 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePyramid Vector Quantization for LLMs
Oct 22, 2024


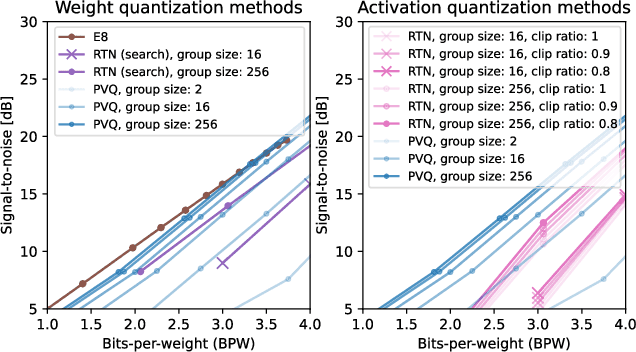
Recent works on compression of large language models (LLM) using quantization considered reparameterizing the architecture such that weights are distributed on the sphere. This demonstratively improves the ability to quantize by increasing the mathematical notion of coherence, resulting in fewer weight outliers without affecting the network output. In this work, we aim to further exploit this spherical geometry of the weights when performing quantization by considering Pyramid Vector Quantization (PVQ) for large language models. Arranging points evenly on the sphere is notoriously difficult, especially in high dimensions, and in case approximate solutions exists, representing points explicitly in a codebook is typically not feasible due to its additional memory cost. Instead, PVQ uses a fixed integer lattice on the sphere by projecting points onto the 1-sphere, which allows for efficient encoding and decoding without requiring an explicit codebook in memory. To obtain a practical algorithm, we propose to combine PVQ with scale quantization for which we derive theoretically optimal quantizations, under empirically verified assumptions. Further, we extend pyramid vector quantization to use Hessian information to minimize quantization error under expected feature activations, instead of only relying on weight magnitudes. Experimentally, we achieves state-of-the-art quantization performance with pareto-optimal trade-off between performance and bits per weight and bits per activation, compared to compared methods. On weight-only, we find that we can quantize a Llama-3 70B model to 3.25 bits per weight and retain 98\% accuracy on downstream tasks.
QuaRot: Outlier-Free 4-Bit Inference in Rotated LLMs
Mar 30, 2024



We introduce QuaRot, a new Quantization scheme based on Rotations, which is able to quantize LLMs end-to-end, including all weights, activations, and KV cache in 4 bits. QuaRot rotates LLMs in a way that removes outliers from the hidden state without changing the output, making quantization easier. This computational invariance is applied to the hidden state (residual) of the LLM, as well as to the activations of the feed-forward components, aspects of the attention mechanism and to the KV cache. The result is a quantized model where all matrix multiplications are performed in 4-bits, without any channels identified for retention in higher precision. Our quantized LLaMa2-70B model has losses of at most 0.29 WikiText-2 perplexity and retains 99% of the zero-shot performance. Code is available at: https://github.com/spcl/QuaRot.
SliceGPT: Compress Large Language Models by Deleting Rows and Columns
Jan 26, 2024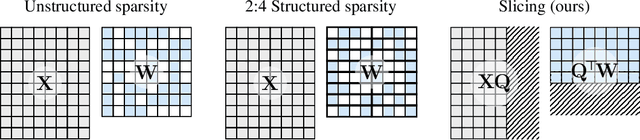
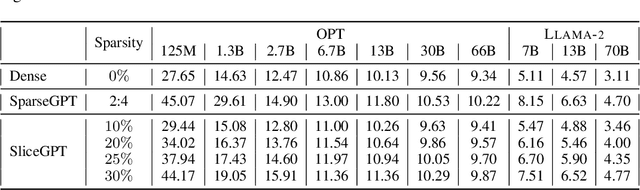

