Further analysis reveals that VisRAG is effective in utilizing training data and demonstrates strong generalization capability, positioning it as a promising solution for RAG on multi-modality documents. Our code and data are available at https://github.com/openbmb/visrag .
MiniCPM-V: A GPT-4V Level MLLM on Your Phone
Aug 03, 2024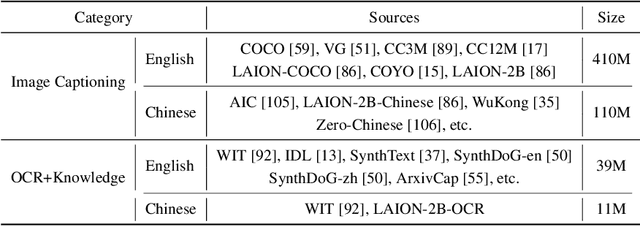

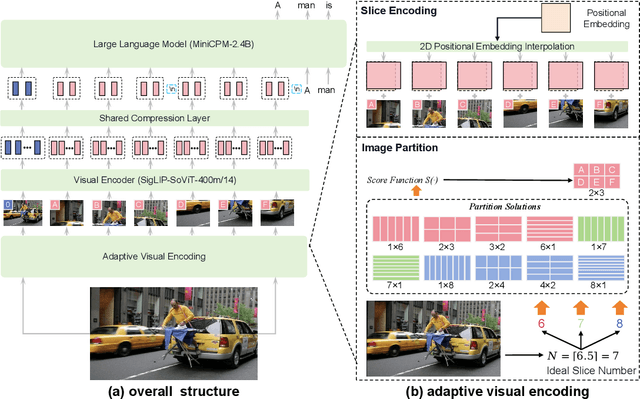
The recent surge of Multimodal Large Language Models (MLLMs) has fundamentally reshaped the landscape of AI research and industry, shedding light on a promising path toward the next AI milestone. However, significant challenges remain preventing MLLMs from being practical in real-world applications. The most notable challenge comes from the huge cost of running an MLLM with a massive number of parameters and extensive computation. As a result, most MLLMs need to be deployed on high-performing cloud servers, which greatly limits their application scopes such as mobile, offline, energy-sensitive, and privacy-protective scenarios. In this work, we present MiniCPM-V, a series of efficient MLLMs deployable on end-side devices. By integrating the latest MLLM techniques in architecture, pretraining and alignment, the latest MiniCPM-Llama3-V 2.5 has several notable features: (1) Strong performance, outperforming GPT-4V-1106, Gemini Pro and Claude 3 on OpenCompass, a comprehensive evaluation over 11 popular benchmarks, (2) strong OCR capability and 1.8M pixel high-resolution image perception at any aspect ratio, (3) trustworthy behavior with low hallucination rates, (4) multilingual support for 30+ languages, and (5) efficient deployment on mobile phones. More importantly, MiniCPM-V can be viewed as a representative example of a promising trend: The model sizes for achieving usable (e.g., GPT-4V) level performance are rapidly decreasing, along with the fast growth of end-side computation capacity. This jointly shows that GPT-4V level MLLMs deployed on end devices are becoming increasingly possible, unlocking a wider spectrum of real-world AI applications in the near future.
