 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Dataset Selection for Continual Adaptation of Generative Recommenders
Apr 09, 2026Recommendation systems must continuously adapt to evolving user behavior, yet the volume of data generated in large-scale streaming environments makes frequent full retraining impractical. This work investigates how targeted data selection can mitigate performance degradation caused by temporal distributional drift while maintaining scalability. We evaluate a range of representation choices and sampling strategies for curating small but informative subsets of user interaction data. Our results demonstrate that gradient-based representations, coupled with distribution-matching, improve downstream model performance, achieving training efficiency gains while preserving robustness to drift. These findings highlight data curation as a practical mechanism for scalable monitoring and adaptive model updates in production-scale recommendation systems.
MS MARCO Web Search: a Large-scale Information-rich Web Dataset with Millions of Real Click Labels
May 13, 2024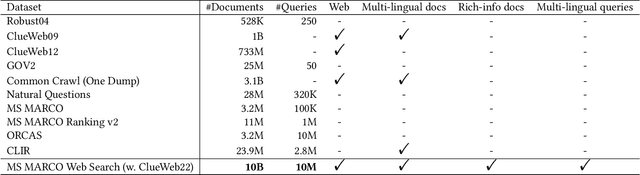
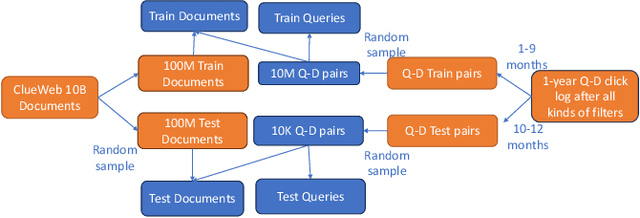
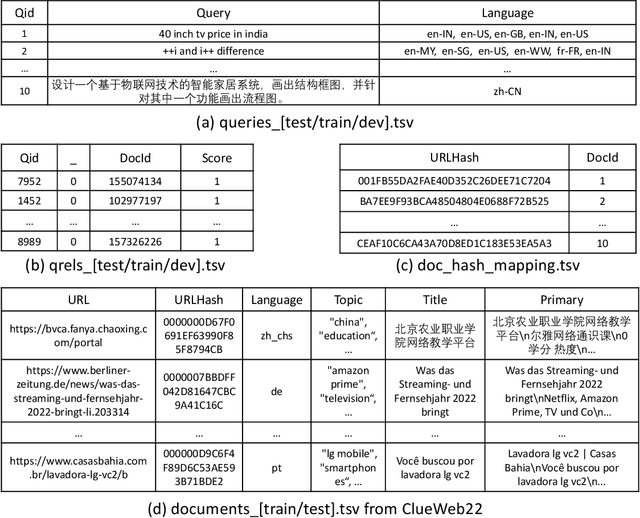
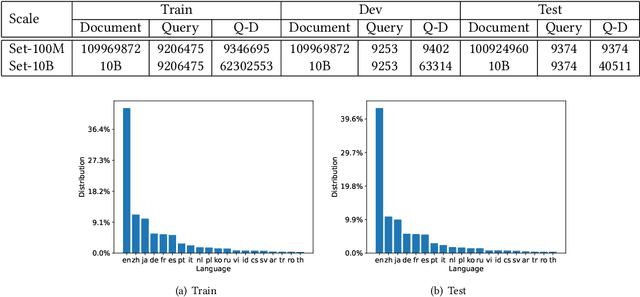
Recent breakthroughs in large models have highlighted the critical significance of data scale, labels and modals. In this paper, we introduce MS MARCO Web Search, the first large-scale information-rich web dataset, featuring millions of real clicked query-document labels. This dataset closely mimics real-world web document and query distribution, provides rich information for various kinds of downstream tasks and encourages research in various areas, such as generic end-to-end neural indexer models, generic embedding models, and next generation information access system with large language models. MS MARCO Web Search offers a retrieval benchmark with three web retrieval challenge tasks that demand innovations in both machine learning and information retrieval system research domains. As the first dataset that meets large, real and rich data requirements, MS MARCO Web Search paves the way for future advancements in AI and system research. MS MARCO Web Search dataset is available at: https://github.com/microsoft/MS-MARCO-Web-Search.
