 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph-Anchored Knowledge Indexing for Retrieval-Augmented Generation
Jan 23, 2026Retrieval-Augmented Generation (RAG) has emerged as a dominant paradigm for mitigating hallucinations in Large Language Models (LLMs) by incorporating external knowledge. Nevertheless, effectively integrating and interpreting key evidence scattered across noisy documents remains a critical challenge for existing RAG systems. In this paper, we propose GraphAnchor, a novel Graph-Anchored Knowledge Indexing approach that reconceptualizes graph structures from static knowledge representations into active, evolving knowledge indices. GraphAnchor incrementally updates a graph during iterative retrieval to anchor salient entities and relations, yielding a structured index that guides the LLM in evaluating knowledge sufficiency and formulating subsequent subqueries. The final answer is generated by jointly leveraging all retrieved documents and the final evolved graph. Experiments on four multi-hop question answering benchmarks demonstrate the effectiveness of GraphAnchor, and reveal that GraphAnchor modulates the LLM's attention to more effectively associate key information distributed in retrieved documents. All code and data are available at https://github.com/NEUIR/GraphAnchor.
Teaching LLMs to Learn Tool Trialing and Execution through Environment Interaction
Jan 19, 2026Equipping Large Language Models (LLMs) with external tools enables them to solve complex real-world problems. However, the robustness of existing methods remains a critical challenge when confronting novel or evolving tools. Existing trajectory-centric paradigms primarily rely on memorizing static solution paths during training, which limits the ability of LLMs to generalize tool usage to newly introduced or previously unseen tools. In this paper, we propose ToolMaster, a framework that shifts tool use from imitating golden tool-calling trajectories to actively learning tool usage through interaction with the environment. To optimize LLMs for tool planning and invocation, ToolMaster adopts a trial-and-execution paradigm, which trains LLMs to first imitate teacher-generated trajectories containing explicit tool trials and self-correction, followed by reinforcement learning to coordinate the trial and execution phases jointly. This process enables agents to autonomously explore correct tool usage by actively interacting with environments and forming experiential knowledge that benefits tool execution. Experimental results demonstrate that ToolMaster significantly outperforms existing baselines in terms of generalization and robustness across unseen or unfamiliar tools. All code and data are available at https://github.com/NEUIR/ToolMaster.
Long-Chain Reasoning Distillation via Adaptive Prefix Alignment
Jan 15, 2026Large Language Models (LLMs) have demonstrated remarkable reasoning capabilities, particularly in solving complex mathematical problems. Recent studies show that distilling long reasoning trajectories can effectively enhance the reasoning performance of small-scale student models. However, teacher-generated reasoning trajectories are often excessively long and structurally complex, making them difficult for student models to learn. This mismatch leads to a gap between the provided supervision signal and the learning capacity of the student model. To address this challenge, we propose Prefix-ALIGNment distillation (P-ALIGN), a framework that fully exploits teacher CoTs for distillation through adaptive prefix alignment. Specifically, P-ALIGN adaptively truncates teacher-generated reasoning trajectories by determining whether the remaining suffix is concise and sufficient to guide the student model. Then, P-ALIGN leverages the teacher-generated prefix to supervise the student model, encouraging effective prefix alignment. Experiments on multiple mathematical reasoning benchmarks demonstrate that P-ALIGN outperforms all baselines by over 3%. Further analysis indicates that the prefixes constructed by P-ALIGN provide more effective supervision signals, while avoiding the negative impact of redundant and uncertain reasoning components. All code is available at https://github.com/NEUIR/P-ALIGN.
Structured Knowledge Representation through Contextual Pages for Retrieval-Augmented Generation
Jan 14, 2026Retrieval-Augmented Generation (RAG) enhances Large Language Models (LLMs) by incorporating external knowledge. Recently, some works have incorporated iterative knowledge accumulation processes into RAG models to progressively accumulate and refine query-related knowledge, thereby constructing more comprehensive knowledge representations. However, these iterative processes often lack a coherent organizational structure, which limits the construction of more comprehensive and cohesive knowledge representations. To address this, we propose PAGER, a page-driven autonomous knowledge representation framework for RAG. PAGER first prompts an LLM to construct a structured cognitive outline for a given question, which consists of multiple slots representing a distinct knowledge aspect. Then, PAGER iteratively retrieves and refines relevant documents to populate each slot, ultimately constructing a coherent page that serves as contextual input for guiding answer generation. Experiments on multiple knowledge-intensive benchmarks and backbone models show that PAGER consistently outperforms all RAG baselines. Further analyses demonstrate that PAGER constructs higher-quality and information-dense knowledge representations, better mitigates knowledge conflicts, and enables LLMs to leverage external knowledge more effectively. All code is available at https://github.com/OpenBMB/PAGER.