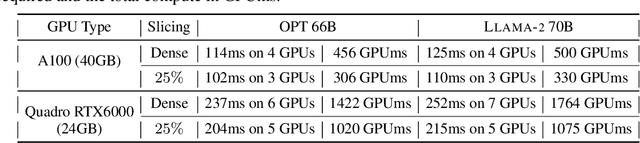
Large language models have become the cornerstone of natural language processing, but their use comes with substantial costs in terms of compute and memory resources. Sparsification provides a solution to alleviate these resource constraints, and recent works have shown that trained models can be sparsified post-hoc. Existing sparsification techniques face challenges as they need additional data structures and offer constrained speedup with current hardware. In this paper we present SliceGPT, a new post-training sparsification scheme which replaces each weight matrix with a smaller (dense) matrix, reducing the embedding dimension of the network. Through extensive experimentation, we show that SliceGPT can remove up to 25% of the model parameters (including embeddings) for LLAMA2-70B, OPT 66B and Phi-2 models while maintaining 99%, 99% and 90% zero-shot task performance of the dense model respectively. Our sliced models run on fewer GPUs and run faster without any additional code optimization: on 24GB consumer GPUs we reduce the total compute for inference on LLAMA2-70B to 64% of that of the dense model; on 40GB A100 GPUs we reduce it to 66%. We offer a new insight, computational invariance in transformer networks, which enables SliceGPT and we hope it will inspire and enable future avenues to reduce memory and computation demands for pre-trained models. Code is available at: https://github.com/microsoft/TransformerCompression
Online parameter inference for the simulation of a Bunsen flame using heteroscedastic Bayesian neural network ensembles
Apr 26, 2021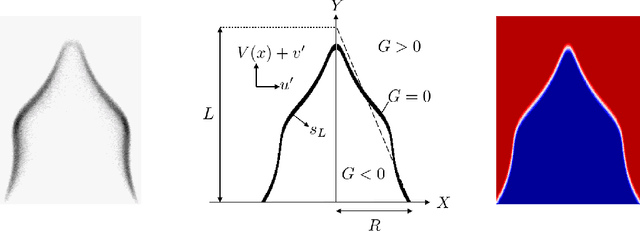
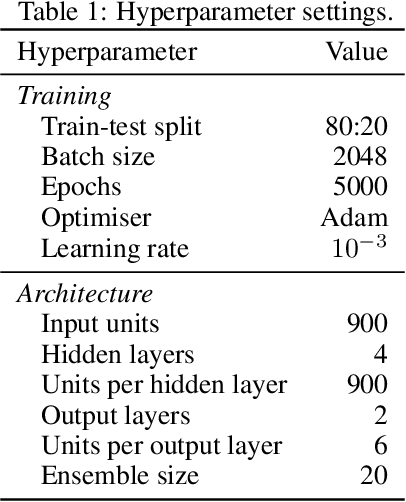
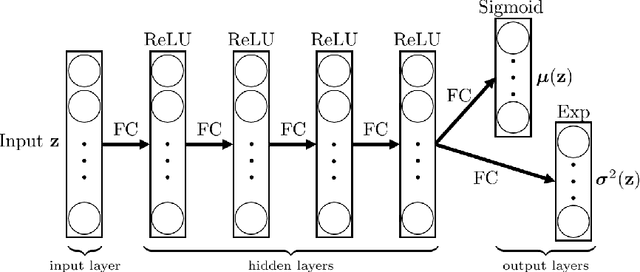
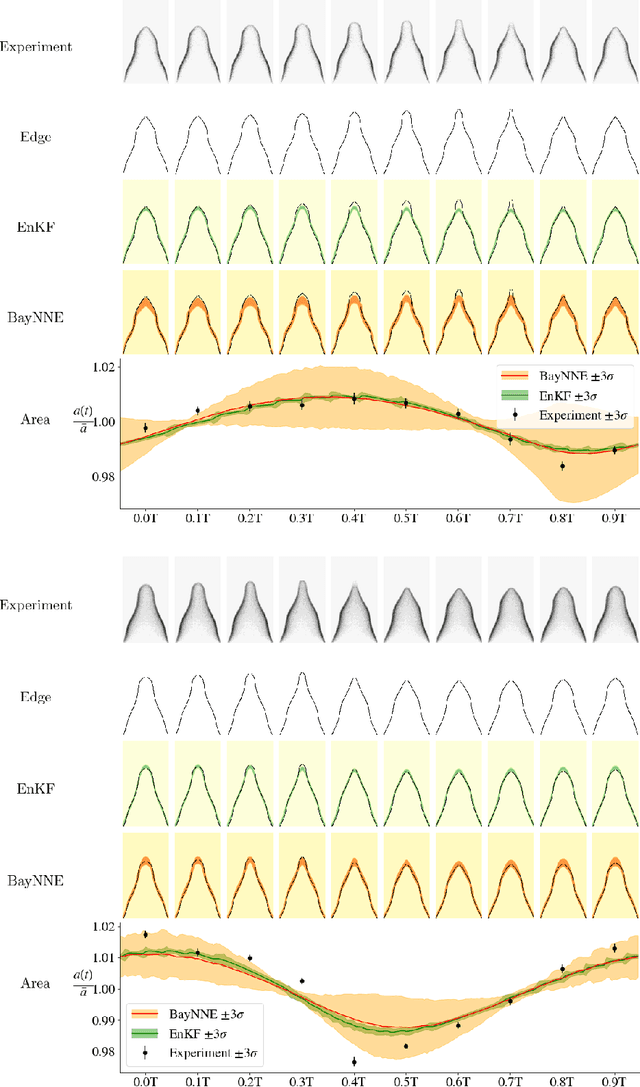
This paper proposes a Bayesian data-driven machine learning method for the online inference of the parameters of a G-equation model of a ducted, premixed flame. Heteroscedastic Bayesian neural network ensembles are trained on a library of 1.7 million flame fronts simulated in LSGEN2D, a G-equation solver, to learn the Bayesian posterior distribution of the model parameters given observations. The ensembles are then used to infer the parameters of Bunsen flame experiments so that the dynamics of these can be simulated in LSGEN2D. This allows the surface area variation of the flame edge, a proxy for the heat release rate, to be calculated. The proposed method provides cheap and online parameter and uncertainty estimates matching results obtained with the ensemble Kalman filter, at less computational cost. This enables fast and reliable simulation of the combustion process.
* 6 pages, 3 figures