 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-Phase Cross-Modal Contrastive Learning for CMR-Guided ECG Representations for Cardiovascular Disease Assessment
Feb 13, 2026Cardiac magnetic resonance imaging (CMR) offers detailed evaluation of cardiac structure and function, but its limited accessibility restricts use to selected patient populations. In contrast, the electrocardiogram (ECG) is ubiquitous and inexpensive, and provides rich information on cardiac electrical activity and rhythm, yet offers limited insight into underlying cardiac structure and mechanical function. To address this, we introduce a contrastive learning framework that improves the extraction of clinically relevant cardiac phenotypes from ECG by learning from paired ECG-CMR data. Our approach aligns ECG representations with 3D CMR volumes at end-diastole (ED) and end-systole (ES), with a dual-phase contrastive loss to anchor each ECG jointly with both cardiac phases in a shared latent space. Unlike prior methods limited to 2D CMR representations with or without a temporal component, our framework models 3D anatomy at both ED and ES phases as distinct latent representations, enabling flexible disentanglement of structural and functional cardiac properties. Using over 34,000 ECG-CMR pairs from the UK Biobank, we demonstrate improved extraction of image-derived phenotypes from ECG, particularly for functional parameters ($\uparrow$ 9.2\%), while improvements in clinical outcome prediction remained modest ($\uparrow$ 0.7\%). This strategy could enable scalable and cost-effective extraction of image-derived traits from ECG. The code for this research is publicly available.
Synthesis of Late Gadolinium Enhancement Images via Implicit Neural Representations for Cardiac Scar Segmentation
Feb 12, 2026Late gadolinium enhancement (LGE) imaging is the clinical standard for myocardial scar assessment, but limited annotated datasets hinder the development of automated segmentation methods. We propose a novel framework that synthesises both LGE images and their corresponding segmentation masks using implicit neural representations (INRs) combined with denoising diffusion models. Our approach first trains INRs to capture continuous spatial representations of LGE data and associated myocardium and fibrosis masks. These INRs are then compressed into compact latent embeddings, preserving essential anatomical information. A diffusion model operates on this latent space to generate new representations, which are decoded into synthetic LGE images with anatomically consistent segmentation masks. Experiments on 133 cardiac MRI scans suggest that augmenting training data with 200 synthetic volumes contributes to improved fibrosis segmentation performance, with the Dice score showing an increase from 0.509 to 0.524. Our approach provides an annotation-free method to help mitigate data scarcity.The code for this research is publicly available.
Fighting MRI Anisotropy: Learning Multiple Cardiac Shapes From a Single Implicit Neural Representation
Feb 11, 2026The anisotropic nature of short-axis (SAX) cardiovascular magnetic resonance imaging (CMRI) limits cardiac shape analysis. To address this, we propose to leverage near-isotropic, higher resolution computed tomography angiography (CTA) data of the heart. We use this data to train a single neural implicit function to jointly represent cardiac shapes from CMRI at any resolution. We evaluate the method for the reconstruction of right ventricle (RV) and myocardium (MYO), where MYO simultaneously models endocardial and epicardial left-ventricle surfaces. Since high-resolution SAX reference segmentations are unavailable, we evaluate performance by extracting a 4-chamber (4CH) slice of RV and MYO from their reconstructed shapes. When compared with the reference 4CH segmentation masks from CMRI, our method achieved a Dice similarity coefficient of 0.91 $\pm$ 0.07 and 0.75 $\pm$ 0.13, and a Hausdorff distance of 6.21 $\pm$ 3.97 mm and 7.53 $\pm$ 5.13 mm for RV and MYO, respectively. Quantitative and qualitative assessment demonstrate the model's ability to reconstruct accurate, smooth and anatomically plausible shapes, supporting improvements in cardiac shape analysis.