Revealing the Attention Floating Mechanism in Masked Diffusion Models
Jan 12, 2026Masked diffusion models (MDMs), which leverage bidirectional attention and a denoising process, are narrowing the performance gap with autoregressive models (ARMs). However, their internal attention mechanisms remain under-explored. This paper investigates the attention behaviors in MDMs, revealing the phenomenon of Attention Floating. Unlike ARMs, where attention converges to a fixed sink, MDMs exhibit dynamic, dispersed attention anchors that shift across denoising steps and layers. Further analysis reveals its Shallow Structure-Aware, Deep Content-Focused attention mechanism: shallow layers utilize floating tokens to build a global structural framework, while deeper layers allocate more capability toward capturing semantic content. Empirically, this distinctive attention pattern provides a mechanistic explanation for the strong in-context learning capabilities of MDMs, allowing them to double the performance compared to ARMs in knowledge-intensive tasks. All codes and datasets are available at https://github.com/NEUIR/Attention-Floating.
Legal$Δ$: Enhancing Legal Reasoning in LLMs via Reinforcement Learning with Chain-of-Thought Guided Information Gain
Aug 17, 2025
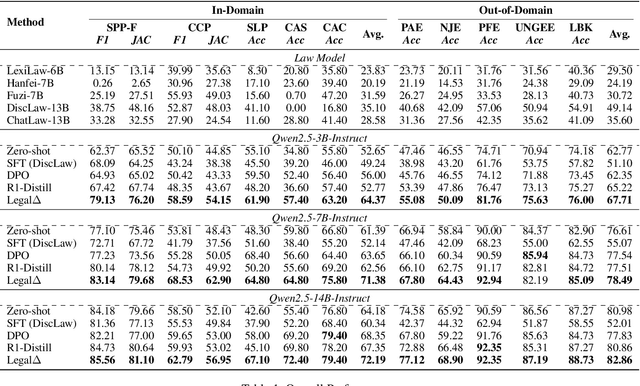

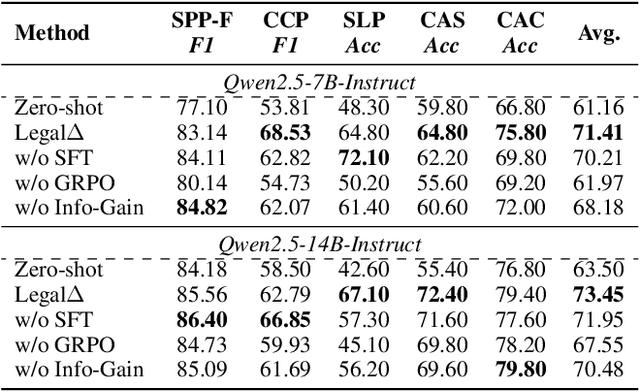
Legal Artificial Intelligence (LegalAI) has achieved notable advances in automating judicial decision-making with the support of Large Language Models (LLMs). However, existing legal LLMs still struggle to generate reliable and interpretable reasoning processes. They often default to fast-thinking behavior by producing direct answers without explicit multi-step reasoning, limiting their effectiveness in complex legal scenarios that demand rigorous justification. To address this challenge, we propose Legal$\Delta$, a reinforcement learning framework designed to enhance legal reasoning through chain-of-thought guided information gain. During training, Legal$\Delta$ employs a dual-mode input setup-comprising direct answer and reasoning-augmented modes-and maximizes the information gain between them. This encourages the model to acquire meaningful reasoning patterns rather than generating superficial or redundant explanations. Legal$\Delta$ follows a two-stage approach: (1) distilling latent reasoning capabilities from a powerful Large Reasoning Model (LRM), DeepSeek-R1, and (2) refining reasoning quality via differential comparisons, combined with a multidimensional reward mechanism that assesses both structural coherence and legal-domain specificity. Experimental results on multiple legal reasoning tasks demonstrate that Legal$\Delta$ outperforms strong baselines in both accuracy and interpretability. It consistently produces more robust and trustworthy legal judgments without relying on labeled preference data. All code and data will be released at https://github.com/NEUIR/LegalDelta.