Axiomatic Preference Modeling for Longform Question Answering
Dec 02, 2023



The remarkable abilities of large language models (LLMs) like GPT-4 partially stem from post-training processes like Reinforcement Learning from Human Feedback (RLHF) involving human preferences encoded in a reward model. However, these reward models (RMs) often lack direct knowledge of why, or under what principles, the preferences annotations were made. In this study, we identify principles that guide RMs to better align with human preferences, and then develop an axiomatic framework to generate a rich variety of preference signals to uphold them. We use these axiomatic signals to train a model for scoring answers to longform questions. Our approach yields a Preference Model with only about 220M parameters that agrees with gold human-annotated preference labels more often than GPT-4. The contributions of this work include: training a standalone preference model that can score human- and LLM-generated answers on the same scale; developing an axiomatic framework for generating training data pairs tailored to certain principles; and showing that a small amount of axiomatic signals can help small models outperform GPT-4 in preference scoring. We release our model on huggingface: https://huggingface.co/corbyrosset/axiomatic_preference_model
ArK: Augmented Reality with Knowledge Interactive Emergent Ability
May 01, 2023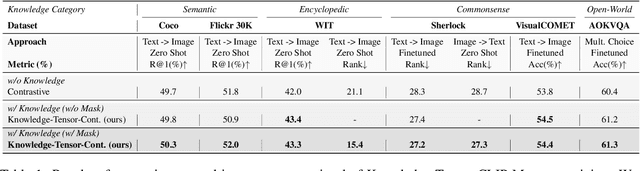
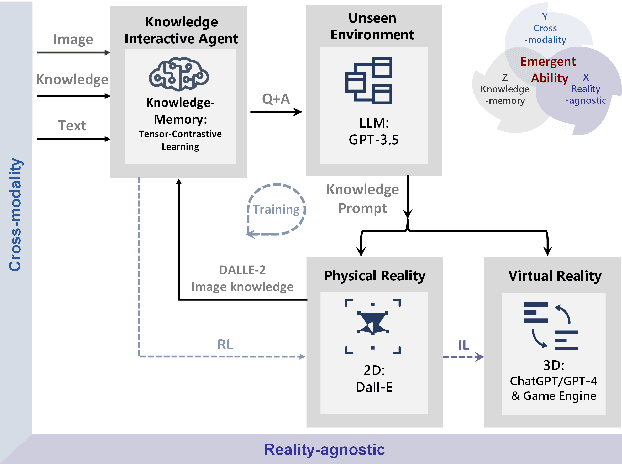

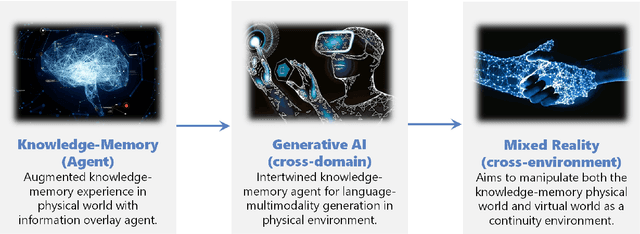
Despite the growing adoption of mixed reality and interactive AI agents, it remains challenging for these systems to generate high quality 2D/3D scenes in unseen environments. The common practice requires deploying an AI agent to collect large amounts of data for model training for every new task. This process is costly, or even impossible, for many domains. In this study, we develop an infinite agent that learns to transfer knowledge memory from general foundation models (e.g. GPT4, DALLE) to novel domains or scenarios for scene understanding and generation in the physical or virtual world. The heart of our approach is an emerging mechanism, dubbed Augmented Reality with Knowledge Inference Interaction (ArK), which leverages knowledge-memory to generate scenes in unseen physical world and virtual reality environments. The knowledge interactive emergent ability (Figure 1) is demonstrated as the observation learns i) micro-action of cross-modality: in multi-modality models to collect a large amount of relevant knowledge memory data for each interaction task (e.g., unseen scene understanding) from the physical reality; and ii) macro-behavior of reality-agnostic: in mix-reality environments to improve interactions that tailor to different characterized roles, target variables, collaborative information, and so on. We validate the effectiveness of ArK on the scene generation and editing tasks. We show that our ArK approach, combined with large foundation models, significantly improves the quality of generated 2D/3D scenes, compared to baselines, demonstrating the potential benefit of incorporating ArK in generative AI for applications such as metaverse and gaming simulation.