Neural Implicit 3D Cardiac Shape Reconstruction from Sparse CT Angiography Slices Mimicking 2D Transthoracic Echocardiography Views
Feb 05, 2026Accurate 3D representations of cardiac structures allow quantitative analysis of anatomy and function. In this work, we propose a method for reconstructing complete 3D cardiac shapes from segmentations of sparse planes in CT angiography (CTA) for application in 2D transthoracic echocardiography (TTE). Our method uses a neural implicit function to reconstruct the 3D shape of the cardiac chambers and left-ventricle myocardium from sparse CTA planes. To investigate the feasibility of achieving 3D reconstruction from 2D TTE, we select planes that mimic the standard apical 2D TTE views. During training, a multi-layer perceptron learns shape priors from 3D segmentations of the target structures in CTA. At test time, the network reconstructs 3D cardiac shapes from segmentations of TTE-mimicking CTA planes by jointly optimizing the latent code and the rigid transforms that map the observed planes into 3D space. For each heart, we simulate four realistic apical views, and we compare reconstructed multi-class volumes with the reference CTA volumes. On a held-out set of CTA segmentations, our approach achieves an average Dice coefficient of 0.86 $\pm$ 0.04 across all structures. Our method also achieves markedly lower volume errors than the clinical standard, Simpson's biplane rule: 4.88 $\pm$ 4.26 mL vs. 8.14 $\pm$ 6.04 mL, respectively, for the left ventricle; and 6.40 $\pm$ 7.37 mL vs. 37.76 $\pm$ 22.96 mL, respectively, for the left atrium. This suggests that our approach offers a viable route to more accurate 3D chamber quantification in 2D transthoracic echocardiography.
Temporally Consistent Mitral Annulus Measurements from Sparse Annotations in Echocardiographic Videos
Mar 15, 2025This work presents a novel approach to achieving temporally consistent mitral annulus landmark localization in echocardiography videos using sparse annotations. Our method introduces a self-supervised loss term that enforces temporal consistency between neighboring frames, which smooths the position of landmarks and enhances measurement accuracy over time. Additionally, we incorporate realistic field-of-view augmentations to improve the recognition of missing anatomical landmarks. We evaluate our approach on both a public and private dataset, and demonstrate significant improvements in Mitral Annular Plane Systolic Excursion (MAPSE) calculations and overall landmark tracking stability. The method achieves a mean absolute MAPSE error of 1.81 $\pm$ 0.14 mm, an annulus size error of 2.46 $\pm$ 0.31 mm, and a landmark localization error of 2.48 $\pm$ 0.07 mm. Finally, it achieves a 0.99 ROC-AUC for recognition of missing landmarks.
Attenuation artifact detection and severity classification in intracoronary OCT using mixed image representations
Mar 07, 2025In intracoronary optical coherence tomography (OCT), blood residues and gas bubbles cause attenuation artifacts that can obscure critical vessel structures. The presence and severity of these artifacts may warrant re-acquisition, prolonging procedure time and increasing use of contrast agent. Accurate detection of these artifacts can guide targeted re-acquisition, reducing the amount of repeated scans needed to achieve diagnostically viable images. However, the highly heterogeneous appearance of these artifacts poses a challenge for the automated detection of the affected image regions. To enable automatic detection of the attenuation artifacts caused by blood residues and gas bubbles based on their severity, we propose a convolutional neural network that performs classification of the attenuation lines (A-lines) into three classes: no artifact, mild artifact and severe artifact. Our model extracts and merges features from OCT images in both Cartesian and polar coordinates, where each column of the image represents an A-line. Our method detects the presence of attenuation artifacts in OCT frames reaching F-scores of 0.77 and 0.94 for mild and severe artifacts, respectively. The inference time over a full OCT scan is approximately 6 seconds. Our experiments show that analysis of images represented in both Cartesian and polar coordinate systems outperforms the analysis in polar coordinates only, suggesting that these representations contain complementary features. This work lays the foundation for automated artifact assessment and image acquisition guidance in intracoronary OCT imaging.
