 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeech Lattice Vector Quantization for Efficient LLM Compression
Mar 11, 2026Scalar quantization of large language models (LLMs) is fundamentally limited by information-theoretic bounds. While vector quantization (VQ) overcomes these limits by encoding blocks of parameters jointly, practical implementations must avoid the need for expensive lookup mechanisms or other explicit codebook storage. Lattice approaches address this through highly structured and dense packing. This paper explores the Leech lattice, which, with its optimal sphere packing and kissing configurations at 24 dimensions, is the highest dimensional lattice known with such optimal properties. To make the Leech lattice usable for LLM quantization, we extend an existing search algorithm based on the extended Golay code construction, to i) support indexing, enabling conversion to and from bitstrings without materializing the codebook, ii) allow angular search over union of Leech lattice shells, iii) propose fully-parallelisable dequantization kernel. Together this yields a practical algorithm, namely Leech Lattice Vector Quantization (LLVQ). LLVQ delivers state-of-the-art LLM quantization performance, outperforming recent methods such as Quip\#, QTIP, and PVQ. These results highlight the importance of high-dimensional lattices for scalable, theoretically grounded model compression.
Pyramid Vector Quantization for LLMs
Oct 22, 2024


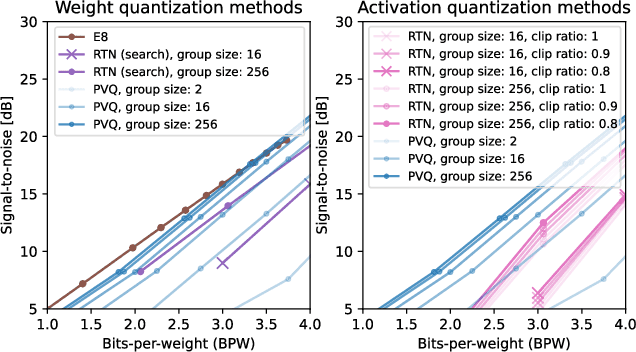
Recent works on compression of large language models (LLM) using quantization considered reparameterizing the architecture such that weights are distributed on the sphere. This demonstratively improves the ability to quantize by increasing the mathematical notion of coherence, resulting in fewer weight outliers without affecting the network output. In this work, we aim to further exploit this spherical geometry of the weights when performing quantization by considering Pyramid Vector Quantization (PVQ) for large language models. Arranging points evenly on the sphere is notoriously difficult, especially in high dimensions, and in case approximate solutions exists, representing points explicitly in a codebook is typically not feasible due to its additional memory cost. Instead, PVQ uses a fixed integer lattice on the sphere by projecting points onto the 1-sphere, which allows for efficient encoding and decoding without requiring an explicit codebook in memory. To obtain a practical algorithm, we propose to combine PVQ with scale quantization for which we derive theoretically optimal quantizations, under empirically verified assumptions. Further, we extend pyramid vector quantization to use Hessian information to minimize quantization error under expected feature activations, instead of only relying on weight magnitudes. Experimentally, we achieves state-of-the-art quantization performance with pareto-optimal trade-off between performance and bits per weight and bits per activation, compared to compared methods. On weight-only, we find that we can quantize a Llama-3 70B model to 3.25 bits per weight and retain 98\% accuracy on downstream tasks.
Noether's razor: Learning Conserved Quantities
Oct 10, 2024Symmetries have proven useful in machine learning models, improving generalisation and overall performance. At the same time, recent advancements in learning dynamical systems rely on modelling the underlying Hamiltonian to guarantee the conservation of energy. These approaches can be connected via a seminal result in mathematical physics: Noether's theorem, which states that symmetries in a dynamical system correspond to conserved quantities. This work uses Noether's theorem to parameterise symmetries as learnable conserved quantities. We then allow conserved quantities and associated symmetries to be learned directly from train data through approximate Bayesian model selection, jointly with the regular training procedure. As training objective, we derive a variational lower bound to the marginal likelihood. The objective automatically embodies an Occam's Razor effect that avoids collapse of conservation laws to the trivial constant, without the need to manually add and tune additional regularisers. We demonstrate a proof-of-principle on $n$-harmonic oscillators and $n$-body systems. We find that our method correctly identifies the correct conserved quantities and U($n$) and SE($n$) symmetry groups, improving overall performance and predictive accuracy on test data.
Variational Inference Failures Under Model Symmetries: Permutation Invariant Posteriors for Bayesian Neural Networks
Aug 10, 2024

Weight space symmetries in neural network architectures, such as permutation symmetries in MLPs, give rise to Bayesian neural network (BNN) posteriors with many equivalent modes. This multimodality poses a challenge for variational inference (VI) techniques, which typically rely on approximating the posterior with a unimodal distribution. In this work, we investigate the impact of weight space permutation symmetries on VI. We demonstrate, both theoretically and empirically, that these symmetries lead to biases in the approximate posterior, which degrade predictive performance and posterior fit if not explicitly accounted for. To mitigate this behavior, we leverage the symmetric structure of the posterior and devise a symmetrization mechanism for constructing permutation invariant variational posteriors. We show that the symmetrized distribution has a strictly better fit to the true posterior, and that it can be trained using the original ELBO objective with a modified KL regularization term. We demonstrate experimentally that our approach mitigates the aforementioned biases and results in improved predictions and a higher ELBO.
