 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLaTTE: Scaling Laws for Multi-Stage Sequence Modeling in Large-Scale Ads Recommendation
Jan 27, 2026We present LLaTTE (LLM-Style Latent Transformers for Temporal Events), a scalable transformer architecture for production ads recommendation. Through systematic experiments, we demonstrate that sequence modeling in recommendation systems follows predictable power-law scaling similar to LLMs. Crucially, we find that semantic features bend the scaling curve: they are a prerequisite for scaling, enabling the model to effectively utilize the capacity of deeper and longer architectures. To realize the benefits of continued scaling under strict latency constraints, we introduce a two-stage architecture that offloads the heavy computation of large, long-context models to an asynchronous upstream user model. We demonstrate that upstream improvements transfer predictably to downstream ranking tasks. Deployed as the largest user model at Meta, this multi-stage framework drives a 4.3\% conversion uplift on Facebook Feed and Reels with minimal serving overhead, establishing a practical blueprint for harnessing scaling laws in industrial recommender systems.
ORBIT -- Open Recommendation Benchmark for Reproducible Research with Hidden Tests
Oct 30, 2025Recommender systems are among the most impactful AI applications, interacting with billions of users every day, guiding them to relevant products, services, or information tailored to their preferences. However, the research and development of recommender systems are hindered by existing datasets that fail to capture realistic user behaviors and inconsistent evaluation settings that lead to ambiguous conclusions. This paper introduces the Open Recommendation Benchmark for Reproducible Research with HIdden Tests (ORBIT), a unified benchmark for consistent and realistic evaluation of recommendation models. ORBIT offers a standardized evaluation framework of public datasets with reproducible splits and transparent settings for its public leaderboard. Additionally, ORBIT introduces a new webpage recommendation task, ClueWeb-Reco, featuring web browsing sequences from 87 million public, high-quality webpages. ClueWeb-Reco is a synthetic dataset derived from real, user-consented, and privacy-guaranteed browsing data. It aligns with modern recommendation scenarios and is reserved as the hidden test part of our leaderboard to challenge recommendation models' generalization ability. ORBIT measures 12 representative recommendation models on its public benchmark and introduces a prompted LLM baseline on the ClueWeb-Reco hidden test. Our benchmark results reflect general improvements of recommender systems on the public datasets, with variable individual performances. The results on the hidden test reveal the limitations of existing approaches in large-scale webpage recommendation and highlight the potential for improvements with LLM integrations. ORBIT benchmark, leaderboard, and codebase are available at https://www.open-reco-bench.ai.
Data-Efficient Pretraining with Group-Level Data Influence Modeling
Feb 20, 2025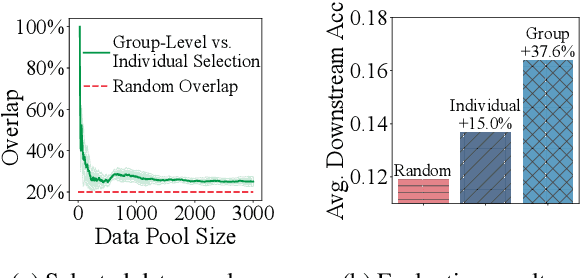
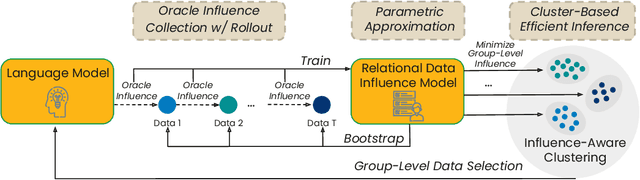
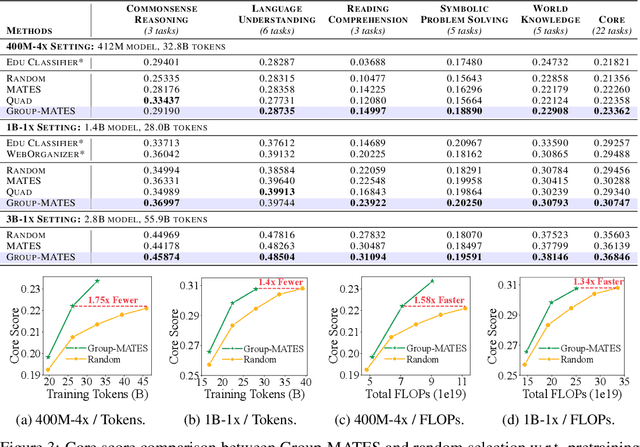
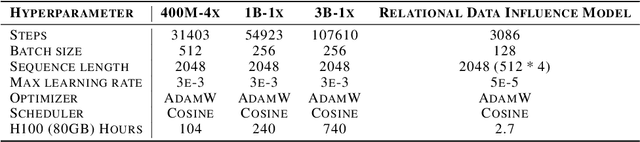