Classifier-guided registration of coronary CT angiography and intravascular ultrasound
Dec 22, 2024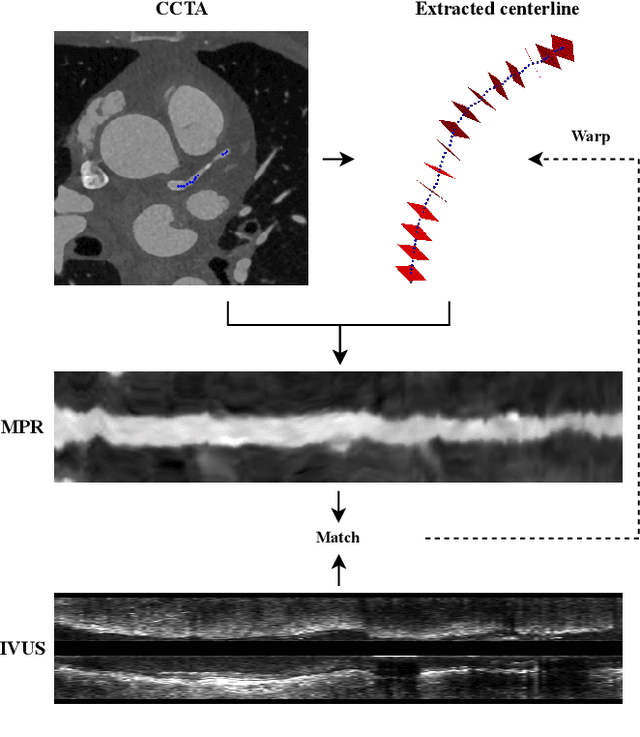
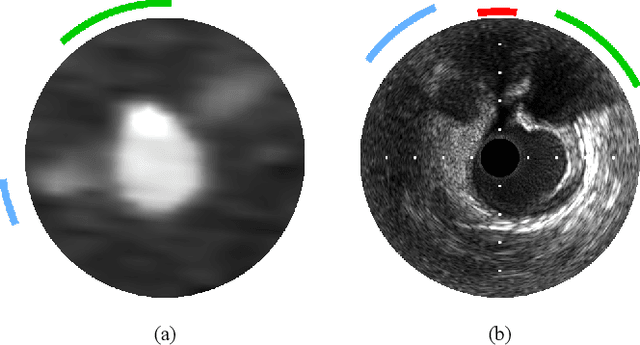
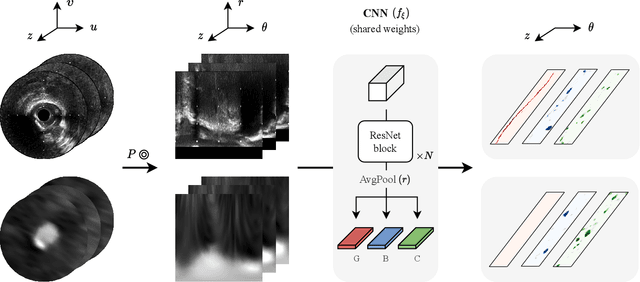
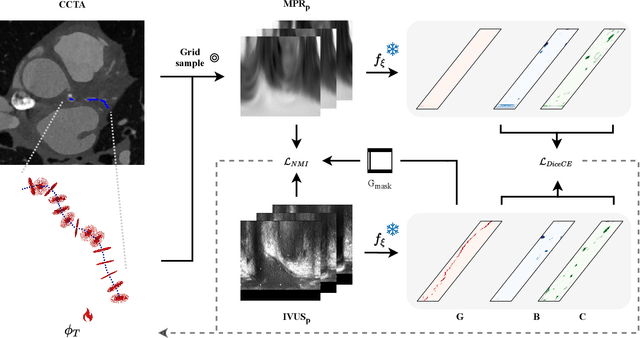
Coronary CT angiography (CCTA) and intravascular ultrasound (IVUS) provide complementary information for coronary artery disease assessment, making their registration valuable for comprehensive analysis. However, existing registration methods require manual interaction or extensive segmentations, limiting their practical application. In this work, we present a fully automatic framework for CCTA-IVUS registration using deep learning-based feature detection and a differentiable image registration module. Our approach leverages a convolutional neural network trained to identify key anatomical features from polar-transformed multiplanar reformatted CCTA or IVUS data. These detected anatomical featuers subsequently guide a differentiable registration module to optimize transformation parameters of an automatically extracted coronary artery centerline. The method does not require landmark selection or segmentations as input, while accounting for the presence of IVUS guidewire artifacts. Evaluated on 48 clinical cases with reference CCTA centerlines corresponding to IVUS pullback, our method achieved successful registration in 83.3\% of cases, with a median centerline overlap F$_1$-score of 0.982 and median cosine similarities of 0.940 and 0.944 for cross-sectional plane orientation. Our results demonstrate that automatically detected anatomical features can be leveraged for accurate registration. The fully automatic nature of the approach represents a significant step toward streamlined multimodal coronary analysis, potentially facilitating large-scale studies of coronary plaque characteristics across modalities.
