 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePyramid Vector Quantization for LLMs
Oct 22, 2024


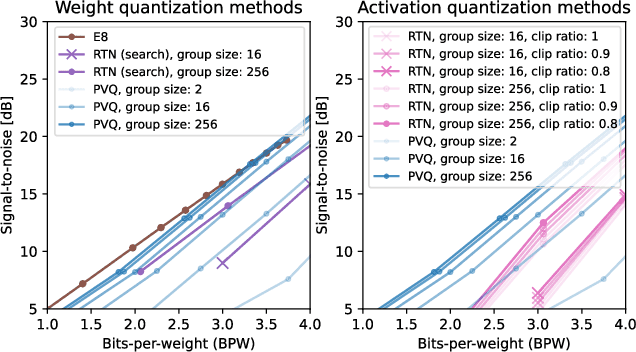
Recent works on compression of large language models (LLM) using quantization considered reparameterizing the architecture such that weights are distributed on the sphere. This demonstratively improves the ability to quantize by increasing the mathematical notion of coherence, resulting in fewer weight outliers without affecting the network output. In this work, we aim to further exploit this spherical geometry of the weights when performing quantization by considering Pyramid Vector Quantization (PVQ) for large language models. Arranging points evenly on the sphere is notoriously difficult, especially in high dimensions, and in case approximate solutions exists, representing points explicitly in a codebook is typically not feasible due to its additional memory cost. Instead, PVQ uses a fixed integer lattice on the sphere by projecting points onto the 1-sphere, which allows for efficient encoding and decoding without requiring an explicit codebook in memory. To obtain a practical algorithm, we propose to combine PVQ with scale quantization for which we derive theoretically optimal quantizations, under empirically verified assumptions. Further, we extend pyramid vector quantization to use Hessian information to minimize quantization error under expected feature activations, instead of only relying on weight magnitudes. Experimentally, we achieves state-of-the-art quantization performance with pareto-optimal trade-off between performance and bits per weight and bits per activation, compared to compared methods. On weight-only, we find that we can quantize a Llama-3 70B model to 3.25 bits per weight and retain 98\% accuracy on downstream tasks.
Zero-Shot Learning of Causal Models
Oct 08, 2024


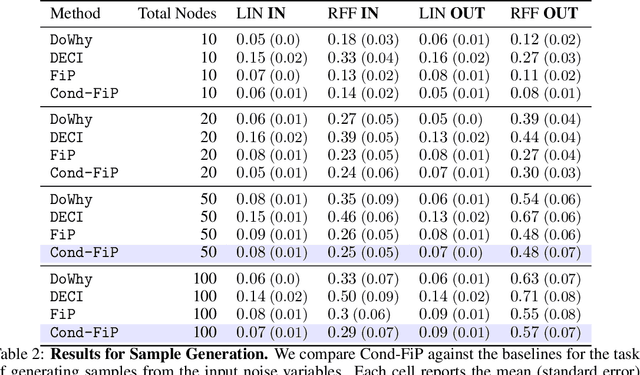
With the increasing acquisition of datasets over time, we now have access to precise and varied descriptions of the world, capturing all sorts of phenomena. These datasets can be seen as empirical observations of unknown causal generative processes, which can commonly be described by Structural Causal Models (SCMs). Recovering these causal generative processes from observations poses formidable challenges, and often require to learn a specific generative model for each dataset. In this work, we propose to learn a \emph{single} model capable of inferring in a zero-shot manner the causal generative processes of datasets. Rather than learning a specific SCM for each dataset, we enable the Fixed-Point Approach (FiP) proposed in~\cite{scetbon2024fip}, to infer the generative SCMs conditionally on their empirical representations. More specifically, we propose to amortize the learning of a conditional version of FiP to infer generative SCMs from observations and causal structures on synthetically generated datasets. We show that our model is capable of predicting in zero-shot the true generative SCMs, and as a by-product, of (i) generating new dataset samples, and (ii) inferring intervened ones. Our experiments demonstrate that our amortized procedure achieves performances on par with SoTA methods trained specifically for each dataset on both in and out-of-distribution problems. To the best of our knowledge, this is the first time that SCMs are inferred in a zero-shot manner from observations, paving the way for a paradigmatic shift towards the assimilation of causal knowledge across datasets.