The LLM Surgeon
Dec 28, 2023State-of-the-art language models are becoming increasingly large in an effort to achieve the highest performance on large corpora of available textual data. However, the sheer size of the Transformer architectures makes it difficult to deploy models within computational, environmental or device-specific constraints. We explore data-driven compression of existing pretrained models as an alternative to training smaller models from scratch. To do so, we scale Kronecker-factored curvature approximations of the target loss landscape to large language models. In doing so, we can compute both the dynamic allocation of structures that can be removed as well as updates of remaining weights that account for the removal. We provide a general framework for unstructured, semi-structured and structured pruning and improve upon weight updates to capture more correlations between weights, while remaining computationally efficient. Experimentally, our method can prune rows and columns from a range of OPT models and Llamav2-7B by 20%-30%, with a negligible loss in performance, and achieve state-of-the-art results in unstructured and semi-structured pruning of large language models.
Learning Layer-wise Equivariances Automatically using Gradients
Oct 09, 2023Convolutions encode equivariance symmetries into neural networks leading to better generalisation performance. However, symmetries provide fixed hard constraints on the functions a network can represent, need to be specified in advance, and can not be adapted. Our goal is to allow flexible symmetry constraints that can automatically be learned from data using gradients. Learning symmetry and associated weight connectivity structures from scratch is difficult for two reasons. First, it requires efficient and flexible parameterisations of layer-wise equivariances. Secondly, symmetries act as constraints and are therefore not encouraged by training losses measuring data fit. To overcome these challenges, we improve parameterisations of soft equivariance and learn the amount of equivariance in layers by optimising the marginal likelihood, estimated using differentiable Laplace approximations. The objective balances data fit and model complexity enabling layer-wise symmetry discovery in deep networks. We demonstrate the ability to automatically learn layer-wise equivariances on image classification tasks, achieving equivalent or improved performance over baselines with hard-coded symmetry.
Stochastic Marginal Likelihood Gradients using Neural Tangent Kernels
Jun 06, 2023Selecting hyperparameters in deep learning greatly impacts its effectiveness but requires manual effort and expertise. Recent works show that Bayesian model selection with Laplace approximations can allow to optimize such hyperparameters just like standard neural network parameters using gradients and on the training data. However, estimating a single hyperparameter gradient requires a pass through the entire dataset, limiting the scalability of such algorithms. In this work, we overcome this issue by introducing lower bounds to the linearized Laplace approximation of the marginal likelihood. In contrast to previous estimators, these bounds are amenable to stochastic-gradient-based optimization and allow to trade off estimation accuracy against computational complexity. We derive them using the function-space form of the linearized Laplace, which can be estimated using the neural tangent kernel. Experimentally, we show that the estimators can significantly accelerate gradient-based hyperparameter optimization.
Relaxing Equivariance Constraints with Non-stationary Continuous Filters
Apr 14, 2022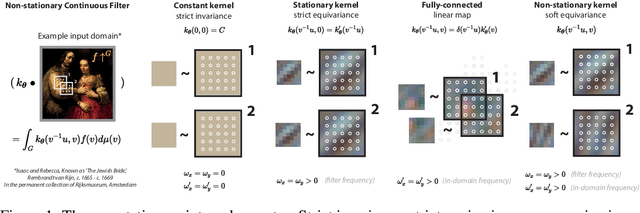
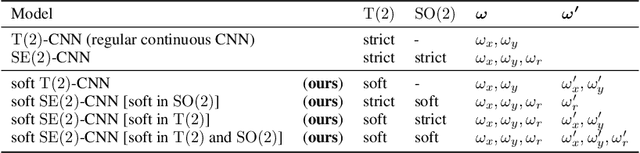
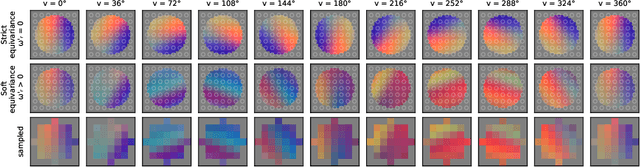
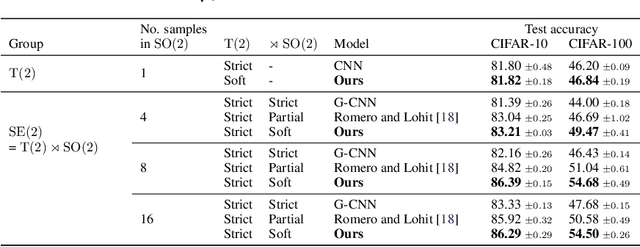
Equivariances provide useful inductive biases in neural network modeling, with the translation equivariance of convolutional neural networks being a canonical example. Equivariances can be embedded in architectures through weight-sharing and place symmetry constraints on the functions a neural network can represent. The type of symmetry is typically fixed and has to be chosen in advance. Although some tasks are inherently equivariant, many tasks do not strictly follow such symmetries. In such cases, equivariance constraints can be overly restrictive. In this work, we propose a parameter-efficient relaxation of equivariance that can effectively interpolate between a (i) non-equivariant linear product, (ii) a strict-equivariant convolution, and (iii) a strictly-invariant mapping. The proposed parameterization can be thought of as a building block to allow adjustable symmetry structure in neural networks. Compared to non-equivariant or strict-equivariant baselines, we experimentally verify that soft equivariance leads to improved performance in terms of test accuracy on CIFAR-10 and CIFAR-100 image classification tasks.