ReCUT: Balancing Reasoning Length and Accuracy in LLMs via Stepwise Trails and Preference Optimization
Jun 12, 2025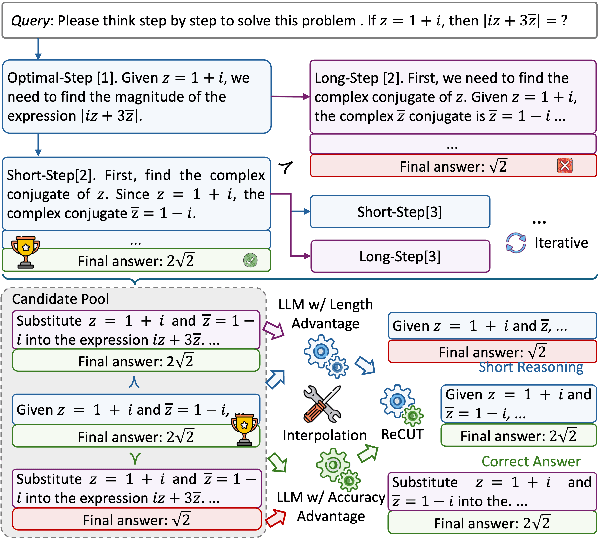
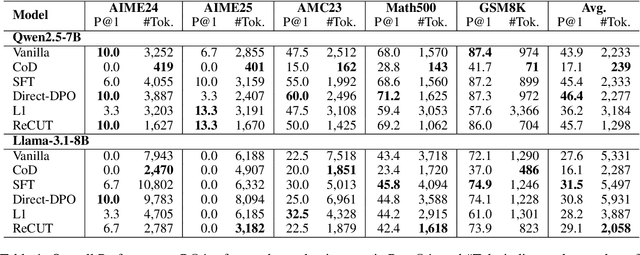
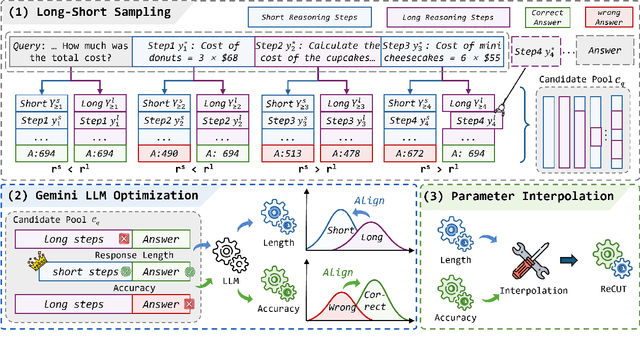
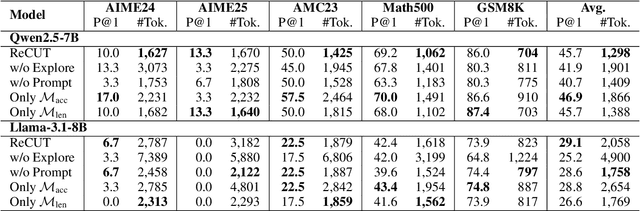
Recent advances in Chain-of-Thought (CoT) prompting have substantially improved the reasoning capabilities of Large Language Models (LLMs). However, these methods often suffer from overthinking, leading to unnecessarily lengthy or redundant reasoning traces. Existing approaches attempt to mitigate this issue through curating multiple reasoning chains for training LLMs, but their effectiveness is often constrained by the quality of the generated data and prone to overfitting. To address the challenge, we propose Reasoning Compression ThroUgh Stepwise Trials (ReCUT), a novel method aimed at balancing the accuracy and length of reasoning trajectory. Specifically, ReCUT employs a stepwise exploration mechanism and a long-short switched sampling strategy, enabling LLMs to incrementally generate diverse reasoning paths. These paths are evaluated and used to construct preference pairs to train two specialized models (Gemini LLMs)-one optimized for reasoning accuracy, the other for shorter reasoning. A final integrated model is obtained by interpolating the parameters of these two models. Experimental results across multiple math reasoning datasets and backbone models demonstrate that ReCUT significantly reduces reasoning lengths by approximately 30-50%, while maintaining or improving reasoning accuracy compared to various baselines. All codes and data will be released via https://github.com/NEUIR/ReCUT.
