 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Dataset Selection for Continual Adaptation of Generative Recommenders
Apr 09, 2026Recommendation systems must continuously adapt to evolving user behavior, yet the volume of data generated in large-scale streaming environments makes frequent full retraining impractical. This work investigates how targeted data selection can mitigate performance degradation caused by temporal distributional drift while maintaining scalability. We evaluate a range of representation choices and sampling strategies for curating small but informative subsets of user interaction data. Our results demonstrate that gradient-based representations, coupled with distribution-matching, improve downstream model performance, achieving training efficiency gains while preserving robustness to drift. These findings highlight data curation as a practical mechanism for scalable monitoring and adaptive model updates in production-scale recommendation systems.
Linking Knowledge to Care: Knowledge Graph-Augmented Medical Follow-Up Question Generation
Mar 01, 2026Clinical diagnosis is time-consuming, requiring intensive interactions between patients and medical professionals. While large language models (LLMs) could ease the pre-diagnostic workload, their limited domain knowledge hinders effective medical question generation. We introduce a Knowledge Graph-augmented LLM with active in-context learning to generate relevant and important follow-up questions, KG-Followup, serving as a critical module for the pre-diagnostic assessment. The structured medical domain knowledge graph serves as a seamless patch-up to provide professional domain expertise upon which the LLM can reason. Experiments demonstrate that KG-Followup outperforms state-of-the-art methods by 5% - 8% on relevant benchmarks in recall.
Benchmark Test-Time Scaling of General LLM Agents
Feb 22, 2026LLM agents are increasingly expected to function as general-purpose systems capable of resolving open-ended user requests. While existing benchmarks focus on domain-aware environments for developing specialized agents, evaluating general-purpose agents requires more realistic settings that challenge them to operate across multiple skills and tools within a unified environment. We introduce General AgentBench, a benchmark that provides such a unified framework for evaluating general LLM agents across search, coding, reasoning, and tool-use domains. Using General AgentBench, we systematically study test-time scaling behaviors under sequential scaling (iterative interaction) and parallel scaling (sampling multiple trajectories). Evaluation of ten leading LLM agents reveals a substantial performance degradation when moving from domain-specific evaluations to this general-agent setting. Moreover, we find that neither scaling methodology yields effective performance improvements in practice, due to two fundamental limitations: context ceiling in sequential scaling and verification gap in parallel scaling. Code is publicly available at https://github.com/cxcscmu/General-AgentBench.
Agentic Search in the Wild: Intents and Trajectory Dynamics from 14M+ Real Search Requests
Jan 24, 2026LLM-powered search agents are increasingly being used for multi-step information seeking tasks, yet the IR community lacks empirical understanding of how agentic search sessions unfold and how retrieved evidence is used. This paper presents a large-scale log analysis of agentic search based on 14.44M search requests (3.97M sessions) collected from DeepResearchGym, i.e. an open-source search API accessed by external agentic clients. We sessionize the logs, assign session-level intents and step-wise query-reformulation labels using LLM-based annotation, and propose Context-driven Term Adoption Rate (CTAR) to quantify whether newly introduced query terms are traceable to previously retrieved evidence. Our analyses reveal distinctive behavioral patterns. First, over 90% of multi-turn sessions contain at most ten steps, and 89% of inter-step intervals fall under one minute. Second, behavior varies by intent. Fact-seeking sessions exhibit high repetition that increases over time, while sessions requiring reasoning sustain broader exploration. Third, agents reuse evidence across steps. On average, 54% of newly introduced query terms appear in the accumulated evidence context, with contributions from earlier steps beyond the most recent retrieval. The findings suggest that agentic search may benefit from repetition-aware early stopping, intent-adaptive retrieval budgets, and explicit cross-step context tracking. We plan to release the anonymized logs to support future research.
ORBIT -- Open Recommendation Benchmark for Reproducible Research with Hidden Tests
Oct 30, 2025Recommender systems are among the most impactful AI applications, interacting with billions of users every day, guiding them to relevant products, services, or information tailored to their preferences. However, the research and development of recommender systems are hindered by existing datasets that fail to capture realistic user behaviors and inconsistent evaluation settings that lead to ambiguous conclusions. This paper introduces the Open Recommendation Benchmark for Reproducible Research with HIdden Tests (ORBIT), a unified benchmark for consistent and realistic evaluation of recommendation models. ORBIT offers a standardized evaluation framework of public datasets with reproducible splits and transparent settings for its public leaderboard. Additionally, ORBIT introduces a new webpage recommendation task, ClueWeb-Reco, featuring web browsing sequences from 87 million public, high-quality webpages. ClueWeb-Reco is a synthetic dataset derived from real, user-consented, and privacy-guaranteed browsing data. It aligns with modern recommendation scenarios and is reserved as the hidden test part of our leaderboard to challenge recommendation models' generalization ability. ORBIT measures 12 representative recommendation models on its public benchmark and introduces a prompted LLM baseline on the ClueWeb-Reco hidden test. Our benchmark results reflect general improvements of recommender systems on the public datasets, with variable individual performances. The results on the hidden test reveal the limitations of existing approaches in large-scale webpage recommendation and highlight the potential for improvements with LLM integrations. ORBIT benchmark, leaderboard, and codebase are available at https://www.open-reco-bench.ai.