FiP: a Fixed-Point Approach for Causal Generative Modeling
Apr 14, 2024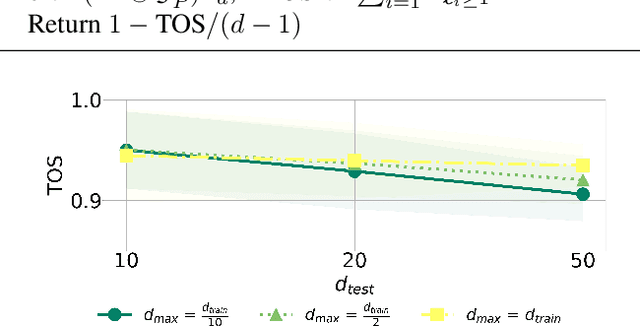



Modeling true world data-generating processes lies at the heart of empirical science. Structural Causal Models (SCMs) and their associated Directed Acyclic Graphs (DAGs) provide an increasingly popular answer to such problems by defining the causal generative process that transforms random noise into observations. However, learning them from observational data poses an ill-posed and NP-hard inverse problem in general. In this work, we propose a new and equivalent formalism that does not require DAGs to describe them, viewed as fixed-point problems on the causally ordered variables, and we show three important cases where they can be uniquely recovered given the topological ordering (TO). To the best of our knowledge, we obtain the weakest conditions for their recovery when TO is known. Based on this, we design a two-stage causal generative model that first infers the causal order from observations in a zero-shot manner, thus by-passing the search, and then learns the generative fixed-point SCM on the ordered variables. To infer TOs from observations, we propose to amortize the learning of TOs on generated datasets by sequentially predicting the leaves of graphs seen during training. To learn fixed-point SCMs, we design a transformer-based architecture that exploits a new attention mechanism enabling the modeling of causal structures, and show that this parameterization is consistent with our formalism. Finally, we conduct an extensive evaluation of each method individually, and show that when combined, our model outperforms various baselines on generated out-of-distribution problems.
The Essential Role of Causality in Foundation World Models for Embodied AI
Feb 06, 2024
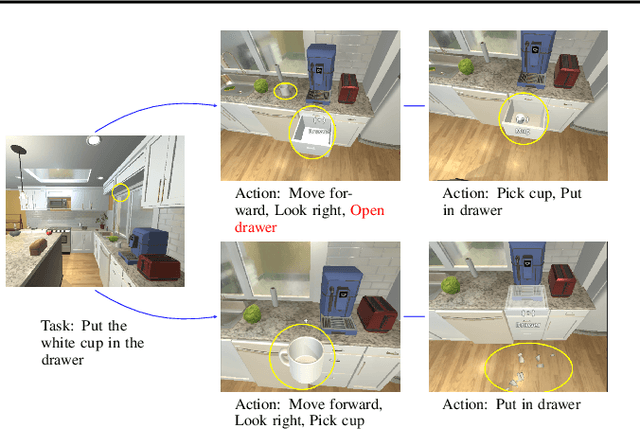
Recent advances in foundation models, especially in large multi-modal models and conversational agents, have ignited interest in the potential of generally capable embodied agents. Such agents would require the ability to perform new tasks in many different real-world environments. However, current foundation models fail to accurately model physical interactions with the real world thus not sufficient for Embodied AI. The study of causality lends itself to the construction of veridical world models, which are crucial for accurately predicting the outcomes of possible interactions. This paper focuses on the prospects of building foundation world models for the upcoming generation of embodied agents and presents a novel viewpoint on the significance of causality within these. We posit that integrating causal considerations is vital to facilitate meaningful physical interactions with the world. Finally, we demystify misconceptions about causality in this context and present our outlook for future research.