Data-efficient pretraining has shown tremendous potential to elevate scaling laws. This paper argues that effective pretraining data should be curated at the group level, treating a set of data points as a whole rather than as independent contributors. To achieve that, we propose Group-Level Data Influence Modeling (Group-MATES), a novel data-efficient pretraining method that captures and optimizes group-level data utility. Specifically, Group-MATES collects oracle group-level influences by locally probing the pretraining model with data sets. It then fine-tunes a relational data influence model to approximate oracles as relationship-weighted aggregations of individual influences. The fine-tuned model selects the data subset by maximizing its group-level influence prediction, with influence-aware clustering to enable efficient inference. Experiments on the DCLM benchmark demonstrate that Group-MATES achieves a 10% relative core score improvement on 22 downstream tasks over DCLM-Baseline and 5% over individual-influence-based methods, establishing a new state-of-the-art. Further analyses highlight the effectiveness of relational data influence models in capturing intricate interactions between data points.
Improving Multitask Retrieval by Promoting Task Specialization
Jul 01, 2023In multitask retrieval, a single retriever is trained to retrieve relevant contexts for multiple tasks. Despite its practical appeal, naive multitask retrieval lags behind task-specific retrieval in which a separate retriever is trained for each task. We show that it is possible to train a multitask retriever that outperforms task-specific retrievers by promoting task specialization. The main ingredients are: (1) a better choice of pretrained model (one that is explicitly optimized for multitasking) along with compatible prompting, and (2) a novel adaptive learning method that encourages each parameter to specialize in a particular task. The resulting multitask retriever is highly performant on the KILT benchmark. Upon analysis, we find that the model indeed learns parameters that are more task-specialized compared to naive multitasking without prompting or adaptive learning.
Augmenting Zero-Shot Dense Retrievers with Plug-in Mixture-of-Memories
Feb 07, 2023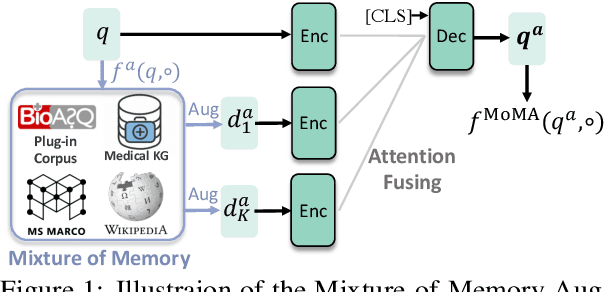
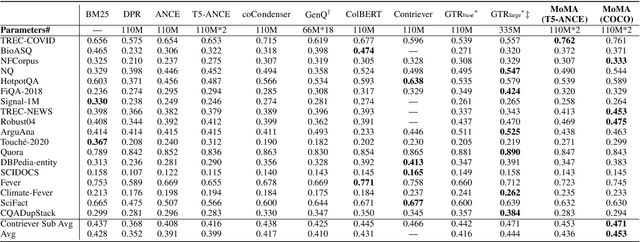
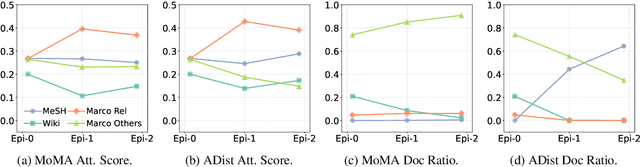
In this paper we improve the zero-shot generalization ability of language models via Mixture-Of-Memory Augmentation (MoMA), a mechanism that retrieves augmentation documents from multiple information corpora ("external memories"), with the option to "plug in" new memory at inference time. We develop a joint learning mechanism that trains the augmentation component with latent labels derived from the end retrieval task, paired with hard negatives from the memory mixture. We instantiate the model in a zero-shot dense retrieval setting by augmenting a strong T5-based retriever with MoMA. Our model, MoMA, obtains strong zero-shot retrieval accuracy on the eighteen tasks included in the standard BEIR benchmark. It outperforms systems that seek generalization from increased model parameters and computation steps. Our analysis further illustrates the necessity of augmenting with mixture-of-memory for robust generalization, the benefits of augmentation learning, and how MoMA utilizes the plug-in memory at inference time without changing its parameters. We plan to open source our code.
