 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFLAME-MoE: A Transparent End-to-End Research Platform for Mixture-of-Experts Language Models
May 26, 2025Recent large language models such as Gemini-1.5, DeepSeek-V3, and Llama-4 increasingly adopt Mixture-of-Experts (MoE) architectures, which offer strong efficiency-performance trade-offs by activating only a fraction of the model per token. Yet academic researchers still lack a fully open, end-to-end MoE platform for investigating scaling, routing, and expert behavior. We release FLAME-MoE, a completely open-source research suite composed of seven decoder-only models, ranging from 38M to 1.7B active parameters, whose architecture--64 experts with top-8 gating and 2 shared experts--closely reflects modern production LLMs. All training data pipelines, scripts, logs, and checkpoints are publicly available to enable reproducible experimentation. Across six evaluation tasks, FLAME-MoE improves average accuracy by up to 3.4 points over dense baselines trained with identical FLOPs. Leveraging full training trace transparency, we present initial analyses showing that (i) experts increasingly specialize on distinct token subsets, (ii) co-activation matrices remain sparse, reflecting diverse expert usage, and (iii) routing behavior stabilizes early in training. All code, training logs, and model checkpoints are available at https://github.com/cmu-flame/FLAME-MoE.
Data-Efficient Pretraining with Group-Level Data Influence Modeling
Feb 20, 2025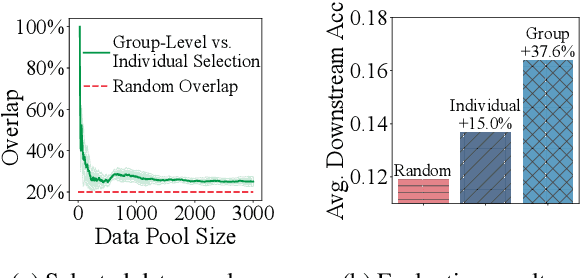
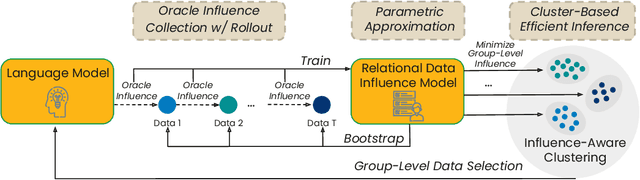
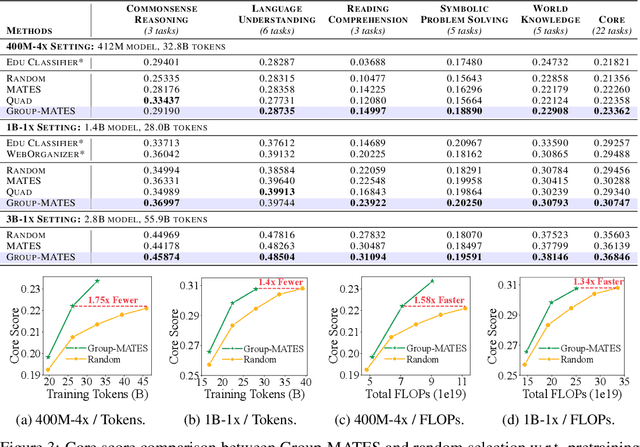
Data-efficient pretraining has shown tremendous potential to elevate scaling laws. This paper argues that effective pretraining data should be curated at the group level, treating a set of data points as a whole rather than as independent contributors. To achieve that, we propose Group-Level Data Influence Modeling (Group-MATES), a novel data-efficient pretraining method that captures and optimizes group-level data utility. Specifically, Group-MATES collects oracle group-level influences by locally probing the pretraining model with data sets. It then fine-tunes a relational data influence model to approximate oracles as relationship-weighted aggregations of individual influences. The fine-tuned model selects the data subset by maximizing its group-level influence prediction, with influence-aware clustering to enable efficient inference. Experiments on the DCLM benchmark demonstrate that Group-MATES achieves a 10% relative core score improvement on 22 downstream tasks over DCLM-Baseline and 5% over individual-influence-based methods, establishing a new state-of-the-art. Further analyses highlight the effectiveness of relational data influence models in capturing intricate interactions between data points.