KG-Infused RAG: Augmenting Corpus-Based RAG with External Knowledge Graphs
Jun 11, 2025



Retrieval-Augmented Generation (RAG) improves factual accuracy by grounding responses in external knowledge. However, existing methods typically rely on a single source, either unstructured text or structured knowledge. Moreover, they lack cognitively inspired mechanisms for activating relevant knowledge. To address these issues, we propose KG-Infused RAG, a framework that integrates KGs into RAG systems to implement spreading activation, a cognitive process that enables concept association and inference. KG-Infused RAG retrieves KG facts, expands the query accordingly, and enhances generation by combining corpus passages with structured facts, enabling interpretable, multi-source retrieval grounded in semantic structure. We further improve KG-Infused RAG via preference learning on sampled key stages in the pipeline. Experiments on five QA benchmarks show that KG-Infused RAG consistently outperforms vanilla RAG (by 3.8% to 13.8%). Additionally, when integrated into Self-RAG, KG-Infused RAG brings further performance gains, demonstrating its effectiveness and versatility as a plug-and-play enhancement module for corpus-based RAG methods.
MiniCPM4: Ultra-Efficient LLMs on End Devices
Jun 09, 2025



This paper introduces MiniCPM4, a highly efficient large language model (LLM) designed explicitly for end-side devices. We achieve this efficiency through systematic innovation in four key dimensions: model architecture, training data, training algorithms, and inference systems. Specifically, in terms of model architecture, we propose InfLLM v2, a trainable sparse attention mechanism that accelerates both prefilling and decoding phases for long-context processing. Regarding training data, we propose UltraClean, an efficient and accurate pre-training data filtering and generation strategy, and UltraChat v2, a comprehensive supervised fine-tuning dataset. These datasets enable satisfactory model performance to be achieved using just 8 trillion training tokens. Regarding training algorithms, we propose ModelTunnel v2 for efficient pre-training strategy search, and improve existing post-training methods by introducing chunk-wise rollout for load-balanced reinforcement learning and data-efficient tenary LLM, BitCPM. Regarding inference systems, we propose CPM.cu that integrates sparse attention, model quantization, and speculative sampling to achieve efficient prefilling and decoding. To meet diverse on-device requirements, MiniCPM4 is available in two versions, with 0.5B and 8B parameters, respectively. Sufficient evaluation results show that MiniCPM4 outperforms open-source models of similar size across multiple benchmarks, highlighting both its efficiency and effectiveness. Notably, MiniCPM4-8B demonstrates significant speed improvements over Qwen3-8B when processing long sequences. Through further adaptation, MiniCPM4 successfully powers diverse applications, including trustworthy survey generation and tool use with model context protocol, clearly showcasing its broad usability.
ClueAnchor: Clue-Anchored Knowledge Reasoning Exploration and Optimization for Retrieval-Augmented Generation
May 30, 2025Retrieval-Augmented Generation (RAG) augments Large Language Models (LLMs) with external knowledge to improve factuality. However, existing RAG systems frequently underutilize the retrieved documents, failing to extract and integrate the key clues needed to support faithful and interpretable reasoning, especially in cases where relevant evidence is implicit, scattered, or obscured by noise. To address this issue, we propose ClueAnchor, a novel framework for enhancing RAG via clue-anchored reasoning exploration and optimization. ClueAnchor extracts key clues from retrieved content and generates multiple reasoning paths based on different knowledge configurations, optimizing the model by selecting the most effective one through reward-based preference optimization. Experiments show that ClueAnchor significantly outperforms prior RAG baselines in reasoning completeness and robustness. Further analysis confirms its strong resilience to noisy or partially relevant retrieved content, as well as its capability to identify supporting evidence even in the absence of explicit clue supervision during inference.