Learned Causal Method Prediction
Nov 08, 2023



For a given causal question, it is important to efficiently decide which causal inference method to use for a given dataset. This is challenging because causal methods typically rely on complex and difficult-to-verify assumptions, and cross-validation is not applicable since ground truth causal quantities are unobserved. In this work, we propose CAusal Method Predictor (CAMP), a framework for predicting the best method for a given dataset. To this end, we generate datasets from a diverse set of synthetic causal models, score the candidate methods, and train a model to directly predict the highest-scoring method for that dataset. Next, by formulating a self-supervised pre-training objective centered on dataset assumptions relevant for causal inference, we significantly reduce the need for costly labeled data and enhance training efficiency. Our strategy learns to map implicit dataset properties to the best method in a data-driven manner. In our experiments, we focus on method prediction for causal discovery. CAMP outperforms selecting any individual candidate method and demonstrates promising generalization to unseen semi-synthetic and real-world benchmarks.
Understanding Causality with Large Language Models: Feasibility and Opportunities
Apr 11, 2023
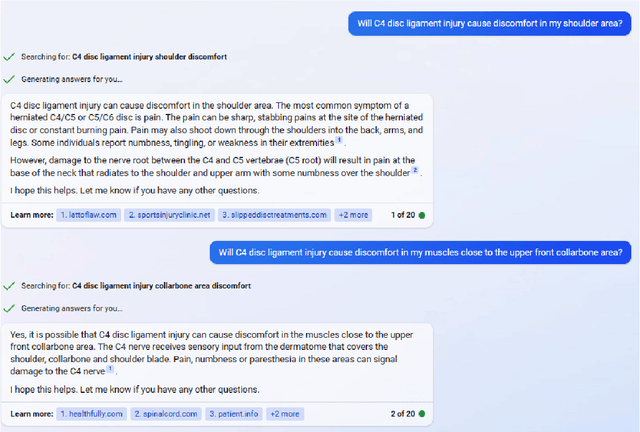
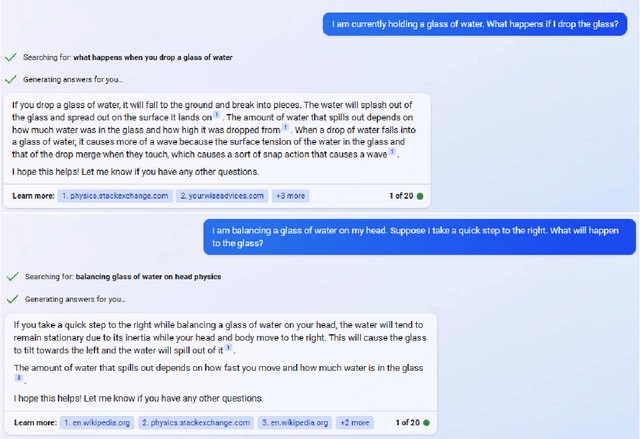
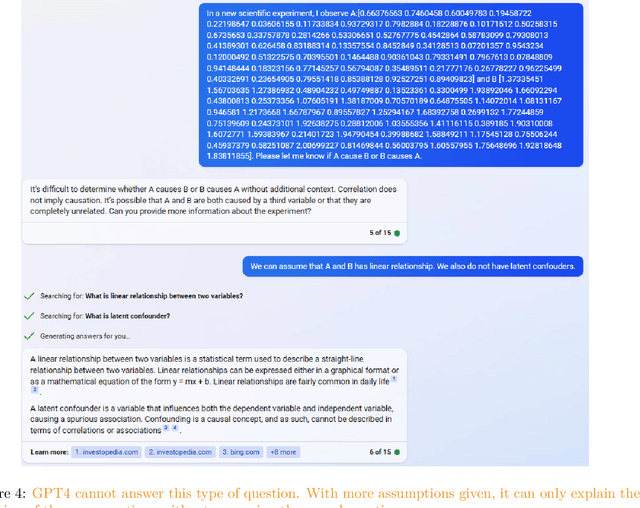
We assess the ability of large language models (LLMs) to answer causal questions by analyzing their strengths and weaknesses against three types of causal question. We believe that current LLMs can answer causal questions with existing causal knowledge as combined domain experts. However, they are not yet able to provide satisfactory answers for discovering new knowledge or for high-stakes decision-making tasks with high precision. We discuss possible future directions and opportunities, such as enabling explicit and implicit causal modules as well as deep causal-aware LLMs. These will not only enable LLMs to answer many different types of causal questions for greater impact but also enable LLMs to be more trustworthy and efficient in general.