Understanding Causality with Large Language Models: Feasibility and Opportunities
Apr 11, 2023
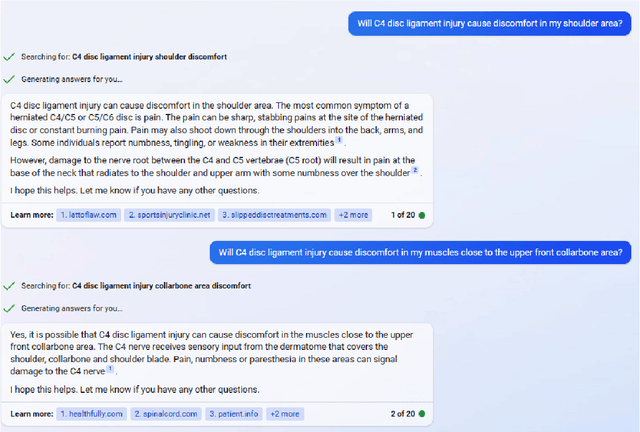
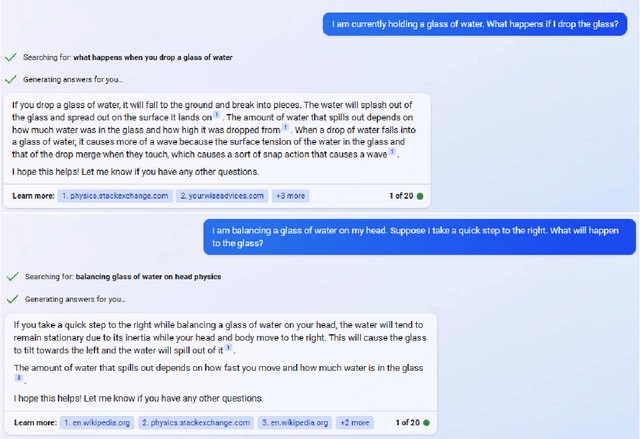
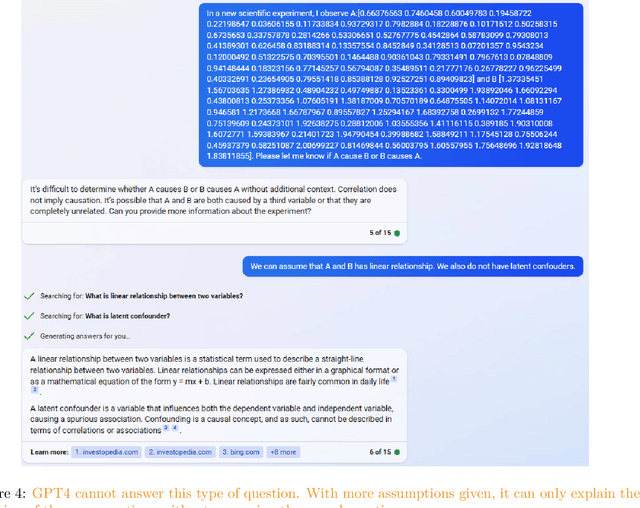
We assess the ability of large language models (LLMs) to answer causal questions by analyzing their strengths and weaknesses against three types of causal question. We believe that current LLMs can answer causal questions with existing causal knowledge as combined domain experts. However, they are not yet able to provide satisfactory answers for discovering new knowledge or for high-stakes decision-making tasks with high precision. We discuss possible future directions and opportunities, such as enabling explicit and implicit causal modules as well as deep causal-aware LLMs. These will not only enable LLMs to answer many different types of causal questions for greater impact but also enable LLMs to be more trustworthy and efficient in general.