Brain age identification from diffusion MRI synergistically predicts neurodegenerative disease
Oct 29, 2024



Estimated brain age from magnetic resonance image (MRI) and its deviation from chronological age can provide early insights into potential neurodegenerative diseases, supporting early detection and implementation of prevention strategies. Diffusion MRI (dMRI), a widely used modality for brain age estimation, presents an opportunity to build an earlier biomarker for neurodegenerative disease prediction because it captures subtle microstructural changes that precede more perceptible macrostructural changes. However, the coexistence of macro- and micro-structural information in dMRI raises the question of whether current dMRI-based brain age estimation models are leveraging the intended microstructural information or if they inadvertently rely on the macrostructural information. To develop a microstructure-specific brain age, we propose a method for brain age identification from dMRI that minimizes the model's use of macrostructural information by non-rigidly registering all images to a standard template. Imaging data from 13,398 participants across 12 datasets were used for the training and evaluation. We compare our brain age models, trained with and without macrostructural information minimized, with an architecturally similar T1-weighted (T1w) MRI-based brain age model and two state-of-the-art T1w MRI-based brain age models that primarily use macrostructural information. We observe difference between our dMRI-based brain age and T1w MRI-based brain age across stages of neurodegeneration, with dMRI-based brain age being older than T1w MRI-based brain age in participants transitioning from cognitively normal (CN) to mild cognitive impairment (MCI), but younger in participants already diagnosed with Alzheimer's disease (AD). Approximately 4 years before MCI diagnosis, dMRI-based brain age yields better performance than T1w MRI-based brain ages in predicting transition from CN to MCI.
World of Forms: Deformable Geometric Templates for One-Shot Surface Meshing in Coronary CT Angiography
Sep 18, 2024Deep learning-based medical image segmentation and surface mesh generation typically involve a sequential pipeline from image to segmentation to meshes, often requiring large training datasets while making limited use of prior geometric knowledge. This may lead to topological inconsistencies and suboptimal performance in low-data regimes. To address these challenges, we propose a data-efficient deep learning method for direct 3D anatomical object surface meshing using geometric priors. Our approach employs a multi-resolution graph neural network that operates on a prior geometric template which is deformed to fit object boundaries of interest. We show how different templates may be used for the different surface meshing targets, and introduce a novel masked autoencoder pretraining strategy for 3D spherical data. The proposed method outperforms nnUNet in a one-shot setting for segmentation of the pericardium, left ventricle (LV) cavity and the LV myocardium. Similarly, the method outperforms other lumen segmentation operating on multi-planar reformatted images. Results further indicate that mesh quality is on par with or improves upon marching cubes post-processing of voxel mask predictions, while remaining flexible in the choice of mesh triangulation prior, thus paving the way for more accurate and topologically consistent 3D medical object surface meshing.
ATOMMIC: An Advanced Toolbox for Multitask Medical Imaging Consistency to facilitate Artificial Intelligence applications from acquisition to analysis in Magnetic Resonance Imaging
Apr 30, 2024


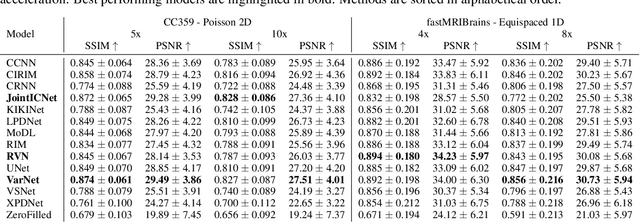
AI is revolutionizing MRI along the acquisition and processing chain. Advanced AI frameworks have been developed to apply AI in various successive tasks, such as image reconstruction, quantitative parameter map estimation, and image segmentation. Existing frameworks are often designed to perform tasks independently or are focused on specific models or datasets, limiting generalization. We introduce ATOMMIC, an open-source toolbox that streamlines AI applications for accelerated MRI reconstruction and analysis. ATOMMIC implements several tasks using DL networks and enables MultiTask Learning (MTL) to perform related tasks integrated, targeting generalization in the MRI domain. We first review the current state of AI frameworks for MRI through a comprehensive literature search and by parsing 12,479 GitHub repositories. We benchmark 25 DL models on eight publicly available datasets to present distinct applications of ATOMMIC on accelerated MRI reconstruction, image segmentation, quantitative parameter map estimation, and joint accelerated MRI reconstruction and image segmentation utilizing MTL. Our findings demonstrate that ATOMMIC is the only MTL framework with harmonized complex-valued and real-valued data support. Evaluations on single tasks show that physics-based models, which enforce data consistency by leveraging the physical properties of MRI, outperform other models in reconstructing highly accelerated acquisitions. Physics-based models that produce high reconstruction quality can accurately estimate quantitative parameter maps. When high-performing reconstruction models are combined with robust segmentation networks utilizing MTL, performance is improved in both tasks. ATOMMIC facilitates MRI reconstruction and analysis by standardizing workflows, enhancing data interoperability, integrating unique features like MTL, and effectively benchmarking DL models.