Causal Reasoning in the Presence of Latent Confounders via Neural ADMG Learning
Mar 22, 2023Latent confounding has been a long-standing obstacle for causal reasoning from observational data. One popular approach is to model the data using acyclic directed mixed graphs (ADMGs), which describe ancestral relations between variables using directed and bidirected edges. However, existing methods using ADMGs are based on either linear functional assumptions or a discrete search that is complicated to use and lacks computational tractability for large datasets. In this work, we further extend the existing body of work and develop a novel gradient-based approach to learning an ADMG with non-linear functional relations from observational data. We first show that the presence of latent confounding is identifiable under the assumptions of bow-free ADMGs with non-linear additive noise models. With this insight, we propose a novel neural causal model based on autoregressive flows for ADMG learning. This not only enables us to determine complex causal structural relationships behind the data in the presence of latent confounding, but also estimate their functional relationships (hence treatment effects) simultaneously. We further validate our approach via experiments on both synthetic and real-world datasets, and demonstrate the competitive performance against relevant baselines.
Scaling Federated Learning for Fine-tuning of Large Language Models
Feb 01, 2021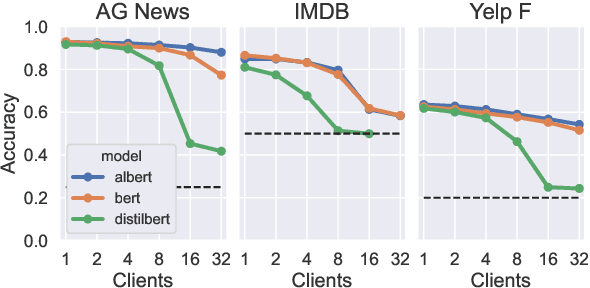
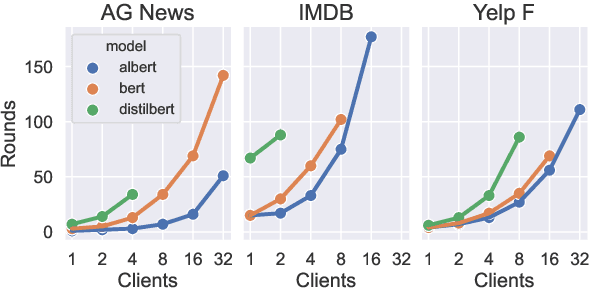
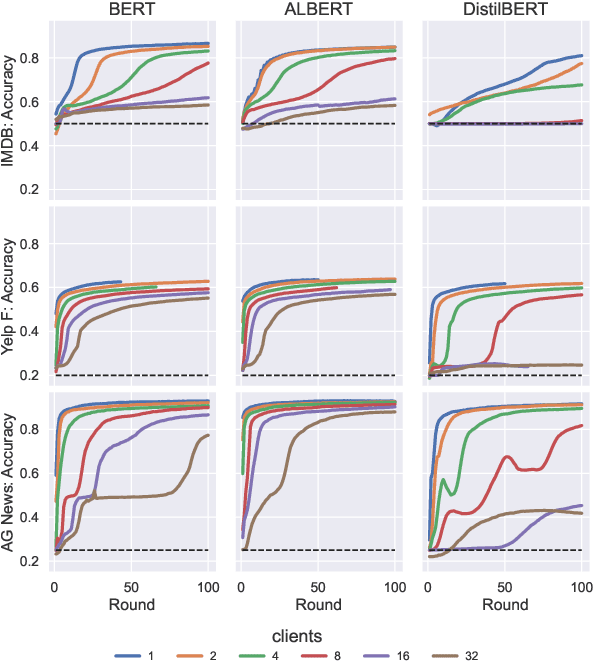
Federated learning (FL) is a promising approach to distributed compute, as well as distributed data, and provides a level of privacy and compliance to legal frameworks. This makes FL attractive for both consumer and healthcare applications. While the area is actively being explored, few studies have examined FL in the context of larger language models and there is a lack of comprehensive reviews of robustness across tasks, architectures, numbers of clients, and other relevant factors. In this paper, we explore the fine-tuning of Transformer-based language models in a federated learning setting. We evaluate three popular BERT-variants of different sizes (BERT, ALBERT, and DistilBERT) on a number of text classification tasks such as sentiment analysis and author identification. We perform an extensive sweep over the number of clients, ranging up to 32, to evaluate the impact of distributed compute on task performance in the federated averaging setting. While our findings suggest that the large sizes of the evaluated models are not generally prohibitive to federated training, we found that the different models handle federated averaging to a varying degree. Most notably, DistilBERT converges significantly slower with larger numbers of clients, and under some circumstances, even collapses to chance level performance. Investigating this issue presents an interesting perspective for future research.