Augmenting Zero-Shot Dense Retrievers with Plug-in Mixture-of-Memories
Feb 07, 2023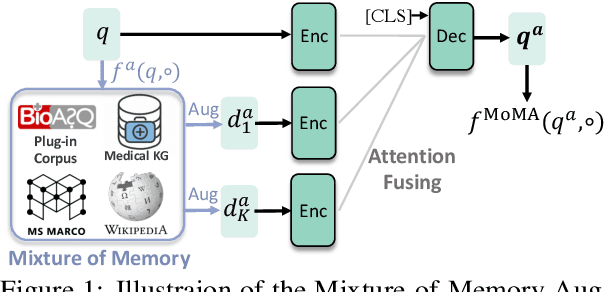
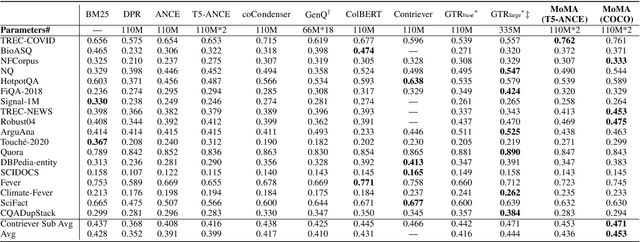
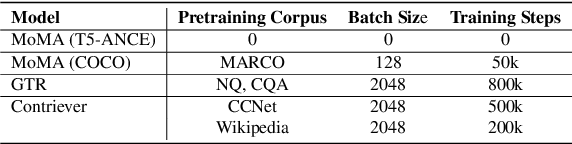
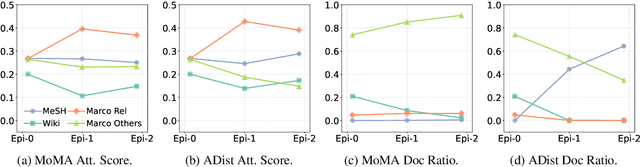
In this paper we improve the zero-shot generalization ability of language models via Mixture-Of-Memory Augmentation (MoMA), a mechanism that retrieves augmentation documents from multiple information corpora ("external memories"), with the option to "plug in" new memory at inference time. We develop a joint learning mechanism that trains the augmentation component with latent labels derived from the end retrieval task, paired with hard negatives from the memory mixture. We instantiate the model in a zero-shot dense retrieval setting by augmenting a strong T5-based retriever with MoMA. Our model, MoMA, obtains strong zero-shot retrieval accuracy on the eighteen tasks included in the standard BEIR benchmark. It outperforms systems that seek generalization from increased model parameters and computation steps. Our analysis further illustrates the necessity of augmenting with mixture-of-memory for robust generalization, the benefits of augmentation learning, and how MoMA utilizes the plug-in memory at inference time without changing its parameters. We plan to open source our code.
