 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCraw4LLM: Efficient Web Crawling for LLM Pretraining
Paper and Code
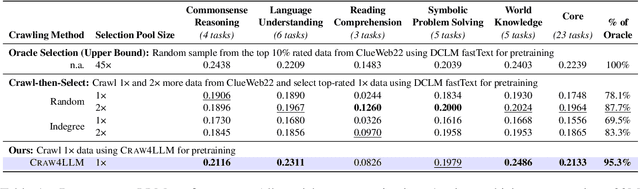

Web crawl is a main source of large language models' (LLMs) pretraining data, but the majority of crawled web pages are discarded in pretraining due to low data quality. This paper presents Crawl4LLM, an efficient web crawling method that explores the web graph based on the preference of LLM pretraining. Specifically, it leverages the influence of a webpage in LLM pretraining as the priority score of the web crawler's scheduler, replacing the standard graph connectivity based priority. Our experiments on a web graph containing 900 million webpages from a commercial search engine's index demonstrate the efficiency of Crawl4LLM in obtaining high-quality pretraining data. With just 21% URLs crawled, LLMs pretrained on Crawl4LLM data reach the same downstream performances of previous crawls, significantly reducing the crawling waste and alleviating the burdens on websites. Our code is publicly available at https://github.com/cxcscmu/Crawl4LLM.