Perceiving Music Quality with GANs
Jun 11, 2020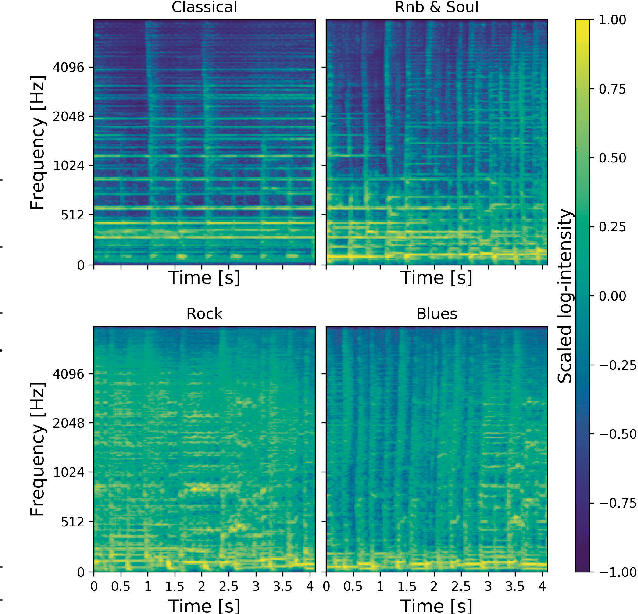
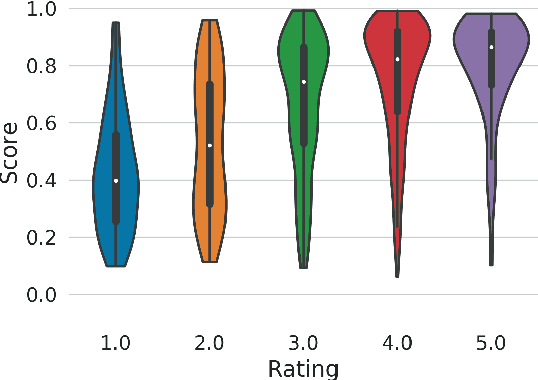
Assessing perceptual quality of musical audio signals usually requires a clean reference signal of unaltered content, hindering applications where a reference is unavailable such as for music generation. We propose training a generative adversarial network on a music library, and using its discriminator as a measure of the perceived quality of music. This method is unsupervised, needs no access to degraded material and can be tuned for various domains of music. Finally, the method is shown to have a statistically significant correlation with human ratings of music.