METRO: Efficient Denoising Pretraining of Large Scale Autoencoding Language Models with Model Generated Signals
Apr 16, 2022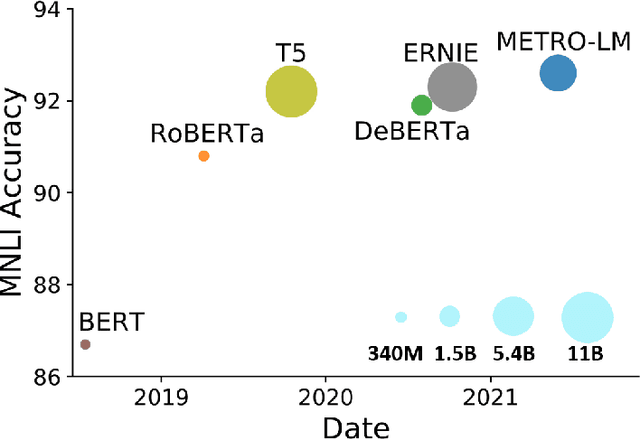
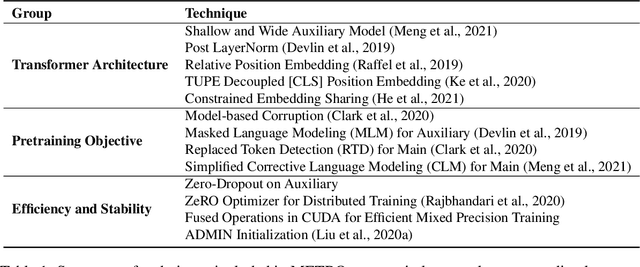
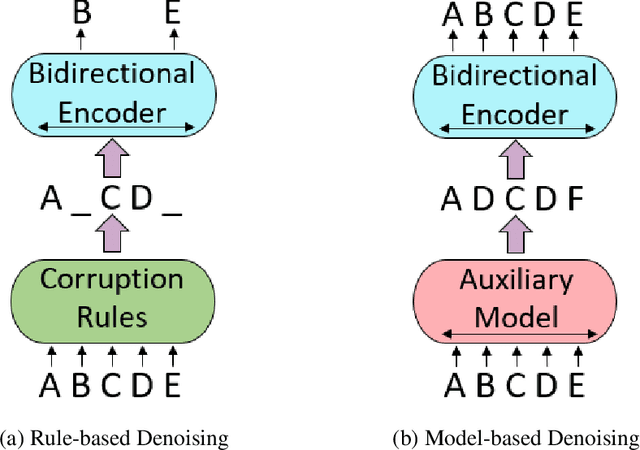
We present an efficient method of pretraining large-scale autoencoding language models using training signals generated by an auxiliary model. Originated in ELECTRA, this training strategy has demonstrated sample-efficiency to pretrain models at the scale of hundreds of millions of parameters. In this work, we conduct a comprehensive empirical study, and propose a recipe, namely "Model generated dEnoising TRaining Objective" (METRO), which incorporates some of the best modeling techniques developed recently to speed up, stabilize, and enhance pretrained language models without compromising model effectiveness. The resultant models, METRO-LM, consisting of up to 5.4 billion parameters, achieve new state-of-the-art on the GLUE, SuperGLUE, and SQuAD benchmarks. More importantly, METRO-LM are efficient in that they often outperform previous large models with significantly smaller model sizes and lower pretraining cost.