AutoRule: Reasoning Chain-of-thought Extracted Rule-based Rewards Improve Preference Learning
Jun 18, 2025Rule-based rewards offer a promising strategy for improving reinforcement learning from human feedback (RLHF), but current approaches often rely on manual rule engineering. We present AutoRule, a fully automated method for extracting rules from preference feedback and formulating them into rule-based rewards. AutoRule extraction operates in three stages: it leverages a reasoning model to interpret user preferences, identifies candidate rules from the reasoning chain of these interpretations, and synthesizes them into a unified rule set. Leveraging the finalized rule set, we employ language-model verifiers to compute the fraction of rules satisfied by each output, using this metric as an auxiliary reward alongside the learned reward model during policy optimization. Training a Llama-3-8B model with AutoRule results in a 28.6\% relative improvement in length-controlled win rate on AlpacaEval2.0, and a 6.1\% relative gain in second-turn performance on a held-out MT-Bench subset, compared to a GRPO baseline trained with the same learned reward model but without the rule-based auxiliary reward. Our analysis confirms that the extracted rules exhibit good agreement with dataset preference. We find that AutoRule demonstrates reduced reward hacking compared to a learned reward model when run over two episodes. Finally, our case study suggests that the extracted rules capture unique qualities valued in different datasets. The extracted rules are provided in the appendix, and the code is open-sourced at https://github.com/cxcscmu/AutoRule.
Semi-structured LLM Reasoners Can Be Rigorously Audited
May 30, 2025As Large Language Models (LLMs) become increasingly capable at reasoning, the problem of "faithfulness" persists: LLM "reasoning traces" can contain errors and omissions that are difficult to detect, and may obscure biases in model outputs. To address these limitations, we introduce Semi-Structured Reasoning Models (SSRMs), which internalize a semi-structured Chain-of-Thought (CoT) reasoning format within the model. Our SSRMs generate reasoning traces in a Pythonic syntax. While SSRM traces are not executable, they adopt a restricted, task-specific vocabulary to name distinct reasoning steps, and to mark each step's inputs and outputs. Through extensive evaluation on ten benchmarks, SSRMs demonstrate strong performance and generality: they outperform comparably sized baselines by nearly ten percentage points on in-domain tasks while remaining competitive with specialized models on out-of-domain medical benchmarks. Furthermore, we show that semi-structured reasoning is more amenable to analysis: in particular, they can be automatically audited to identify reasoning flaws. We explore both hand-crafted structured audits, which detect task-specific problematic reasoning patterns, and learned typicality audits, which apply probabilistic models over reasoning patterns, and show that both audits can be used to effectively flag probable reasoning errors.
ConsRec: Denoising Sequential Recommendation through User-Consistent Preference Modeling
May 28, 2025User-item interaction histories are pivotal for sequential recommendation systems but often include noise, such as unintended clicks or actions that fail to reflect genuine user preferences. To address this issue, we propose the User-Consistent Preference-based Sequential Recommendation System (ConsRec), designed to capture stable user preferences and filter noisy items from interaction histories. Specifically, ConsRec constructs a user-interacted item graph, learns item similarities from their text representations, and then extracts the maximum connected subgraph from the user-interacted item graph for denoising items. Experimental results on the Yelp and Amazon Product datasets illustrate that ConsRec achieves a 13% improvement over baseline recommendation models, showing its effectiveness in denoising user-interacted items. Further analysis reveals that the denoised interaction histories form semantically tighter clusters of user-preferred items, leading to higher relevance scores for ground-truth targets and more accurate recommendations. All codes are available at https://github.com/NEUIR/ConsRec.