ClueWeb22: 10 Billion Web Documents with Visual and Semantic Information
Dec 02, 2022


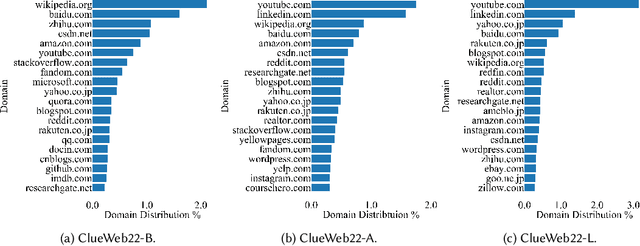
ClueWeb22, the newest iteration of the ClueWeb line of datasets, provides 10 billion web pages affiliated with rich information. Its design was influenced by the need for a high quality, large scale web corpus to support a range of academic and industry research, for example, in information systems, retrieval-augmented AI systems, and model pretraining. Compared with earlier ClueWeb corpora, the ClueWeb22 corpus is larger, more varied, of higher-quality, and aligned with the document distributions in commercial web search. Besides raw HTML, ClueWeb22 includes rich information about the web pages provided by industry-standard document understanding systems, including the visual representation of pages rendered by a web browser, parsed HTML structure information from a neural network parser, and pre-processed cleaned document text to lower the barrier to entry. Many of these signals have been widely used in industry but are available to the research community for the first time at this scale.
Reduce Catastrophic Forgetting of Dense Retrieval Training with Teleportation Negatives
Oct 31, 2022



In this paper, we investigate the instability in the standard dense retrieval training, which iterates between model training and hard negative selection using the being-trained model. We show the catastrophic forgetting phenomena behind the training instability, where models learn and forget different negative groups during training iterations. We then propose ANCE-Tele, which accumulates momentum negatives from past iterations and approximates future iterations using lookahead negatives, as "teleportations" along the time axis to smooth the learning process. On web search and OpenQA, ANCE-Tele outperforms previous state-of-the-art systems of similar size, eliminates the dependency on sparse retrieval negatives, and is competitive among systems using significantly more (50x) parameters. Our analysis demonstrates that teleportation negatives reduce catastrophic forgetting and improve convergence speed for dense retrieval training. Our code is available at https://github.com/OpenMatch/ANCE-Tele.