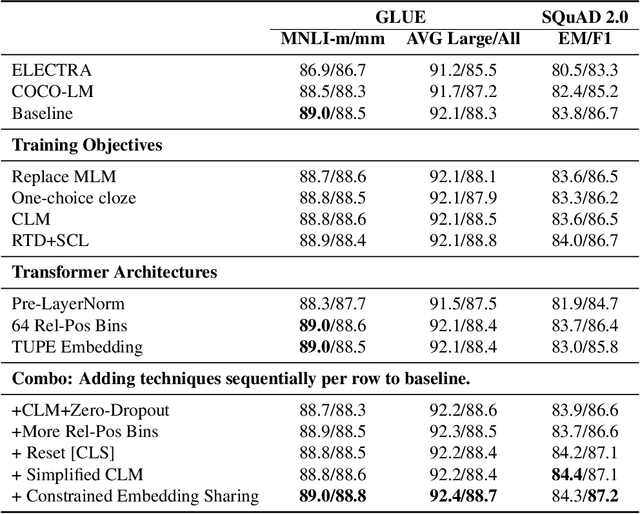
Pretraining Text Encoders with Adversarial Mixture of Training Signal Generators
Apr 07, 2022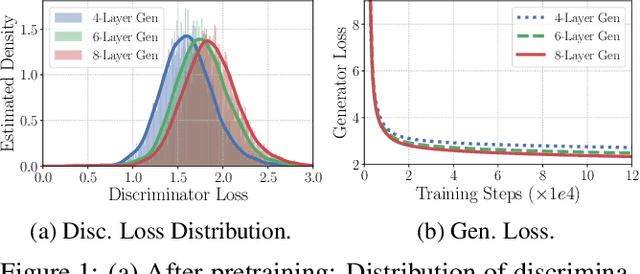
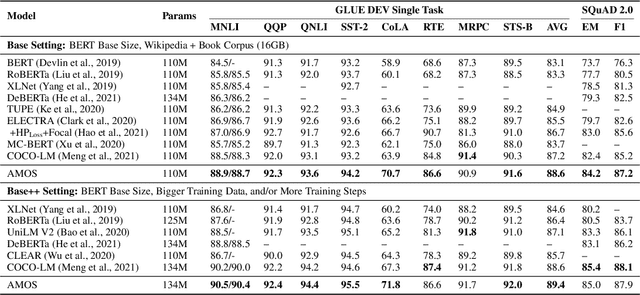
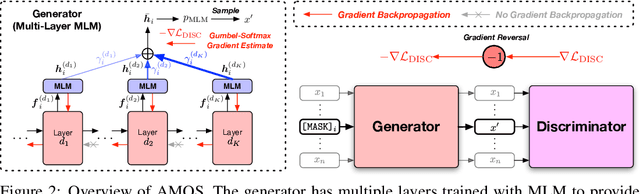
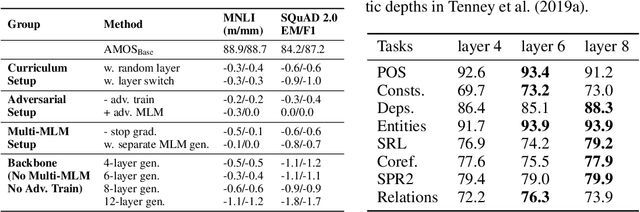
We present a new framework AMOS that pretrains text encoders with an Adversarial learning curriculum via a Mixture Of Signals from multiple auxiliary generators. Following ELECTRA-style pretraining, the main encoder is trained as a discriminator to detect replaced tokens generated by auxiliary masked language models (MLMs). Different from ELECTRA which trains one MLM as the generator, we jointly train multiple MLMs of different sizes to provide training signals at various levels of difficulty. To push the discriminator to learn better with challenging replaced tokens, we learn mixture weights over the auxiliary MLMs' outputs to maximize the discriminator loss by backpropagating the gradient from the discriminator via Gumbel-Softmax. For better pretraining efficiency, we propose a way to assemble multiple MLMs into one unified auxiliary model. AMOS outperforms ELECTRA and recent state-of-the-art pretrained models by about 1 point on the GLUE benchmark for BERT base-sized models.