FLAME-MoE: A Transparent End-to-End Research Platform for Mixture-of-Experts Language Models
May 26, 2025Recent large language models such as Gemini-1.5, DeepSeek-V3, and Llama-4 increasingly adopt Mixture-of-Experts (MoE) architectures, which offer strong efficiency-performance trade-offs by activating only a fraction of the model per token. Yet academic researchers still lack a fully open, end-to-end MoE platform for investigating scaling, routing, and expert behavior. We release FLAME-MoE, a completely open-source research suite composed of seven decoder-only models, ranging from 38M to 1.7B active parameters, whose architecture--64 experts with top-8 gating and 2 shared experts--closely reflects modern production LLMs. All training data pipelines, scripts, logs, and checkpoints are publicly available to enable reproducible experimentation. Across six evaluation tasks, FLAME-MoE improves average accuracy by up to 3.4 points over dense baselines trained with identical FLOPs. Leveraging full training trace transparency, we present initial analyses showing that (i) experts increasingly specialize on distinct token subsets, (ii) co-activation matrices remain sparse, reflecting diverse expert usage, and (iii) routing behavior stabilizes early in training. All code, training logs, and model checkpoints are available at https://github.com/cmu-flame/FLAME-MoE.
DeepResearchGym: A Free, Transparent, and Reproducible Evaluation Sandbox for Deep Research
May 25, 2025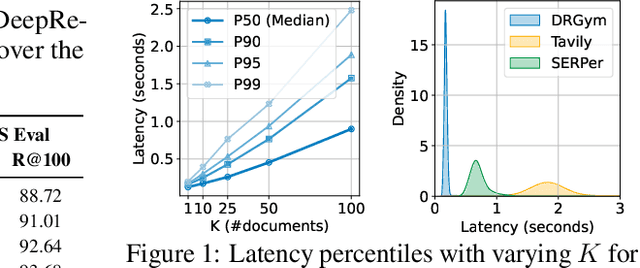
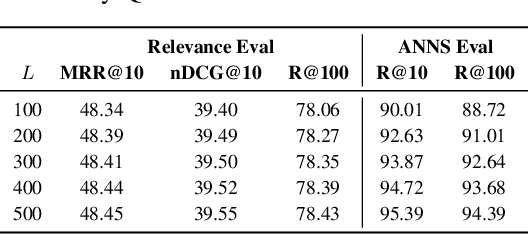
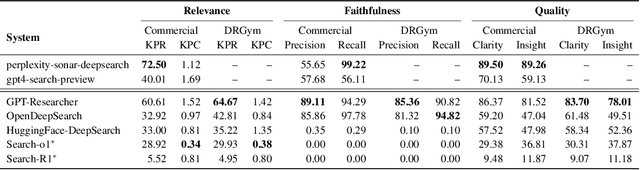
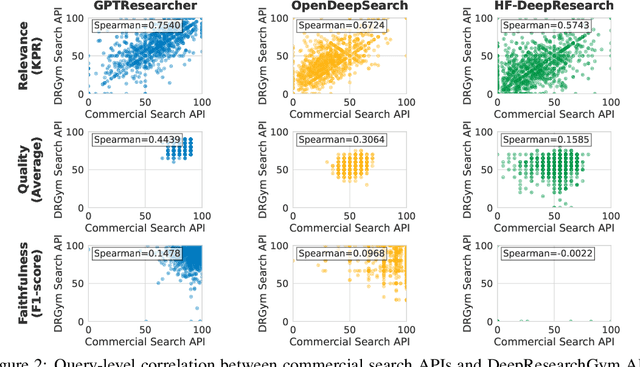
Deep research systems represent an emerging class of agentic information retrieval methods that generate comprehensive and well-supported reports to complex queries. However, most existing frameworks rely on dynamic commercial search APIs, which pose reproducibility and transparency challenges in addition to their cost. To address these limitations, we introduce DeepResearchGym, an open-source sandbox that combines a reproducible search API with a rigorous evaluation protocol for benchmarking deep research systems. The API indexes large-scale public web corpora, namely ClueWeb22 and FineWeb, using a state-of-the-art dense retriever and approximate nearest neighbor search via DiskANN. It achieves lower latency than popular commercial APIs while ensuring stable document rankings across runs, and is freely available for research use. To evaluate deep research systems' outputs, we extend the Researchy Questions benchmark with automatic metrics through LLM-as-a-judge assessments to measure alignment with users' information needs, retrieval faithfulness, and report quality. Experimental results show that systems integrated with DeepResearchGym achieve performance comparable to those using commercial APIs, with performance rankings remaining consistent across evaluation metrics. A human evaluation study further confirms that our automatic protocol aligns with human preferences, validating the framework's ability to help support controlled assessment of deep research systems. Our code and API documentation are available at https://www.deepresearchgym.ai.