COCO-DR: Combating Distribution Shifts in Zero-Shot Dense Retrieval with Contrastive and Distributionally Robust Learning
Oct 27, 2022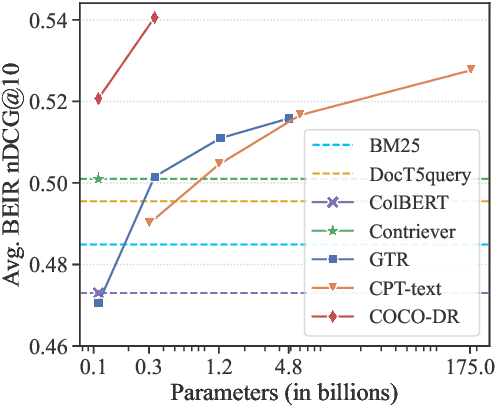
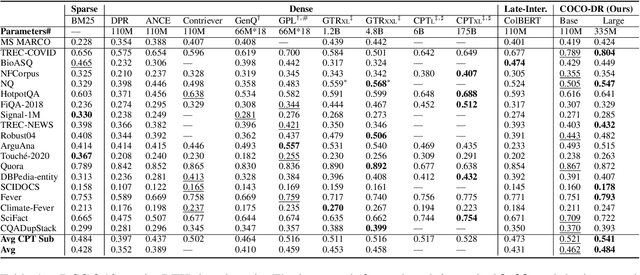
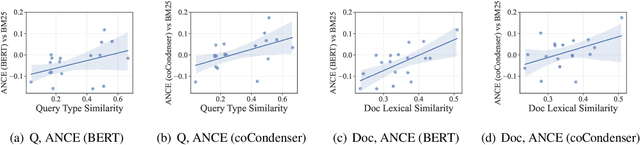
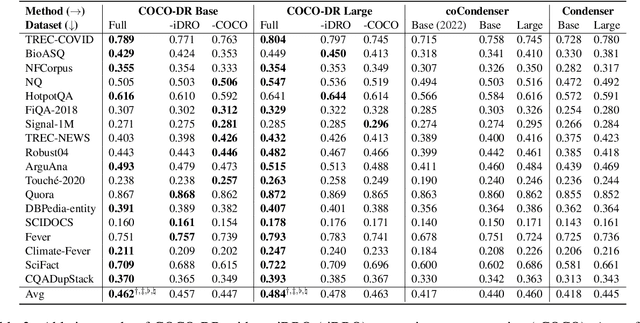
We present a new zero-shot dense retrieval (ZeroDR) method, COCO-DR, to improve the generalization ability of dense retrieval by combating the distribution shifts between source training tasks and target scenarios. To mitigate the impact of document differences, COCO-DR continues pretraining the language model on the target corpora to adapt the model to target distributions via COtinuous COtrastive learning. To prepare for unseen target queries, COCO-DR leverages implicit Distributionally Robust Optimization (iDRO) to reweight samples from different source query clusters for improving model robustness over rare queries during fine-tuning. COCO-DR achieves superior average performance on BEIR, the zero-shot retrieval benchmark. At BERT Base scale, COCO-DR Base outperforms other ZeroDR models with 60x larger size. At BERT Large scale, COCO-DR Large outperforms the giant GPT-3 embedding model which has 500x more parameters. Our analysis show the correlation between COCO-DR's effectiveness in combating distribution shifts and improving zero-shot accuracy. Our code and model can be found at \url{https://github.com/OpenMatch/COCO-DR}.
* EMNLP 2022 Main Conference (Code and Model can be found at https://github.com/OpenMatch/COCO-DR)
Less is More: Pre-training a Strong Siamese Encoder Using a Weak Decoder
Feb 18, 2021
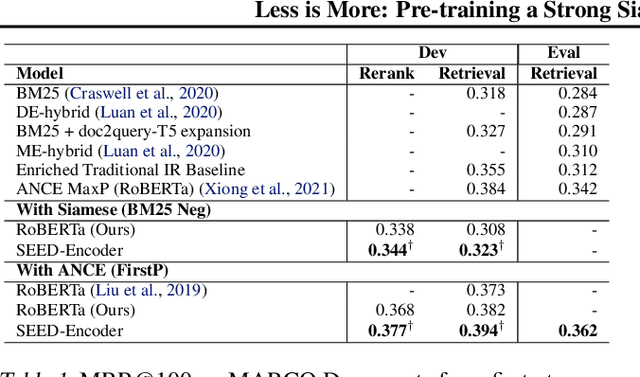
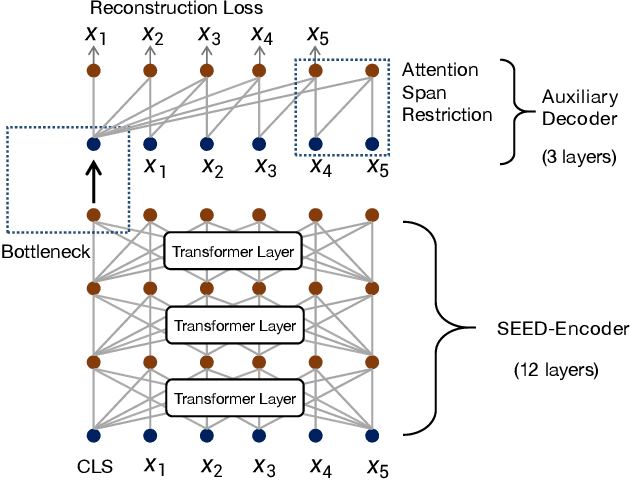
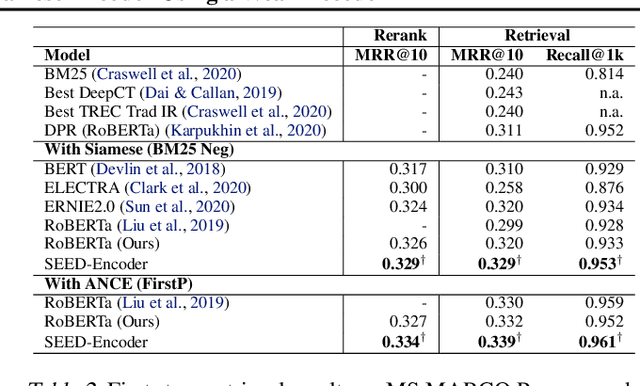
Many real-world applications use Siamese networks to efficiently match text sequences at scale, which require high-quality sequence encodings. This paper pre-trains language models dedicated to sequence matching in Siamese architectures. We first hypothesize that a representation is better for sequence matching if the entire sequence can