Neural Approaches to Conversational Information Retrieval
Jan 13, 2022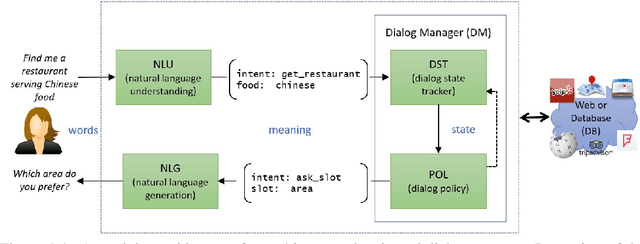
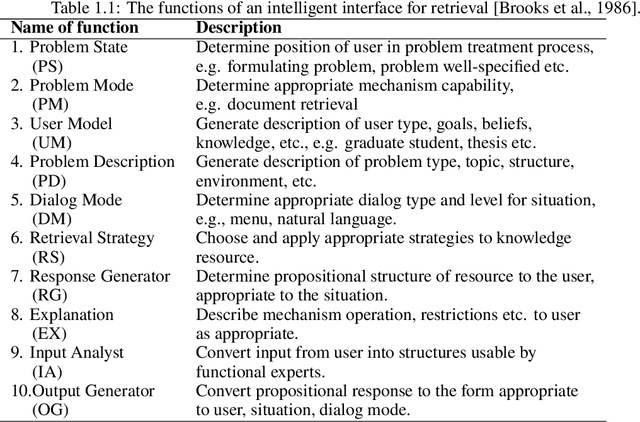

A conversational information retrieval (CIR) system is an information retrieval (IR) system with a conversational interface which allows users to interact with the system to seek information via multi-turn conversations of natural language, in spoken or written form. Recent progress in deep learning has brought tremendous improvements in natural language processing (NLP) and conversational AI, leading to a plethora of commercial conversational services that allow naturally spoken and typed interaction, increasing the need for more human-centric interactions in IR. As a result, we have witnessed a resurgent interest in developing modern CIR systems in both research communities and industry. This book surveys recent advances in CIR, focusing on neural approaches that have been developed in the last few years. This book is based on the authors' tutorial at SIGIR'2020 (Gao et al., 2020b), with IR and NLP communities as the primary target audience. However, audiences with other background, such as machine learning and human-computer interaction, will also find it an accessible introduction to CIR. We hope that this book will prove a valuable resource for students, researchers, and software developers. This manuscript is a working draft. Comments are welcome.
Keep it Simple: Unsupervised Simplification of Multi-Paragraph Text
Jul 07, 2021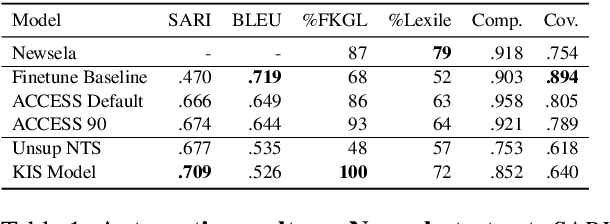
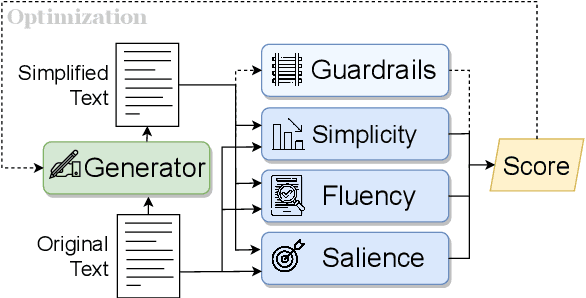
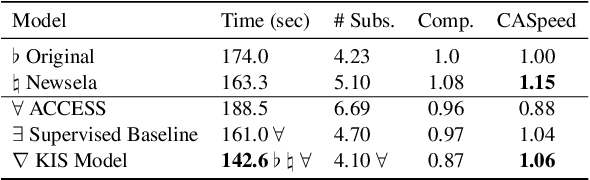

This work presents Keep it Simple (KiS), a new approach to unsupervised text simplification which learns to balance a reward across three properties: fluency, salience and simplicity. We train the model with a novel algorithm to optimize the reward (k-SCST), in which the model proposes several candidate simplifications, computes each candidate's reward, and encourages candidates that outperform the mean reward. Finally, we propose a realistic text comprehension task as an evaluation method for text simplification. When tested on the English news domain, the KiS model outperforms strong supervised baselines by more than 4 SARI points, and can help people complete a comprehension task an average of 18% faster while retaining accuracy, when compared to the original text. Code available: https://github.com/tingofurro/keep_it_simple
* Accepted at ACL-IJCNLP 2021, 14 pages, 7 figures