Learning Invariant Weights in Neural Networks
Feb 25, 2022
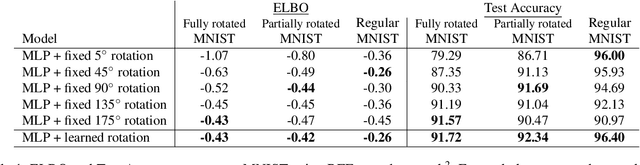
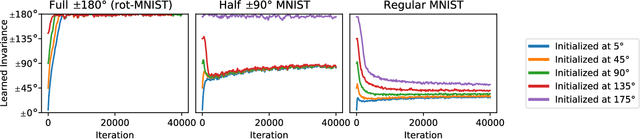
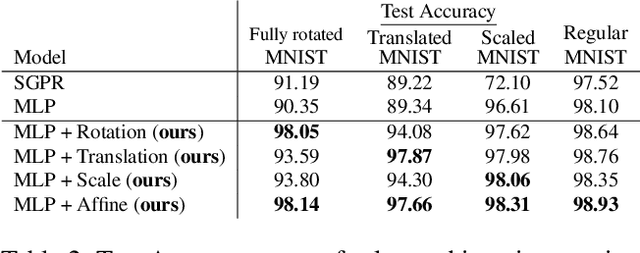
Assumptions about invariances or symmetries in data can significantly increase the predictive power of statistical models. Many commonly used models in machine learning are constraint to respect certain symmetries in the data, such as translation equivariance in convolutional neural networks, and incorporation of new symmetry types is actively being studied. Yet, efforts to learn such invariances from the data itself remains an open research problem. It has been shown that marginal likelihood offers a principled way to learn invariances in Gaussian Processes. We propose a weight-space equivalent to this approach, by minimizing a lower bound on the marginal likelihood to learn invariances in neural networks resulting in naturally higher performing models.
Invariance Learning in Deep Neural Networks with Differentiable Laplace Approximations
Feb 22, 2022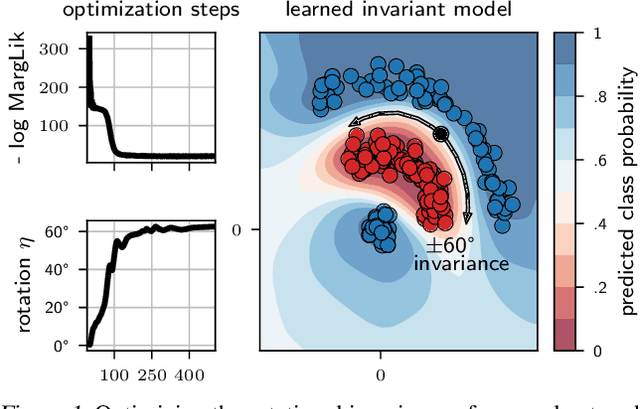
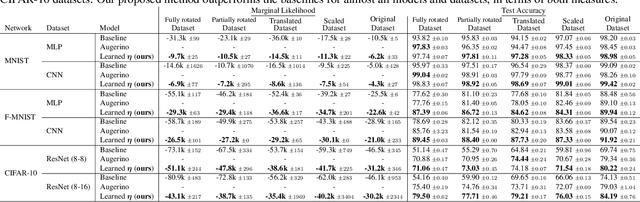
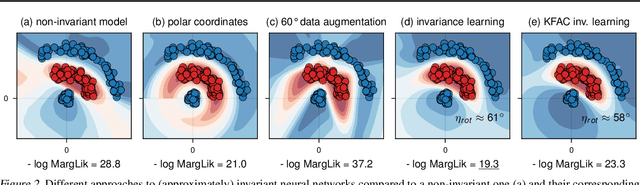

Data augmentation is commonly applied to improve performance of deep learning by enforcing the knowledge that certain transformations on the input preserve the output. Currently, the correct data augmentation is chosen by human effort and costly cross-validation, which makes it cumbersome to apply to new datasets. We develop a convenient gradient-based method for selecting the data augmentation. Our approach relies on phrasing data augmentation as an invariance in the prior distribution and learning it using Bayesian model selection, which has been shown to work in Gaussian processes, but not yet for deep neural networks. We use a differentiable Kronecker-factored Laplace approximation to the marginal likelihood as our objective, which can be optimised without human supervision or validation data. We show that our method can successfully recover invariances present in the data, and that this improves generalisation on image datasets.