GUICourse: From General Vision Language Models to Versatile GUI Agents
Jun 17, 2024
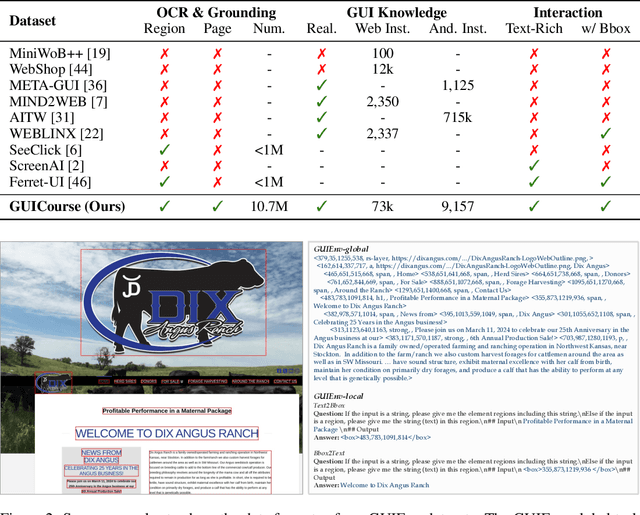
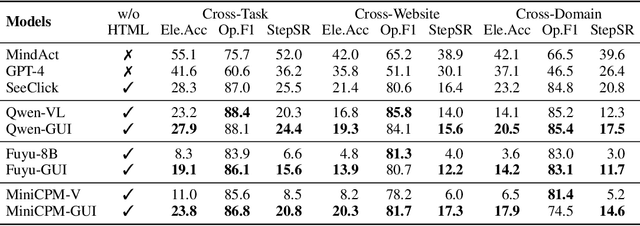
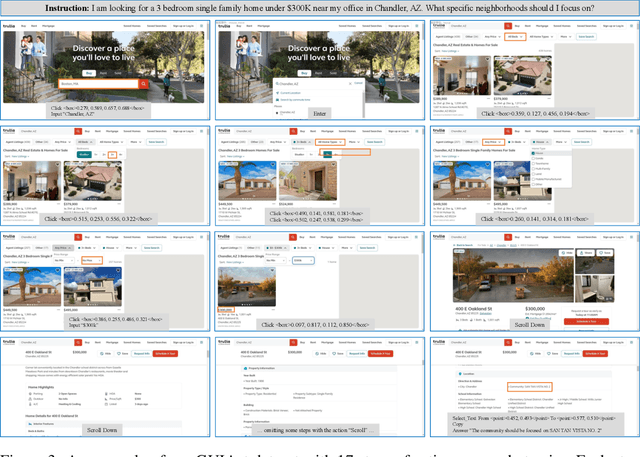
Utilizing Graphic User Interface (GUI) for human-computer interaction is essential for accessing a wide range of digital tools. Recent advancements in Vision Language Models (VLMs) highlight the compelling potential to develop versatile agents to help humans finish GUI navigation tasks. However, current VLMs are challenged in terms of fundamental abilities (OCR and grounding) and GUI knowledge (the functions and control methods of GUI elements), preventing them from becoming practical GUI agents. To solve these challenges, we contribute GUICourse, a suite of datasets to train visual-based GUI agents from general VLMs. First, we introduce the GUIEnv dataset to strengthen the OCR and grounding capabilities of VLMs. Then, we introduce the GUIAct and GUIChat datasets to enrich their knowledge of GUI components and interactions. Experiments demonstrate that our GUI agents have better performance on common GUI tasks than their baseline VLMs. Even the small-size GUI agent (with 3.1B parameters) can still work well on single-step and multi-step GUI tasks. Finally, we analyze the different varieties in the training stage of this agent by ablation study. Our source codes and datasets are released at https://github.com/yiye3/GUICourse.
LLaVA-UHD: an LMM Perceiving Any Aspect Ratio and High-Resolution Images
Mar 18, 2024



Visual encoding constitutes the basis of large multimodal models (LMMs) in understanding the visual world. Conventional LMMs process images in fixed sizes and limited resolutions, while recent explorations in this direction are limited in adaptivity, efficiency, and even correctness. In this work, we first take GPT-4V and LLaVA-1.5 as representative examples and expose systematic flaws rooted in their visual encoding strategy. To address the challenges, we present LLaVA-UHD, a large multimodal model that can efficiently perceive images in any aspect ratio and high resolution. LLaVA-UHD includes three key components: (1) An image modularization strategy that divides native-resolution images into smaller variable-sized slices for efficient and extensible encoding, (2) a compression module that further condenses image tokens from visual encoders, and (3) a spatial schema to organize slice tokens for LLMs. Comprehensive experiments show that LLaVA-UHD outperforms established LMMs trained with 2-3 orders of magnitude more data on 9 benchmarks. Notably, our model built on LLaVA-1.5 336x336 supports 6 times larger (i.e., 672x1088) resolution images using only 94% inference computation, and achieves 6.4 accuracy improvement on TextVQA. Moreover, the model can be efficiently trained in academic settings, within 23 hours on 8 A100 GPUs (vs. 26 hours of LLaVA-1.5). We make the data and code publicly available at https://github.com/thunlp/LLaVA-UHD.