Efficient Multi-Agent System Training with Data Influence-Oriented Tree Search
Feb 02, 2025



Monte Carlo Tree Search (MCTS) based methods provide promising approaches for generating synthetic data to enhance the self-training of Large Language Model (LLM) based multi-agent systems (MAS). These methods leverage Q-values to estimate individual agent contributions. However, relying solely on Q-values to identify informative data may misalign with the data synthesis objective, as the focus should be on selecting data that best enhances model training. To address this discrepancy, we propose Data Influence-oriented Tree Search (DITS), a novel framework that incorporates influence scores to guide both tree search and data selection. By leveraging influence scores, we effectively identify the most impactful data for system improvement, thereby enhancing model performance. Furthermore, we derive influence score estimation methods tailored for non-differentiable metrics, significantly reducing computational overhead by utilizing inference computations. Extensive experiments on eight multi-agent datasets demonstrate the robustness and effectiveness of the proposed methods. Notably, our findings reveal that allocating more inference resources to estimate influence scores, rather than Q-values, during data synthesis can more effectively and efficiently enhance model training.
Montessori-Instruct: Generate Influential Training Data Tailored for Student Learning
Oct 18, 2024Synthetic data has been widely used to train large language models, but their generative nature inevitably introduces noisy, non-informative, and misleading learning signals. In this paper, we propose Montessori-Instruct, a novel data synthesis framework that tailors the data synthesis ability of the teacher language model toward the student language model's learning process. Specifically, we utilize local data influence of synthetic training data points on students to characterize students' learning preferences. Then, we train the teacher model with Direct Preference Optimization (DPO) to generate synthetic data tailored toward student learning preferences. Experiments with Llama3-8B-Instruct (teacher) and Llama3-8B (student) on Alpaca Eval and MT-Bench demonstrate that Montessori-Instruct significantly outperforms standard synthesis methods by 18.35\% and 46.24\% relatively. Our method also beats data synthesized by a stronger teacher model, GPT-4o. Further analysis confirms the benefits of teacher's learning to generate more influential training data in the student's improved learning, the advantages of local data influence in accurately measuring student preferences, and the robustness of Montessori-Instruct across different student models. Our code and data are open-sourced at https://github.com/cxcscmu/Montessori-Instruct.
MATES: Model-Aware Data Selection for Efficient Pretraining with Data Influence Models
Jun 10, 2024Pretraining data selection has the potential to improve language model pretraining efficiency by utilizing higher-quality data from massive web data corpora. Current data selection methods, which rely on either hand-crafted rules or larger reference models, are conducted statically and do not capture the evolving data preferences during pretraining. In this paper, we introduce model-aware data selection with data influence models (MATES), where a data influence model continuously adapts to the evolving data preferences of the pretraining model and then selects the data most effective for the current pretraining progress. Specifically, we fine-tune a small data influence model to approximate oracle data preference signals collected by locally probing the pretraining model and to select data accordingly for the next pretraining stage. Experiments on Pythia and the C4 dataset demonstrate that MATES significantly outperforms random data selection on extensive downstream tasks in both zero- and few-shot settings. It doubles the gains achieved by recent data selection approaches that leverage larger reference models and reduces the total FLOPs required to reach certain performances by half. Further analysis validates the ever-changing data preferences of pretraining models and the effectiveness of our data influence models to capture them. Our code is open-sourced at https://github.com/cxcscmu/MATES.