be reconstructed from it, which, however, is unlikely to be achieved in standard autoencoders: A strong decoder can rely on its capacity and natural language patterns to reconstruct and bypass the needs of better sequence encodings. Therefore we propose a new self-learning method that pretrains the encoder with a weak decoder, which reconstructs the original sequence from the encoder's [CLS] representations but is restricted in both capacity and attention span. In our experiments on web search and recommendation, the pre-trained SEED-Encoder, "SiamEsE oriented encoder by reconstructing from weak decoder", shows significantly better generalization ability when fine-tuned in Siamese networks, improving overall accuracy and few-shot performances. Our code and models will be released.
Approximate Nearest Neighbor Negative Contrastive Learning for Dense Text Retrieval
Jul 01, 2020
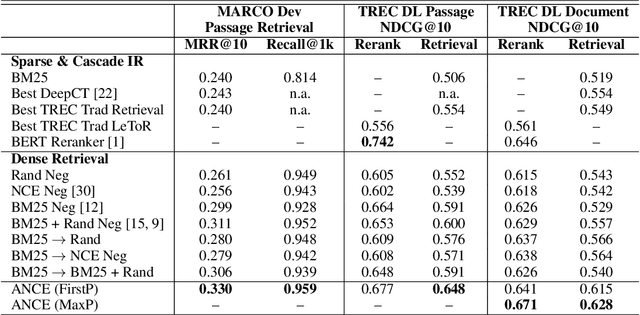
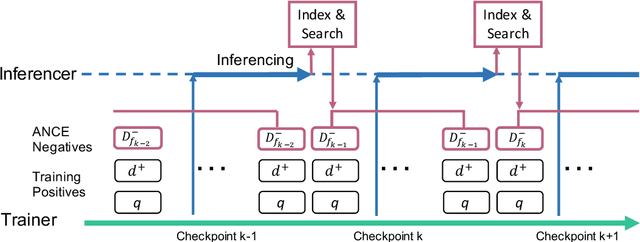

Conducting text retrieval in a dense learned representation space has many intriguing advantages over sparse retrieval. Yet the effectiveness of dense retrieval (DR) often requires combination with sparse retrieval. In this paper, we identify that the main bottleneck is in the training mechanisms, where the negative instances used in training are not representative of the irrelevant documents in testing. This paper presents Approximate nearest neighbor Negative Contrastive Estimation (ANCE), a training mechanism that constructs negatives from an Approximate Nearest Neighbor (ANN) index of the corpus, which is parallelly updated with the learning process to select more realistic negative training instances. This fundamentally resolves the discrepancy between the data distribution used in the training and testing of DR. In our experiments, ANCE boosts the BERT-Siamese DR model to outperform all competitive dense and sparse retrieval baselines. It nearly matches the accuracy of sparse-retrieval-and-BERT-reranking using dot-product in the ANCE-learned representation space and provides almost 100x speed-up.