Towards Machine Learning on data from Professional Cyclists
Aug 01, 2018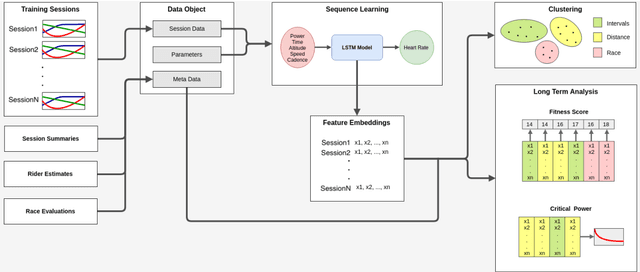
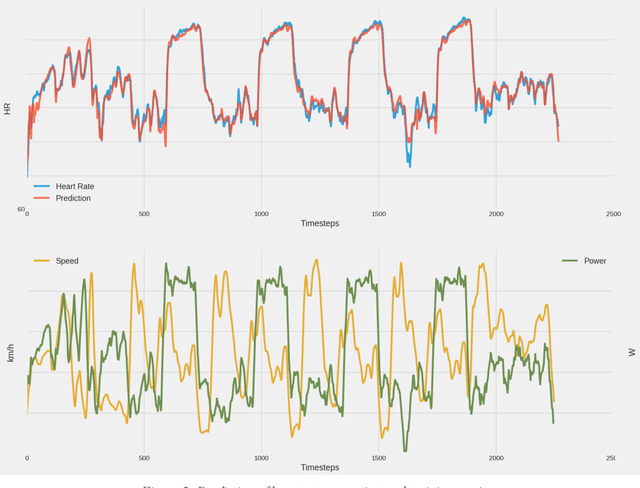
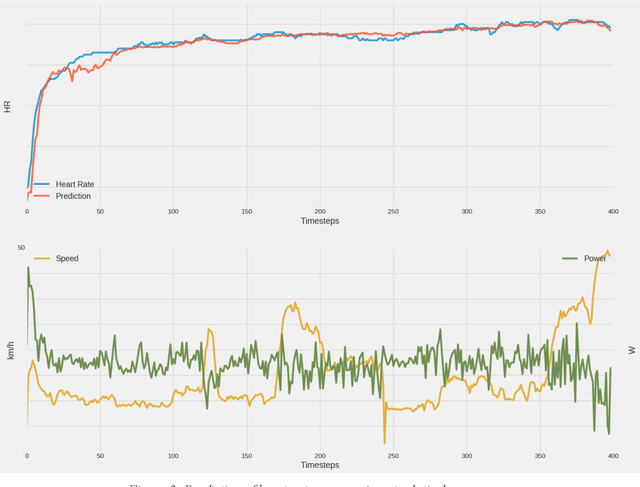
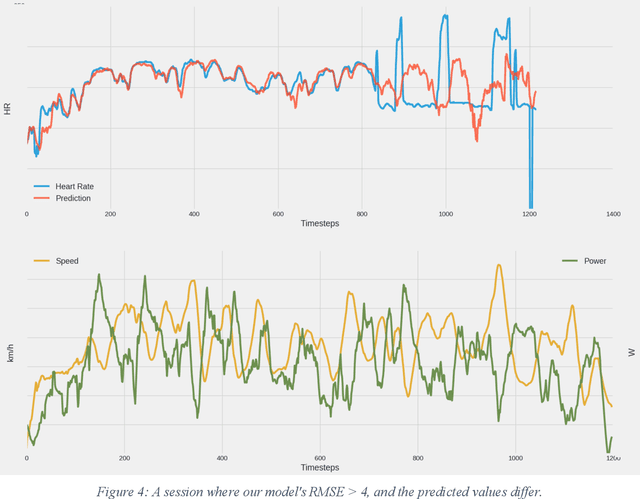
Professional sports are developing towards increasingly scientific training methods with increasing amounts of data being collected from laboratory tests, training sessions and competitions. In cycling, it is standard to equip bicycles with small computers recording data from sensors such as power-meters, in addition to heart-rate, speed, altitude etc. Recently, machine learning techniques have provided huge success in a wide variety of areas where large amounts of data (big data) is available. In this paper, we perform a pilot experiment on machine learning to model physical response in elite cyclists. As a first experiment, we show that it is possible to train a LSTM machine learning algorithm to predict the heart-rate response of a cyclist during a training session. This work is a promising first step towards developing more elaborate models based on big data and machine learning to capture performance aspects of athletes.