An In-depth Look at Gemini's Language Abilities
Dec 24, 2023The recently released Google Gemini class of models are the first to comprehensively report results that rival the OpenAI GPT series across a wide variety of tasks. In this paper, we do an in-depth exploration of Gemini's language abilities, making two contributions. First, we provide a third-party, objective comparison of the abilities of the OpenAI GPT and Google Gemini models with reproducible code and fully transparent results. Second, we take a closer look at the results, identifying areas where one of the two model classes excels. We perform this analysis over 10 datasets testing a variety of language abilities, including reasoning, answering knowledge-based questions, solving math problems, translating between languages, generating code, and acting as instruction-following agents. From this analysis, we find that Gemini Pro achieves accuracy that is close but slightly inferior to the corresponding GPT 3.5 Turbo on all tasks that we benchmarked. We further provide explanations for some of this under-performance, including failures in mathematical reasoning with many digits, sensitivity to multiple-choice answer ordering, aggressive content filtering, and others. We also identify areas where Gemini demonstrates comparably high performance, including generation into non-English languages, and handling longer and more complex reasoning chains. Code and data for reproduction can be found at https://github.com/neulab/gemini-benchmark
Augmentation-Adapted Retriever Improves Generalization of Language Models as Generic Plug-In
May 27, 2023Retrieval augmentation can aid language models (LMs) in knowledge-intensive tasks by supplying them with external information. Prior works on retrieval augmentation usually jointly fine-tune the retriever and the LM, making them closely coupled. In this paper, we explore the scheme of generic retrieval plug-in: the retriever is to assist target LMs that may not be known beforehand or are unable to be fine-tuned together. To retrieve useful documents for unseen target LMs, we propose augmentation-adapted retriever (AAR), which learns LM's preferences obtained from a known source LM. Experiments on the MMLU and PopQA datasets demonstrate that our AAR trained with a small source LM is able to significantly improve the zero-shot generalization of larger target LMs ranging from 250M Flan-T5 to 175B InstructGPT. Further analysis indicates that the preferences of different LMs overlap, enabling AAR trained with a single source LM to serve as a generic plug-in for various target LMs. Our code is open-sourced at https://github.com/OpenMatch/Augmentation-Adapted-Retriever.
Automatic Label Sequence Generation for Prompting Sequence-to-sequence Models
Sep 20, 2022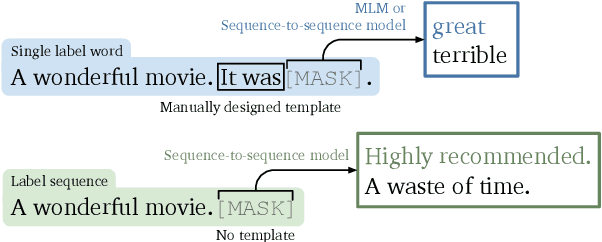
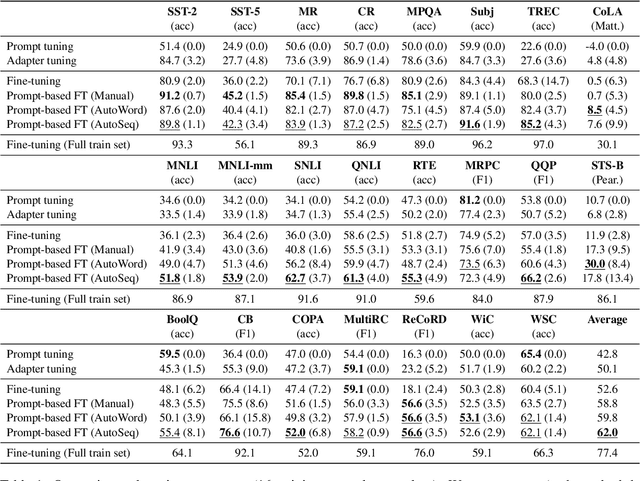


Prompting, which casts downstream applications as language modeling tasks, has shown to be sample efficient compared to standard fine-tuning with pre-trained models. However, one pitfall of prompting is the need of manually-designed patterns, whose outcome can be unintuitive and requires large validation sets to tune. To tackle the challenge, we propose AutoSeq, a fully automatic prompting method: (1) We adopt natural language prompts on sequence-to-sequence models, enabling free-form generation and larger label search space; (2) We propose label sequences -- phrases with indefinite lengths to verbalize the labels -- which eliminate the need of manual templates and are more expressive than single label words; (3) We use beam search to automatically generate a large amount of label sequence candidates and propose contrastive re-ranking to get the best combinations. AutoSeq significantly outperforms other no-manual-design methods, such as soft prompt tuning, adapter tuning, and automatic search on single label words; the generated label sequences are even better than curated manual ones on a variety of tasks. Our method reveals the potential of sequence-to-sequence models in few-shot learning and sheds light on a path to generic and automatic prompting. The source code of this paper can be obtained from https://github.com/thunlp/Seq2Seq-Prompt.